ЖЕСТЫ И ЭМОЦИИ. РАССКАЗЫВАЕТ АНДРЕЙ САВУШКИН
Фотография говорит с нами беззвучно, но, несмотря на это, мы считываем сюжеты и ситуации, характеры и взаимоотношения персонажей. В этом нам помогают их позы, жесты и выражения лиц. Именно поэтому так интересно рассматривать работы Жерара Юфера на выставке «Один день в музее». Однако есть люди, которые особенно внимательны к жестам и позам – это глухие и слабослышащие, говорящие на жестовом языке. Друг Арсенала и постоянный участник наших инклюзивных проектов Андрей Савушкин разработал маршрут «Жесты и эмоции», в котором расскажет о том, что необычного видит глухой человек на фотографиях Жерара Юфера.
Вступление
Меня зовут Андрей Савушкин, я слабослышащий.
Я представляю маршрут «Жесты и эмоции» на выставке Жерара Юфера «Один день в музее». Это выставка фотографий,и я выбрал самые интересные. Расскажу о кадрах и расскажу, что глухой человек может увидеть на этих фотографиях.
Мы посмотрим на фотографии с точки зрения жестов и эмоций.
А ещё вы узнаете интересные факты о культуре глухих.
В начало
Первая фотография. Знаете, что видит глухой человек на этом фото? Первое, что замечает глухой — солнце. Почему солнце? Всё потому, что глухой смотрит на руки. Раскрытая ладонь — это часть жеста «солнце».
Для глухого человека руки — это особенная важная часть жизни.
Руками можно что-то создавать — рисовать, писать. Но для глухих руки — это язык, возможность общаться с другими людьми. Поэтому мы видим слово «солнце» в раскрытой ладони.
В начало
Пластика движения и рук
Эта фотография мне нравится. Почему? Фотограф очень талантливо показывает пластику человеческих движений, человеческих рук. Здесь пластика статуи и человека рядом очень перекликается друг с другом. Художник поймал красивый момент.
Пластика рук — это то, что очень важно в культуре глухих. Руки — это красиво.
Вы знаете, что глухие поют песни? Как поют? Не голосом, а руками. Мы переводим песни из звучащего языка на жестовый. Подбираются красивые жесты и исполняются в такт музыке.
Мы переводим песни из звучащего языка на жестовый. Подбираются красивые жесты и исполняются в такт музыке.
Если не видели, посмотрите в интернете песни на жестовом языке.
Кстати, если внимательно посмотреть на руки на фото, какие жесты мы можем увидеть? Вот такое положение рук — это жесты, например, «музей», «экскурсия», «реальность», «готовность». Много разных жестов.
В начало
Прикосновение как часть общения
Давайте внимательно посмотрим на это фото.
Это центр Помпиду в Париже. Графическое изображение проецируется на стену. Рядом трое детей — они смотрят на изображение и пытаются его потрогать. Тени падают на их руки и одежду.
Заметили, что в музее люди часто хотят потрогать экспонаты? Этого нельзя делать, но все хотят попробовать прикоснуться, потому что интересно.
Когда мы прикасаемся, мы лучше понимаем, что видим. Прикосновение помогает нам стать частью картины. Для глухого человека прикосновение — это ещё и важная часть общения.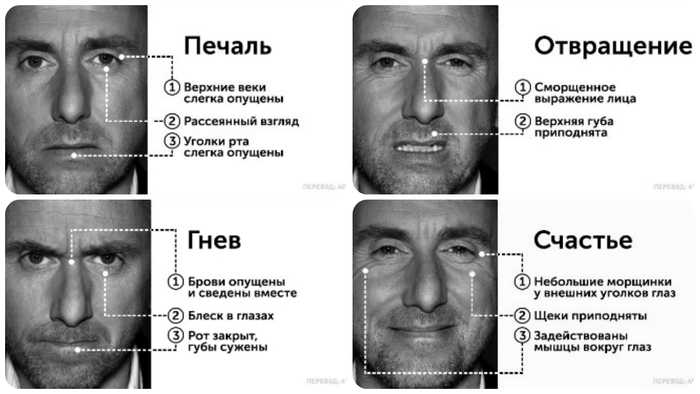
В начало
Две пары
На этой фотографии две пары фигур. Первая — на картине, вторая — стоящие работники музея. Если бы они общались на жестовом языке, что они бы говорили?
Первая пара на картине — это ангелы с картины Филиппа де Шампань «Видение св. Амвросия Медиоланского» (1658). У них широкие высокие жесты. Какие, например, могли бы быть? Свет, блеск, солнце или идея.
Вторая пара — это два сотрудника музея.
Когда ты встречаешься с искусством очень часто, это становится твоей работой, то ты можешь рядом с ним обсуждать свои житейские проблемы. У них жесты ниже и уже. Девушка стоит так, как будто скажет слово: «можно», «нужно», «просто». Рядом широкие и большие жесты на картине и узкие — у работников, интересно.
Фотограф ловит интересные моменты, как сюжеты картин и то, что люди делают в музее, перекликается. Как люди могут вести себя рядом с ангелами и другими экспонатами.
В начало
Встреча с искусством
Посмотрим на фотографию. Девочка прыгает на фоне картины Карел Аппел «Обезглавленный» (1982).
Это очень масштабное полотно с сильным сюжетом и яркими красками. Рядом девочка. Она не сидит и внимательно смотрит на картину, как положено в музее. Она стремительно скачет вдоль полотна.
Я думаю, что это интересно. Встреча с искусством может быть такой — можно двигаться, играть.
В музее не обязательно всегда думать. Иногда мы хотим отдохнуть в тишине, иногда хотим скакать вприпрыжку, чтобы выплеснуть свои чувства.
В начало
Забавная пара
Посмотрим фото — это пара, мужчина и женщина. Все кадры на выставке не постановочные. Фотограф ловил настоящие эмоции и настоящие движения людей. На это интересно смотреть.
Вот эта фотография — здесь забавная пара. Девушка прикасается к затылку парня. Что она хочет сказать своим прикосновением?
Пара находится в центре Помпиду (центр современного искусства в Париже).
Мы не сразу можем понять жест девушки — это может быть попытка привлечь внимание парня или массаж головы для улучшения работы мысли. Много вариантов, а что вы думаете?
В начало
Общение в кругу
Когда мы видим интересное, то внимательно и близко на это смотрим. Что хочет заметить эта девушка?Мне хочется рядом с этой фотографией рассказать об интересной черте культуры глухих: внимательно смотреть на собеседника. Глухой не может во время разговора смотреть в сторону, так как он общается с помощью зрения. Нужно внимательно смотреть на собеседника и общаться.
В культуре глухих есть такая особенность: если собирается много глухих, они всегда встают в круг. В кругу общаться удобно — так все видят друг друга.
Внимательный взгляд помогает нам понять человека рядом и искусство, которое мы видим.
В начало
Смотрите также
К выставке
Жерар Юфера много лет занимается фотожурналистикой и fashion-фотографией, исследует такой важный феномен как музей. На выставке представлено более 100 фоторабот художника.
Невербальные средства общения — ПГУ им. Т.Г. Шевченко
Мы очень часто обращаемся к этому способу передачи информации, общаясь с друзьями, родственниками, деловыми партнерами, сослуживцами и с теми, с кем лишь на мгновение сталкиваемся нас повседневная жизнь. Он во многом определяет как реакцию на окружающих, так и их отношение к нам. Стоит только сознательно отнестись к этим безмолвным сигналам, которые мы одновременно и подаем, и принимаем, как мы тут же откроем для себя возможность более эффективного и действительного их использования.
Согласно исследованиям, 55% сообщений воспринимается через выражение лица, позы и жесты, а 38% — через интонации и модуляции голоса. Отсюда следует, что всего 7% остается словам, воспринимаемым получателем, когда мы говорим.
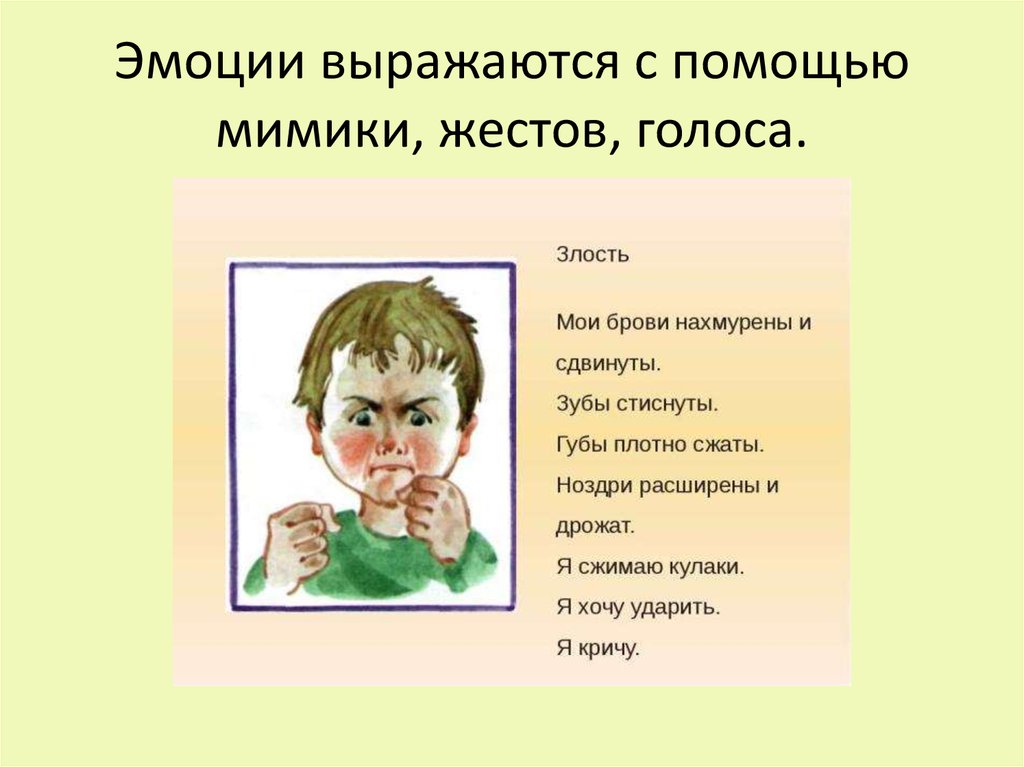
Знать виды невербального общения и понимать невербальные сигналы важно по нескольким причинам. Во-первых, они выполняют функции точного выражения чувств, ведь очень часто мы испытываем чувства настолько сложные, что просто не в состоянии подобрать для их описания нужные слова, но это можно сделать, используя невербальные средства и методы. Во-вторых, они выполняют функции более глубокого взаимопонимания.
Зная основные способы невербального общения, вы сможете лучше понять другого человека, когда он в общении с вами пытается контролировать свое поведение, ведь невербальные сигналы проявляются бессознательно и ваш собеседник просто не может ими управлять. Классификация невербальных средств общения и примеры их использования помогут вам не только лучше понять себя, но и научат распознавать ложь и манипуляции со стороны других людей.
Расширьте свое восприятие
Чтобы, научиться лучше, понимать собеседника и распознавать его скрытые сигналы, для начала следует научиться обращать внимание одновременно на все элементы или средства невербального общения, к ним относятся мимика, жесты, позы, интонация и тембр голоса, визуальный контакт и межличностное пространство.
Мимика
Мимика-это выражение лица человека, она является главным элементом отображением эмоций и чувств. Позитивные эмоции, например, любовь или удивление, распознать намного легче, чем негативные, к которым можно отнести отвращение или гнев. Эмоции по-разному отражаются на правой и левой стороне лица, ведь левое и правое полушарие мозга выполняют разные функции: правое совершает управление эмоциональной сферой, а левое отвечает за интеллектуальные функции.
Эмоции выражаются в мимике таким образом:
- Гнев — широко открытые глаза, опущенные уголки губ, «прищуренный» взгляд, сжатые зубы;
- Удивление – приоткрытый рот, широко открытые глаза и поднятые брови, опущенные кончики губ;
- Страх – сведенные брови, растянутые губы с опушенными и отведенными вниз уголками;
- Счастье – спокойный взгляд, приподнятые, отведенные назад уголки губ;
- Печаль – «угасший» взгляд, опущенные уголки губ, сведенные брови.

Визуальный контакт
Этот метод невербального общения помогает демонстрировать заинтересованность в беседе и лучше понимать смысл сказанного. Во время разговора два человека вместе создают и регулируют степень комфорта, периодически встречаясь взглядом и отводя его в сторону. Пристальный взгляд может, как сформировать доверие, так и породить дискомфорт.
Приятные общие темы поддерживают зрительный контакт, а негативные запутанные вопросы заставляют отводить взгляд в сторону, демонстрируя несогласие и неприязнь.
Особенности визуального контакта позволяют делать выводы о степени заинтересованности в диалоге и отношении к собеседнику:
- Восхищение – долгий зрительный контакт, спокойный взгляд;
- Возмущение – пристальный, навязчивый, несколько тревожный взгляд, длительный зрительный контакт без пауз;
- Расположение – внимательный взгляд, зрительный контакт с паузами каждые 10 секунд;
- Неприязнь – избегание зрительного контакта, «закатывание» глаз.

- Ожидание – резкий взгляд в глаза, приподнятые брови.
Интонация и тембр голоса
Правильно понимать интонацию и тембр голоса означает научиться «читать между строк» послание другого человека. К таким особенностям можно отнести частые паузы, незаконченные предложения и их построение, силу и высоту голоса, а также скорость речи.
- Волнение – низкий тон голоса, быстрая обрывистая речь;
- Усталость – низкий тон голоса, понижение интонации к концу предложения;
- Энтузиазм – высокий тон голоса, четкая уверенная речь;
- Высокомерие – медленная речь, ровная монотонная интонация;
- Неуверенность – ошибки в словах, частые паузы, нервный кашель.
Жесты и позы
Чувства и установки людей можно определить по манере сидеть или стоять, по набору жестов и отдельных движений. Людям легче и приятней общаться с теми, кто обладает экспрессивной моторикой оживленным расслабленным выражением лица. Яркие жесты отображают позитивные эмоции и располагают к искренности и доверию. При этом чрезмерная жестикуляция, часто повторяющиеся жесты могут говорить о внутреннем напряжении и неуверенности в себе.
Яркие жесты отображают позитивные эмоции и располагают к искренности и доверию. При этом чрезмерная жестикуляция, часто повторяющиеся жесты могут говорить о внутреннем напряжении и неуверенности в себе.
Невербальное общение становиться доступным, а уровень взаимопонимания увеличивается, если вы понимаете позы и жесты вашего собеседника.
- Критичность – одна рука возле подбородка с вытянутым указательным пальцем вдоль щеки, вторая рука поддерживает локоть;
- Позитивность – корпус тела, голова немного наклонены вперед, рука немного касается щеки;
- Недоверие – ладонь прикрывает рот, выражая несогласие;
- Скука – голова подперта рукой, корпус расслаблен и немного согнут;
- Превосходство – положение сидя, ноги одна над другой, руки за головой, веки немного прикрыты;
- Неодобрение – неспокойные движения, встряхивание «ворсинок», расправление одежды, одергивание брюк либо юбки;
- Неуверенность – почесывание либо протирание ушей, обхватывание одной рукой локтя другой руки;
- Открытость – руки раскинуты в стороны ладонями вверх, плечи расправлены, голова «смотрит» прямо, корпус расслаблен;
Межличностное пространство
Расстояние между собеседниками играет важную роль в налаживании контакта, понимания ситуации общения. Часто люди выражают свое отношение такими категориями как «держаться оттуда подальше» или «хочу быть ближе к нему». Если люди заинтересованы друг другом, разделяющее их пространство уменьшается, они стремятся находиться поближе. Для лучшего понимания этих особенностей, а также для того, чтобы правильно разграничивать ситуации и рамки контакта, следует знать основные пределы допустимого расстояния между собеседниками:
Часто люди выражают свое отношение такими категориями как «держаться оттуда подальше» или «хочу быть ближе к нему». Если люди заинтересованы друг другом, разделяющее их пространство уменьшается, они стремятся находиться поближе. Для лучшего понимания этих особенностей, а также для того, чтобы правильно разграничивать ситуации и рамки контакта, следует знать основные пределы допустимого расстояния между собеседниками:
Интимное расстояние (до 0,5 м) – интимные доверительные отношения между близкими людьми, друзьями. Также может быть допустимо в спорте, где допустимым является телесное соприкосновение.
Межличностное расстояние (от 0,5м – до 1,2 м) – комфортное расстояние во время дружественной беседы, где допускаются прикосновения друг к другу.
Социальное расстояние (от 1,2м – до 3,7м) – неформальное взаимодействие в социуме, во время деловой встречи. Чем больше расстояние, вплоть до крайней границе, тем отношения формальней.
Публичное расстояние (более 3,7м) – комфортное расстояние для лектора, который совершает публичное выступление перед большой группой людей.
Такие рамки расстояний и их значимость зависит от возраста, пола человека, его личностных особенностей. Детям комфортно находится на более близком расстоянии от собеседника, а подростки закрываются и желают отстраниться от других. Женщины любят более близкие расстояния, независимо от пола их собеседника. Уравновешенные, уверенные в себе люди не обращают особого внимания на расстояние, тогда как нервные тревожные люди стараются находиться в отдалении от других.
Как вербальные языки отличаются друг от друга в зависимости от типа культур, так и невербальный язык одной нации отличается от невербального языка другой нации.
В то время как какой-то жест может быть общепризнанным и иметь четкую интерпретацию у одной нации, у другой нации он может не иметь никакого обозначения или иметь совершенно противоположное значение.
Одной из наиболее серьезных ошибок, которую могут допустить в изучении невербального общения, является стремление выделить один жест и рассматривать его изолированно от других жестов и обстоятельств, поэтому следует помнить, что интерпретировать отдельно взятый жест без совокупности других сигналов тела, значит, ввести себя в заблуждение. Поэтому, прежде чем сделать конкретные выводы, нужно учесть все нюансы поведения собеседника, а также его физическое и психологическое состояние.
Поэтому, прежде чем сделать конкретные выводы, нужно учесть все нюансы поведения собеседника, а также его физическое и психологическое состояние.
Роль жестов рук в передаче эмоций: имеют ли значение тип и размер жестов?
. 2022 27 нояб.
doi: 10.1007/s00426-022-01774-9. Онлайн перед печатью.
Эсма Нур Асалиоглу 1 , Тильбе Гёксун 2
Принадлежности
- 1 Кафедра психологии, Университет Коч, Румелифенери Йолу, Сарыер, 34450, Стамбул, Турция.
- 2 Кафедра психологии, Университет Коч, Румелифенери Йолу, Сарыер, 34450, Стамбул, Турция.
 [email protected].
[email protected].
- PMID: 36436110
- DOI: 10.1007/s00426-022-01774-9
Эсма Нур Асалиоглу и др. Психолог Рез. .
. 2022 27 нояб.
doi: 10.1007/s00426-022-01774-9. Онлайн перед печатью.
Авторы
Эсма Нур Асалиоглу 1 , Тильбе Гёксун 2
Принадлежности
- 1 Кафедра психологии, Университет Коч, Румелифенери Йолу, Сарыер, 34450, Стамбул, Турция.

- 2 Кафедра психологии, Университет Коч, Румелифенери Йолу, Сарыер, 34450, Стамбул, Турция. [email protected].
- PMID: 36436110
- DOI: 10.1007/s00426-022-01774-9
Абстрактный
Мы передаем эмоции мультимодальным способом, однако невербальная передача эмоций является относительно малоизученной областью исследований. В трех экспериментах мы исследовали роль характеристик жестов (например, тип, размер в пространстве) на обработку людьми эмоционального содержания. В эксперименте 1 участников просили оценить эмоциональную интенсивность эмоциональных повествований из видеоклипов либо с помощью знаковых жестов, либо с помощью битов. Участники в состоянии знакового жеста оценили эмоциональную интенсивность выше, чем участники в состоянии битого жеста. В эксперименте 2 размер жестов и его взаимодействие с типом жестов исследовались в рамках внутрисубъектного дизайна. Участники снова оценили эмоциональную насыщенность эмоциональных нарративов из видеороликов. Хотя люди в целом оценивали узкие жесты как более эмоционально интенсивные, чем более широкие жесты, не было обнаружено влияния типа жеста или его размера и типа взаимодействия. Эксперимент 3 был проведен, чтобы проверить, связаны ли результаты эксперимента 2 с просмотром жестов во всех видеоклипах. Мы сравнили условия жеста и отсутствия жеста (т. е. только речь) и показали, что между ними нет разницы в эмоциональных оценках. Однако мы не смогли воспроизвести результаты эксперимента 2, связанные с размером жеста. В целом, эти результаты указывают на важность изучения роли жестов в эмоциональном контексте и на то, что различные характеристики жестов, такие как размер жестов, могут учитываться в невербальной коммуникации.
Участники в состоянии знакового жеста оценили эмоциональную интенсивность выше, чем участники в состоянии битого жеста. В эксперименте 2 размер жестов и его взаимодействие с типом жестов исследовались в рамках внутрисубъектного дизайна. Участники снова оценили эмоциональную насыщенность эмоциональных нарративов из видеороликов. Хотя люди в целом оценивали узкие жесты как более эмоционально интенсивные, чем более широкие жесты, не было обнаружено влияния типа жеста или его размера и типа взаимодействия. Эксперимент 3 был проведен, чтобы проверить, связаны ли результаты эксперимента 2 с просмотром жестов во всех видеоклипах. Мы сравнили условия жеста и отсутствия жеста (т. е. только речь) и показали, что между ними нет разницы в эмоциональных оценках. Однако мы не смогли воспроизвести результаты эксперимента 2, связанные с размером жеста. В целом, эти результаты указывают на важность изучения роли жестов в эмоциональном контексте и на то, что различные характеристики жестов, такие как размер жестов, могут учитываться в невербальной коммуникации.
© 2022. Автор(ы) по эксклюзивной лицензии Springer-Verlag GmbH Germany, часть Springer Nature.
Похожие статьи
Использование жестов в турецком языке L1 и английском языке L2: данные эмоциональных пересказов повествования.
Эмир Оздер Л., Озер Д., Гёксун Т. Эмир Оздер Л. и др. Q J Exp Psychol (Хоув). 2022 Окт 7:17470218221126685. дои: 10.1177/17470218221126685. Онлайн перед печатью. Q J Exp Psychol (Хоув). 2022. PMID: 36073978
I tawt i taw a puddy tat: жесты в повествованиях о канареечном ряду высокофункциональной молодежи с расстройством аутистического спектра.
Сильверман Л.Б., Эйгсти И.М., Беннетто Л. Сильверман Л.Б. и соавт.
 Аутизм рез. 2017 авг;10(8):1353-1363. doi: 10.1002/aur.1785. Epub 2017 1 апр.
Аутизм рез. 2017.
PMID: 28371492
Аутизм рез. 2017 авг;10(8):1353-1363. doi: 10.1002/aur.1785. Epub 2017 1 апр.
Аутизм рез. 2017.
PMID: 28371492Помощь в рассказывании историй: влияние жестов на понимание повествования смягчается сложностью задачи и когнитивными способностями.
МакКерн Н., Дарг Н., Свеллер Н., Секин К., Остин Э. МакКерн Н. и соавт. Q J Exp Psychol (Хоув). 2021 окт;74(10):1791-1805. дои: 10.1177/17470218211024913. Epub 2021 17 июня. Q J Exp Psychol (Хоув). 2021. PMID: 34049468
Роль жестов в разговоре, обучении и создании языка.
Голдин-Медоу С., Алибали М.В. Голдин-Медоу С. и др. Анну Рев Психол. 2013;64:257-83. doi: 10.1146/annurev-psych-113011-143802. Epub 2012 25 июля.
 Анну Рев Психол. 2013.
PMID: 22830562
Бесплатная статья ЧВК.
Обзор.
Анну Рев Психол. 2013.
PMID: 22830562
Бесплатная статья ЧВК.
Обзор.Жесты, общение и потеря слуха у взрослых.
Воробей К., Линд К., ван Стенбрюгге В. Воробей К. и др. J Коммунальное расстройство. 2020 сен-октябрь;87:106030. doi: 10.1016/j.jcomdis.2020.106030. Epub 2020 8 июля. J Коммунальное расстройство. 2020. PMID: 32707420 Обзор.
Посмотреть все похожие статьи
Рекомендации
- Ахаван, Н., Нозари, Н., и Гёксун, Т. (2017). Выражение событий движения на фарси. Язык, познание и неврология, 32 (6), 792–804. — DOI
- Алибали, MW (2005).
 Жест в пространственном познании: выражение, общение и размышление о пространственной информации. Пространственное познание и вычисления, 5 (4), 307–331.
—
DOI
Жест в пространственном познании: выражение, общение и размышление о пространственной информации. Пространственное познание и вычисления, 5 (4), 307–331.
—
DOI
- Алибали, MW (2005).
- Алибали М.В., Флеварес Л.М. и Голдин-Медоу С. (1997). Оценка знаний, переданных с помощью жестов: есть ли у учителей преимущество? Журнал педагогической психологии, 89 (1), 183–193. — DOI
- Алибали, М.В., Хит, округ Колумбия, и Майерс, Х.Дж. (2001). Влияние видимости между говорящим и слушателем на производство жестов: некоторые жесты предназначены для того, чтобы их видели.
 Журнал памяти и языка, 44 (2), 169–188.
—
DOI
Журнал памяти и языка, 44 (2), 169–188.
—
DOI
- Алибали, М.В., Хит, округ Колумбия, и Майерс, Х.Дж. (2001). Влияние видимости между говорящим и слушателем на производство жестов: некоторые жесты предназначены для того, чтобы их видели.
- Алибали, М.В., и Кита, С. (2010). Жесты выделяют перцептивно представляемую информацию для говорящих. Жест, 10 (1), 3–28. — DOI
Грантовая поддержка
- https://doi.org/10.37717/220020510/Фонд Джеймса С. Макдоннелла
с использованием глубокого обучения: часть 1 | by Bharath K
Понимание того, как создать детектор человеческих эмоций и жестов с помощью Deep Learning с нуля.

Кто-нибудь когда-нибудь задавался вопросом, глядя на кого-то и пытаясь проанализировать, какие эмоции они испытывали или какой жест они пытались выполнить, но в итоге вы были сбиты с толку. Возможно, когда-то вы пытались приблизиться к младенцу, который выглядел вот так:
Источник: Colin Maynard-UnsplashВы думали, что вы ему нравитесь и он просто хочет обниматься, а потом вы его несли, а потом случилось это!
Источник: Brytny.com-UnsplashУпс! Это не сработало, как планировалось. Но в реальной жизни использование может быть не таким простым, как в приведенной выше ситуации, и может потребоваться более точный анализ человеческих эмоций, а также анализ жестов. Эта область применения особенно полезна в любом отделе, где чрезвычайно важно удовлетворение потребностей клиентов или просто знание того, чего они хотят.
Сегодня мы раскроем пару моделей глубокого обучения, которые делают именно это. Модели, которые мы будем разрабатывать сегодня, могут идентифицировать некоторые человеческие эмоции, а также некоторые жесты. Мы попытаемся определить 6 эмоций, а именно злость, радость, нейтральность, страх, грусть и удивление. Мы также будем определять 4 типа жестов: неудачник, победа, супер и удар. Мы будем исполнять представление в реальном времени и получать вокальный отклик от модели в реальном времени.
Мы попытаемся определить 6 эмоций, а именно злость, радость, нейтральность, страх, грусть и удивление. Мы также будем определять 4 типа жестов: неудачник, победа, супер и удар. Мы будем исполнять представление в реальном времени и получать вокальный отклик от модели в реальном времени.
Модель эмоций будет построена с использованием сверточных нейронных сетей с нуля и для жестов пальцев. Я буду использовать трансферное обучение с архитектурой VGG-16 и добавлять пользовательские слои, чтобы улучшить производительность модели и повысить ее точность. Анализ эмоций и жесты пальцев обеспечат соответствующий голосовой и текстовый ответ на каждое действие. Показателем, который мы будем использовать, является точность, и мы постараемся достичь точности проверки не менее 50% для модели эмоций-1, более 65% для модели эмоций-2 и точности проверки более 9.0% для модели жестов.
Давайте теперь посмотрим на доступные нам наборы данных.
1. Набор данных Kaggle fer2013 — Набор данных представляет собой набор данных с открытым исходным кодом, который содержит 35 887 изображений различных эмоций в градациях серого, помеченных и имеющих размер 48×48. Набор данных распознавания лиц был опубликован во время Международной конференции по машинному обучению (ICML). Этот набор данных Kaggle будет более основным и важным набором данных, который будет использоваться для анализа эмоций в этом тематическом исследовании.
Набор данных распознавания лиц был опубликован во время Международной конференции по машинному обучению (ICML). Этот набор данных Kaggle будет более основным и важным набором данных, который будет использоваться для анализа эмоций в этом тематическом исследовании.
Набор данных предоставляется на листе Excel в формате .csv, а пиксели должны быть извлечены, и после извлечения пикселей и предварительной обработки данных набор данных выглядит как изображение, размещенное ниже:
Источник: изображение автора(Перейдите по этой ссылке, если первая ссылка не работает).
2. Первый аффект в дикой природе — Это может быть вторичный набор данных, рассматриваемый для данного тематического исследования. Задача First Affect-in-the-wild — это разработка современных архитектур глубокой нейронной сети, включая AffWildNet, которая позволяет нам использовать базу данных AffWild для изучения функций, которые можно использовать в качестве априорных для достижения наилучших показателей для многомерных и Категорическое распознавание эмоций. В ссылке для скачивания мы найдем файл tar.gz, который содержит 4 папки с именами: видео, аннотации, поля и ориентиры. Однако для нашей модели распознавания эмоций мы будем строго рассматривать только набор данных fer2013.
В ссылке для скачивания мы найдем файл tar.gz, который содержит 4 папки с именами: видео, аннотации, поля и ориентиры. Однако для нашей модели распознавания эмоций мы будем строго рассматривать только набор данных fer2013.
3. Набор данных ASL Alphabet — Это будет основной набор данных для обнаружения жестов пальцев. Набор данных алфавита «Американский язык жестов» состоит из набора изображений алфавитов американского языка жестов, разделенных на 29 папок, которые представляют различные классы. Набор обучающих данных содержит 87 000 изображений размером 200×200 пикселей.
Имеется 29 классов, из которых 26 для букв A-Z и 3 класса для ПРОБЕЛ, УДАЛИТЬ, и НИЧЕГО. Эти 3 класса очень полезны в приложениях реального времени и классификации. Однако для нашего распознавания жестов мы будем использовать 4 класса от A до Z из этих данных для некоторых необходимых действий с пальцами. Модель будет обучена распознавать 4 из этих конкретных жестов рук: A (удар рукой), F (супер), L (неудачник) и V (победа). Затем мы обучим нашу модель распознавать эти жесты и давать соответствующий голосовой ответ для каждого из следующих действий.
Затем мы обучим нашу модель распознавать эти жесты и давать соответствующий голосовой ответ для каждого из следующих действий.
4. Пользовательские наборы данных — Для обоих из них, то есть для анализа эмоций и обнаружения жестов пальцев, мы также можем использовать пользовательские наборы данных о себе, друзьях или даже семье для распознавания различных чувств, а также жестов рук. Снятые изображения будут окрашены в оттенки серого, а затем изменены в соответствии с нашими требованиями.
Для нашей модели эмоций мы будем использовать набор данных Kaggle fer2013 и набор данных ASL для идентификации жестов. Мы можем начать выполнять необходимую предварительную обработку, необходимую для моделей. Для набора данных эмоций мы рассмотрим библиотеки, необходимые для предварительной обработки.
Pandas — это быстрая и гибкая библиотека анализа данных с открытым исходным кодом, которую мы будем использовать для доступа к файлам .csv.
Numpy используется для обработки многомерных массивов. Для нашей предварительной обработки данных мы будем использовать numpy для создания массива пиксельных функций.
Для нашей предварительной обработки данных мы будем использовать numpy для создания массива пиксельных функций.
Модуль OS предоставляет нам способ взаимодействия с операционной системой.
Модуль cv2 — это модуль компьютерного зрения/open-cv, который мы будем использовать для преобразования пустых массивов пикселей в визуальные изображения.
tqdm — это необязательная библиотека, которую мы можем использовать для визуализации скорости обработки и количества битов в секунду.
Теперь давайте прочитаем файл fer2013.csv с помощью pandas.
Читаем файл fer2013.csv с помощью pandas. fer2013 — это файл .csv для распознавания выражений лица от Kaggle. В файле .csv у нас есть 3 основных столбца — эмоции, пиксели и использование. Колонка эмоций состоит из меток 0–6. Строка пикселей содержит изображения пикселей в формате массива. Столбец «Использование» содержит «Обучение», «Общий тест» и «Частный тест». Давайте посмотрим на это поближе.
Давайте посмотрим на это поближе.
Ярлыки находятся в диапазоне от 0 до 6, где:
0 = Злость, 1 = Отвращение, 2 = Страх, 3 = Радость,
4 = Печаль, 5 = Удивление, 6 = Нейтрально.
Пиксели состоят из значений пикселей, которые мы можем преобразовать в форму массива, а затем использовать открытый модуль cv2 для преобразования массива пикселей в фактическое изображение, которое мы можем визуализировать. Столбец Usage состоит из Training, PublicTest и PrivateTest. Мы будем использовать Training для хранения местоположения набора обучающих данных, а оставшиеся PublicTest и PrivateTest будут использоваться для хранения изображений в папке проверки.
Теперь давайте извлечем эти изображения соответствующим образом. В приведенных ниже блоках кода я покажу один класс как для обучения, так и для проверки. В этом блоке кода мы будем извлекать изображения из столбца пикселей, а затем создадим папку поезда и проверки, которую можно будет отслеживать из столбца «Использование».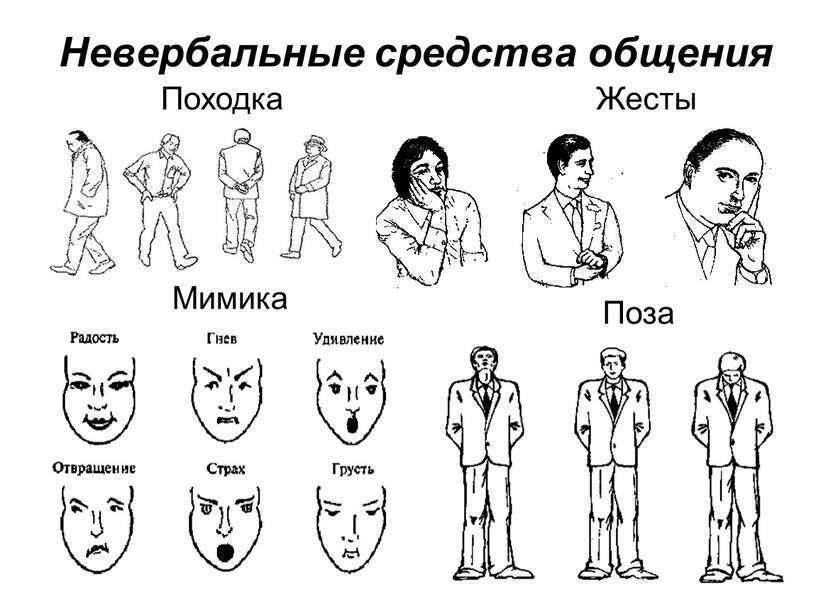 Для каждого из каталогов поезда и проверки мы создадим все 7 папок, которые будут содержать гнев, отвращение, страх, счастье, печаль, удивление и нейтральность.
Для каждого из каталогов поезда и проверки мы создадим все 7 папок, которые будут содержать гнев, отвращение, страх, счастье, печаль, удивление и нейтральность.
Мы перебираем набор данных и преобразуем пиксели из строки в число с плавающей запятой, а затем сохраняем все значения с плавающей запятой в массиве numpy. Мы конвертируем изображение размером 48×48, который является нашим желаемым размером изображения. (Этот шаг необязателен, потому что заданные пиксели уже имеют желаемый размер.)
Если Использование задано как Тренировка, то мы создаем каталог поезда, а также отдельные каталоги для каждой из эмоций. Мы храним изображения в правильном каталоге эмоций, который можно найти по меткам столбца эмоций.
Эти шаги повторяются аналогичным образом для каталога проверки, для которого мы рассматриваем значения Usage как PublicTest и PrivateTest. Эмоции классифицируются по меткам из столбца эмоций, аналогично тому, как работает каталог поездов.
После этого шага вся предварительная обработка данных для обучения эмоций завершена, и мы успешно извлекли все изображения, необходимые для модели распознавания эмоций, и теперь мы можем перейти к дальнейшим шагам.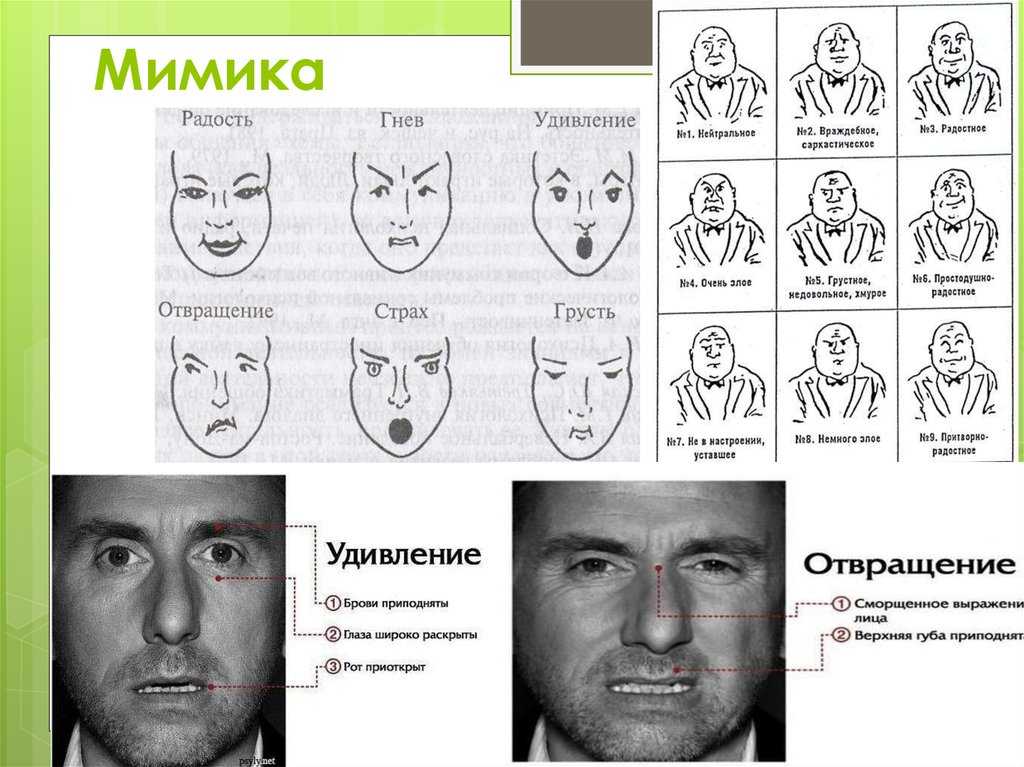 К счастью, нам не нужно выполнять много предварительной обработки данных жестов. Загрузите набор данных ASL, а затем создайте папки train1 и validation1, как показано ниже:
К счастью, нам не нужно выполнять много предварительной обработки данных жестов. Загрузите набор данных ASL, а затем создайте папки train1 и validation1, как показано ниже:
Каталоги train1 и validation1 имеют 4 подкаталога, помеченных, как показано. Мы будем использовать букву «L» для проигравшего, «A» для удара, «F» для супер и «V» для победы. Суммируя буквы и жесты ниже:
L = Неудачник | А = Удар | Ф = Супер | V = Victory
Набор данных ASL содержит 3000 изображений для каждой буквы. Поэтому мы будем использовать первые 2400 изображений для процесса обучения, а остальные 600 изображений — для целей проверки. Таким образом, мы разделяем данные на соотношение 80:20, поезд: проверка. Вставьте первые 2400 изображений каждого из алфавитов «L», «A», «F» и «V» в соответствующие подкаталоги в папке train1 и вставьте оставшиеся 600 изображений алфавитов в соответствующие подкаталоги. каталоги в папке validation1.
Прежде чем приступить к обучению наших моделей эмоций и жестов, давайте посмотрим на изображения и общие данные, которые у нас есть после этапа предварительной обработки. Во-первых, мы будем искать в EDA данные об эмоциях, а затем мы рассмотрим данные о жестах. Начав с данных об эмоциях, мы построим гистограмму и точечную диаграмму, чтобы увидеть, является ли набор данных сбалансированным, достаточно сбалансированным или полностью несбалансированным. Мы будем ссылаться на каталог поездов.
Во-первых, мы будем искать в EDA данные об эмоциях, а затем мы рассмотрим данные о жестах. Начав с данных об эмоциях, мы построим гистограмму и точечную диаграмму, чтобы увидеть, является ли набор данных сбалансированным, достаточно сбалансированным или полностью несбалансированным. Мы будем ссылаться на каталог поездов.
Гистограмма:
Точечная диаграмма:
Можно заметить, что это довольно сбалансированная модель, за исключением того, что изображений для «отвращения» сравнительно меньше. Для нашей первой модели эмоций мы полностью отбросим эту эмоцию и будем рассматривать только оставшиеся 6 эмоций. Теперь давайте посмотрим, как выглядят каталоги обучения и проверки для нашего набора данных эмоций.
Гистограмма и точечная диаграмма данных поезда показаны ниже:
Изображения поезда каждого набора данных показаны ниже:
Гистограмма и точечная диаграмма данных поезда показаны ниже:
Проверочные изображения каждого набора данных показаны ниже:
Проанализировав наш набор данных эмоций, мы можем перейти к набору данных жестов и выполните аналогичный анализ, как указано выше, и разберитесь с набором данных жестов.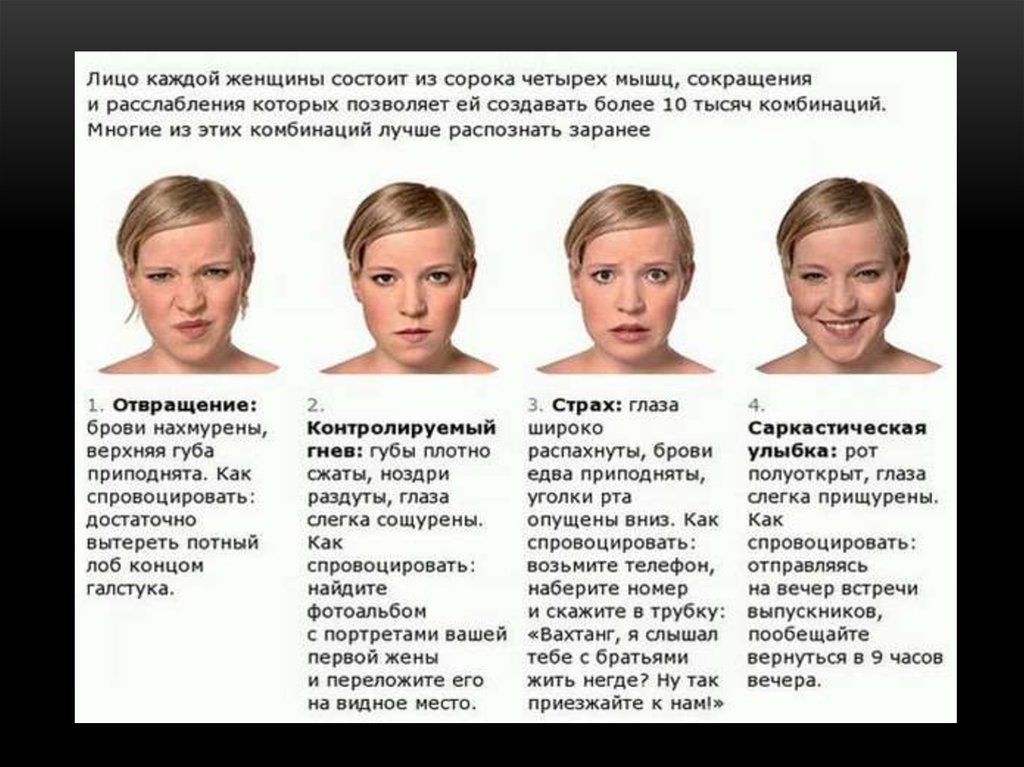 Поскольку набор данных для наших данных о жестах как для обучения, так и для проверки полностью сбалансирован, их легче анализировать. Данные обучения и проверки для набора данных жестов будут проанализированы в следующей части, а также будут отображаться похожие изображения.
Поскольку набор данных для наших данных о жестах как для обучения, так и для проверки полностью сбалансирован, их легче анализировать. Данные обучения и проверки для набора данных жестов будут проанализированы в следующей части, а также будут отображаться похожие изображения.
Это завершает наш исследовательский анализ данных для модели эмоций. Теперь мы можем начать строить наши модели для распознавания эмоций. Сначала мы построим модель эмоций, используя увеличение данных изображения, а затем построим модель жестов. Позже мы построим вторую модель эмоций непосредственно из файла .csv и попытаемся добиться большей точности. В конце мы создадим окончательную модель для запуска всего скрипта.
В этой модели-1 мы будем использовать методы увеличения данных. Формальное определение увеличения данных выглядит следующим образом:
Расширение данных — это стратегия, которая позволяет практикам значительно увеличить разнообразие данных , доступных для обучающих моделей, без фактического сбора новых данных .
Методы увеличения данных , такие как обрезка, заполнение и горизонтальное отражение, обычно используются для обучения больших нейронных сетей.
Ссылка: bair.berkeley.edu
Теперь мы приступим к импорту необходимых библиотек и укажем некоторые параметры, которые потребуются для обучения модели.
Импортируйте все необходимые библиотеки глубокого обучения для обучения модели эмоций.
Keras — это интерфейс прикладного программирования (API), который может работать поверх Tensorflow.
Tensorflow будет основным модулем глубокого обучения, который мы будем использовать для построения нашей модели глубокого обучения.
ImageDataGenerator используется для увеличения данных, когда модель может видеть больше копий модели. Увеличение данных используется для создания реплик исходных изображений и использования этих преобразований в каждую эпоху.
Слои для обучения, которые будут использоваться, следующие:
1. Вход = Входной слой, в который мы передаем входную форму.
2. Conv2D = Сверточный слой в сочетании с Входным для обеспечения вывода тензоров
3. Maxpool2D = Понижающая дискретизация данных из сверточного слоя.
4. Пакетная нормализация = Это метод обучения очень глубоких нейронных сетей, который стандартизирует входные данные слоя для каждого мини-пакета. Это приводит к стабилизации процесса обучения и резкому сокращению количества эпох обучения, необходимых для обучения глубоких сетей.
5. Dropout = Dropout — это метод, при котором во время обучения игнорируются случайно выбранные нейроны. Они «выпадают» случайным образом, что предотвращает переобучение.
6. Плотные = Полностью связанные слои.
7. Сведение = Сведение всей структуры в одномерный массив.
Модели могут быть построены в виде модели или могут быть построены последовательно.
Использование регуляризации l2 для тонкой настройки.
Используемым оптимизатором будет Adam, так как он работает лучше, чем другие оптимизаторы в этой модели.
Numpy для числовых операций с массивами.
pydot_ng и Graphviz используются для построения графиков.
Мы также импортируем модуль os, чтобы сделать его совместимым со средой Windows.
num_classes определяет количество классов, которые мы должны предсказать, а именно Angry, Fear, Happy, Neutral, Surprise и Neutral.
Из исследовательского анализа данных мы знаем, что Размеры изображения:
Высота изображения = 48 пикселей
Ширина изображения = 48 пикселей
Количество классов = 1, поскольку изображения представляют собой изображения в оттенках серого.
Мы рассмотрим размер пакета 32 для обучения увеличению изображения.
Укажите поезд и каталог проверки для сохраненных изображений.
train_dir — это каталог, в котором будет храниться набор изображений для обучения.
validation_dir — это каталог, который будет содержать набор проверочных изображений.
Теперь посмотрим на код увеличения данных:
Генератор ImageDataGenerator используется для увеличения данных изображений.
Мы будем воспроизводить и делать копии трансформаций
оригинальных изображений. Генератор данных Keras будет использовать копии и
, а не оригинальные. Это будет полезно для обучения в каждой эпохе.
Мы будем масштабировать изображение и обновлять все параметры в соответствии с нашей моделью. Параметры следующие:
1. rescale = Масштабирование на 1./255 для нормализации каждого из значений пикселей каждый угол в диапазоне против часовой стрелки.
4. zoom_range = Задает диапазон масштабирования.
5. width_shift_range = указать ширину расширения.
6. height_shift_range = Укажите высоту расширения.
7. horizontal_flip = Отразить изображения по горизонтали.
8. fill_mode = Заполнить в соответствии с ближайшими границами.
train_datagen.flow_from_directory Берет путь к каталогу и создает пакеты дополненных данных. Вызываемые свойства следующие:
1. train dir = Указывает каталог, в котором мы сохранили данные изображения.
train dir = Указывает каталог, в котором мы сохранили данные изображения.
2. color_mode = Важная функция, которая нам нужна, чтобы указать, как наши изображения классифицируются, т. Е. Оттенки серого или формат RGB. По умолчанию используется RGB.
3. target_size = Размеры изображения.
4. batch_size = Количество пакетов данных для операции потока.
5. class_mode = Определяет тип возвращаемых массивов меток.
«категориальный» будет 2D-метками с горячим кодированием.
6. перемешивание = перемешивание: следует ли перемешивать данные (по умолчанию: True)
Если установлено значение False, данные сортируются в алфавитно-цифровом порядке.
Теперь приступим к сборке модели.
Мы будем использовать последовательную архитектуру для нашей модели. Наша последовательная модель будет иметь в общей сложности 5 блоков, то есть три сверточных блока, один полносвязный слой и один выходной слой.
У нас будет 3 сверточных блока с фильтрами увеличивающегося размера, например, 32, 64 и 128 соответственно. Размер ядра будет равен (3,3), а размер ядра_инициализатора будет равен he_normal. Мы также можем использовать kernel_regularizer с нормализацией l2. Наш предпочтительный выбор активации — elu, потому что он обычно лучше работает с изображениями. Форма ввода будет такой же, как размер каждого из наших изображений поезда и проверки.
Слой пакетной нормализации. Пакетная нормализация — это метод повышения скорости, производительности и стабильности искусственных нейронных сетей. Максимальный пул используется для понижения дискретизации данных. Слой Dropout используется для предотвращения переобучения.
Полностью подключенный блок состоит из плотного слоя из 64 фильтров и пакетной нормализации, за которой следует слой исключения. Перед прохождением через плотный слой данные выравниваются, чтобы соответствовать размерам.
Наконец, выходной слой состоит из слоя Dense с активацией softmax для предоставления вероятностей в соответствии с num_classes, который представляет количество прогнозов, которые необходимо сделать.
Вот как выглядит наша общая модель, которую мы построили:
Мы будем импортировать 3 необходимых обратных вызова для обучения нашей модели. Три важных обратных вызова — это ModelCheckpoint, ReduceLROnPlateau и Tensorboard. Давайте посмотрим, какую задачу выполняет каждый из этих отдельных обратных вызовов.
- ModelCheckpoint — этот обратный вызов используется для хранения весов нашей модели после обучения. Мы сохраняем только лучшие веса нашей модели, указав save_best_only=True. Мы будем контролировать наше обучение, используя показатель точности.
- ReduceLROnPlateau — Этот обратный вызов используется для уменьшения скорости обучения оптимизатора после определенного количества эпох. Здесь мы указали терпение как 10. Если точность не улучшается после 10 эпох, то наша скорость обучения соответственно уменьшается в 0,2 раза. Метрика, используемая для мониторинга, также является точностью.
- Tensorboard — Обратный вызов tensorboard используется для построения визуализации графиков, а именно графиков графиков для точности и потерь.

На последнем этапе мы компилируем и подгоняем нашу модель. Здесь мы обучаем модель и сохраняем лучшие веса для эмоций.h5, чтобы нам не приходилось повторно обучать модель, и мы могли использовать нашу сохраненную модель, когда это необходимо. Мы будем тренироваться как на обучающих, так и на проверочных данных. Мы использовали потерю categorical_crossentropy, которая вычисляет потерю кросс-энтропии между метками и прогнозами. Мы будем использовать оптимизатор Adam со скоростью обучения 0,001, и мы будем компилировать нашу модель на основе метрической точности. Мы будем соответствовать данным на расширенных обучающих и проверочных изображениях. После этапа подгонки это результаты, которых мы можем достичь при поездке, а также при проверке потерь и точности.
Модель работает достаточно хорошо. Мы можем заметить, что потери при поездке и проверке постоянно уменьшаются, а точность при поездке и проверке постоянно увеличивается. В модели глубокого обучения нет чрезмерной подгонки, и мы можем достичь точности около 51% и точности проверки около 53%.

