НЛП Центр — НЛП образование в Москве и регионах
Ближайшие тренинги
1Первый Центр НЛП в России
27Лет на рынке
584Подготовленных тренеров
15 000НЛП-специалистов
Единственный профессиональный журнал о НЛП в России
Мы открылись в 1993 году и задали стандарты обучения НЛП в России и СНГ
Единственный Центр НЛП с лицензией на образовательную деятельность
Мы написали первый учебник по НЛП для участников курса «НЛП-Практик»
Центр НЛП в России, получивший мировое признание. Занесён в Энциклопедию НЛП Роберта Дилтса
10 социально-образовательных проектов
30 крупных корпоративных программ
30 открытых Центров-партнеров в России и СНГ
Мы первыми создали программу подготовки тренеров НЛП в России и способствовали формированию русскоговорящего НЛП-сообщества
4 уровня подготовки специалистов — от начального до профессионального по следующим направлениям: личностный рост, бизнес, тренерство и ораторское мастерство, психотерапия, творчество, гипноз.
Общий портфель программ — 105
Уже проведено более 1 300 учебных часов
Вы хотите развиваться больше, выше и сильнее?
Мы создали e-mail платформу именно для этого!
Специально для вас мы день и ночь создаем отменный психологический контент:
- обучающие видео-уроки;
- интересные статьи;
- практические советы для саморазвития;
- реальные кейсы из бизнеса и психотерапии;
- истории из жизни наши тренеров;
- скидки на тренинги и призы!
Все
НЛП-Старт
Для продвинутых
Тренинги А.Плигина и А.Герасимова
Бизнес
Для консультантов
Школа тренеров
Личностный рост
Звёзды НЛП в Москве
Мастер-классы
Онлайн
Ближайшие
Все Тренинги Мастер-классы
ВНИМАНИЕ. ДАТЫ ТРЕНИНГА МОГУТ ИЗМЕНИТЬСЯ.
7-дневный интенсив, который состоит из 3-х блоков: метасостояния и нейросемантика; применение знаний в бизнесе. Последний день — для тренеров, которые хотят преподавать метасостояния.
Последний день — для тренеров, которые хотят преподавать метасостояния.
#Майкл Холл #Звезды НЛП #Бизнес
НЛП-Практик. 147 поток. Тренинг, с которого вы можете начать свое путешествие в удивительный и эффективный мир НЛП. Базовый, сертификационный курс НЛП-Практик: цели, коммуникация, эмоциональные состояния.
Илья Селютин
Анатолий Демишонков
Василий Викторов
Екатерина Паршева
Татьяна Корчемаха
Ирина Седловская
Екатерина Кириллова
Системный тренерский курс
15 дней (3 сегмента по 5 дней) От харизматичного оратора — к авторскому тренингу. Получи новую профессию тренер.
Андрей Плигин
Александр Герасимов
НЛП-ПРАКТИК ОЧНО-ЗАОЧНЫЙ
Адаптированный для современного человека путь к ускоренному выходу на максимум своих возможностей. Базовые навыки для повседневной жизни, бизнеса и улучшения других сфер жизни.
Базовые навыки для повседневной жизни, бизнеса и улучшения других сфер жизни.
Татьяна Корчемаха
НЛП-ПрактикУМ Это еженедельные встречи, на которых каждый может оттачивать инструменты из арсенала практика НЛП и доводить свои навыки до совершенства. ТОЛЬКО ПРЕДВАРИТЕЛЬНАЯ ЗАПИСЬ!
НЛП-психотерапия
Курс рассчитан на консультантов, которые хотят научиться использовать инструменты и методы НЛП в психотерапевтическом направлении, в работе с глубинными проблемами клиентов.
Екатерина Паршева
Анатолий Демишонков
Профессиональная переподготовка
Проф. переподготовка по специальности «Клиническая психология».
Совместно с Московским Психолого-Социальным Университетом.
Екатерина Паршева
НЛП-Мастер Сертификационная программа, в которую входит освоение более продвинутых техник и моделей НЛП, навыков коммуникации, личностных изменений, изучение модели структуры убеждений и работа с мотивацией и изменением ограничивающих представлений человека.
Андрей Плигин
Александр Герасимов
Анатолий Демишонков
Основы консультирования
Курс для тех, кто хочет углубиться в изучение НЛП-консультирования.
Екатерина Паршева
Анатолий Демишонков
Современные родителиКак помочь ребенку вырасти счастливым?
Если Вы хотите воспитывать своих детей осознанно, приглашаю Вас!
Александр Герасимов
#Александр Герасимов #Родители
Системное мышление Мы не говорим о том, что видим; мы видим то, о чем мы можем говорить.
© Фред Кофман
Если вы хотите изменить свою реальность, вам стоит изменить своё мышление.
Александр Герасимов
#системное мышление #мышление #Александр Герасимов
Отзывы
Тренинг позволил мне разложить мои компетенции и понять, утвердив пути развития. Развивает личные навыки. Было полезно.Илья Гуцалюк Директор себя
Очень благодарна за полезные знания, умения, за чудесных людей, с кем были вместе, за ценное время, которое посчастливилось иметь. — Алена.Будет отлично, если в будущем станут доступны тренинги для детей или детей и взрослых. — Михаил.
Михаил и Алёна Сукачевы Алёна — Центр «Переводчик», переводчик, Гуманитарный университет, преподаватель. Михаил — Бюро профессиональных переводов, директор.
Понравились практические кейсы и инструменты, хотелось добавить mind-map со структурой тренинга (я так удобнее воспринимаю информацию). Интересен еще путь Александра: как он шел, кем стал в роли отца (над чем работал, как его воспитывали родители, его ограничивающие убеждения, транспортирую у себя как идею переосмысления свою миссию в роли главы семьи). Т.е. типичный кейс Александра.
Интересен еще путь Александра: как он шел, кем стал в роли отца (над чем работал, как его воспитывали родители, его ограничивающие убеждения, транспортирую у себя как идею переосмысления свою миссию в роли главы семьи). Т.е. типичный кейс Александра.Антон Галушко
Введите данные
для записи на тренинг
- Нажимая на кнопку «Записаться», я даю согласие на обработку персональных данных и соглашаюсь c условиями политики конфиденциальности.
- Я согласен на получение рекламной информации от Центра НЛП
- Я хочу получать SMS-сообщения о мериприятиях и/или иных услугах Центра НЛП.
- Я хочу получать email-письма о мероприятиях и/или иных услугах Центра НЛП.
- Я хочу получать звонки о мероприятиях и/или иных услугах Центра НЛП.
Заказать обратный звонок
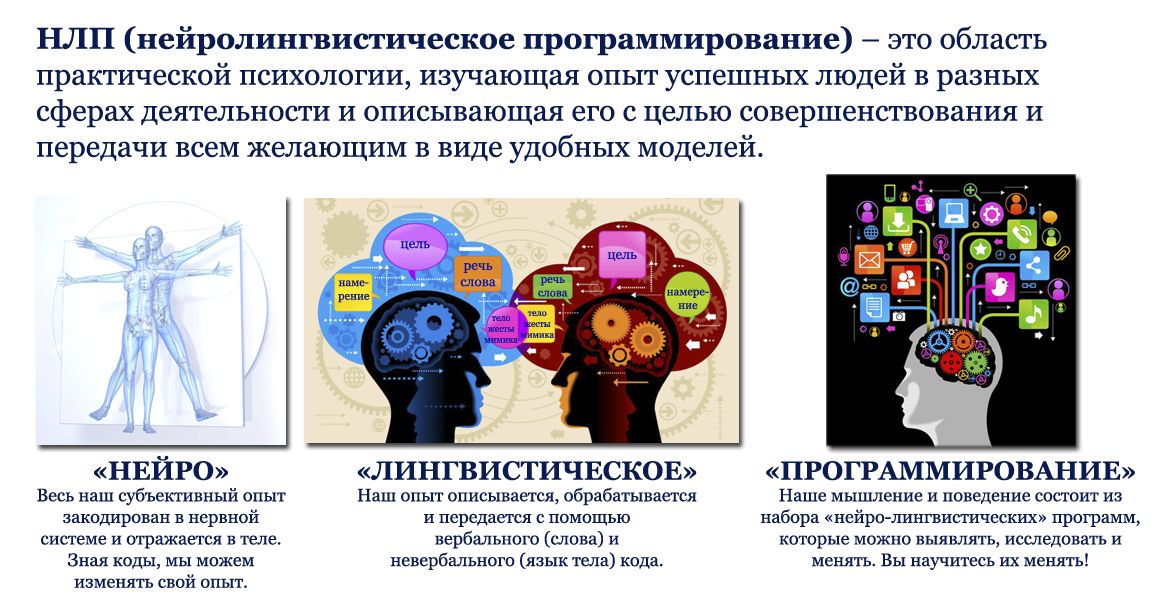
ТОП-5 Бесплатных Онлайн-Курсов НЛП в 2023 году с Нуля
evgenev » Soft Skills
Автор Евгений Волик На чтение 7 мин Просмотров 3. 8к.
Обновлено
8к.
Обновлено
Привет всем, друзья! ✌ Сегодня рассмотрим 5 Мощных онлайн-курсов для обучения НЛП, которые можно пройти абсолютно бесплатно.
1.
«НЛП — Нейролингвистическое программирование»Пройти
Без выдачи сертификата.
- Срок обучения: материал с обучающим контентом.
- Форма контента: лекции + задания в видео.
- Связь с преподавателем: нет.
- Срок регистрации на поток: без ограничений.
- Необходимый уровень знаний: для новичков.
- Проверка домашки: без проверки.
Обучающая программа: один из лучших курсов НЛП для новичков.
На правах рекламы
«🔥Нейролингвистическое программирование (НЛП) для начинающих»Прокачать счастье!
Для кого этот курс:
- Всех, кто занимается саморазвитием
- Всех, кто интересуется психологией
- Всех, кто много общается с людьми
- Всех, кто следит за своим здоровьем.

Что Вы получите:
- Узнаешь, как происходит процесс мышления и как он влияет на нашу жизнь
- Сможешь понимать людей с разными типами мышления и эффективно с ними коммуницировать
- Узнаешь, как усиливать позитивный жизненный опыт и ослаблять негативный
- Познакомишься с методами распознавания лжи и манипуляций
- Узнаешь, как повысить качество жизни и настроить себя на успех
- Сможешь находить выход из проблемных ситуаций и избавляться от негативных воспоминаний
- Узнаешь, как поддерживать здоровье и улучшать своё самочувствие
- Познакомишься с психологическими приёмами, которые помогают избавляться от вредных привычек
- Узнаешь, как бережно относиться к себе и к любым проявлениям своей психики.
Программа курса:
- Вступление
- Как мышление влияет на нашу жизнь
- Как сделать коммуникацию с собеседником эффективной
- Как понять собеседника и выстроить с ним диалог
- Как распознать ложь
- Как правильно формулировать свои мысли
- Как распознавать манипуляции
- Транс — состояние, которое мы не замечаем
- Как настраивать себя на успех
- Как регулировать настройки своего восприятия для повышения качества жизни
- Как корректировать свои воспоминания
- Техники выхода из проблемных ситуаций
- Как поддерживать своё здоровье и помогать себе выздоравливать
- Как избавиться от вредной привычки
- Экологичный подход к психике
Прокачать счастье!
2.
 «УРОКИ ПО НЛП»
«УРОКИ ПО НЛП» Пройти
Без выдачи сертификата.
- Срок обучения: материал с обучающим контентом.
- Форма контента: лекции + задания в видео.
- Связь с преподавателем: нет.
- Срок регистрации на поток: без ограничений.
- Необходимый уровень знаний: для новичков.
- Проверка домашки: без проверки.
Обучающая программа:
- Меняемся
- Что меняем
- Ресурсы
- Добавляем ресурс
- Схема изменения
- Якоря
- Наложение якорей
- Интеграция якорей
- Коллапс якорей
- Шкалирование эмоций
- Адреналиновый барометр
- Интеграция противоположных состояний
- Как принимать решения: Декартовы координаты
- Хорошо сформулированный результат
- Цель со всех сторон
- Субмодальности
- Управление интенсивностью переживаний
- Смена субмодальностей
- Критические субмодальности
- Калибровка
- Сенсорно-очевидное описание
- Вербальная и невербальная коммуникация
- Конгруэнтность
- Жесты
- Мимика
- Основные невербальные сообщения
- Метасообщение
- Сознательное и подсознательное доверие
- Раппорт и ведение
- Подстройка под позу
- Конгруэнтные сообщения, или как правильно показать…
- Отзеркаливание и присоединение
- Присоединение к сенсорной модальности
- Подстройка под скорость и энергию
- Врата Сортировки
- Выявление критериев
- Калибровка численных критериев
- Выравнивание важности критериев
- Критерии в переговорах и продажах
- Управляемая спонтанность
- Разговорный рефрейминг
- Отстройка
- Ассоциация и диссоциация
- Техника «Переоценка прошлого»
- Подсознательная подстройка
- Техника «Быстрое лечение фобий»
- Трехпозиционное описание
- Решение коммуникативной проблемы
- Метамодель: как конкретизировать информацию
- Модель SCORE: о чём собирать информацию.

3.
«Нейролингвистическое программирование и гипноз»Пройти
Без выдачи сертификата.
- Срок обучения: материал с обучающим контентом.
- Форма контента: лекции + задания в видео.
- Связь с преподавателем: нет.
- Срок регистрации на поток: без ограничений.
- Необходимый уровень знаний: для новичков.
- Проверка домашки: без проверки.
Обучающая программа: благодаря техникам работы с подсознанием, умению вводить транс и использовать методики внушения Вы сможете лучше узнать себя, свои возможности и гармонизировать свою жизнь.
Начинка курса
День 1
ВЛАСТЬ И ОЧАРОВАНИЕ
- Как разоблачать лжецов и противодействовать их манипуляциям
- Как читать мысли людей и очаровывать их за считанные секунды
- Как влиять на сознание людей, чтобы получать от них желаемое
- Практика: Простейшие техники манипуляций
День 2
ИСЦЕЛЕНИЕ С ПОМОЩЬЮ ГИПНОЗА
- Как избавиться от зависимости и вредных привычек
- Как принять себя и обрести гармонию с миром
- Самопрограммирование на здоровье и долголетие
- Практика: Гипнотическая медитация с установками на исцеление
Мастер-класс №3
КОД БОГАТСТВА И УСТАНОВКИ НА УСПЕХ
- Как избавиться от негативных установок на бедность и невезение
- Как активировать свою гениальность и уверенность в себе
- Психотехнологии для достижения целей и исполнения желаний
- Практика: «Мантра позитива» для хорошего настроения
Вы научитесь
- Научиться определять, где правда, а где ложь
- Начать влиять на людей и ситуации, чтобы всегда получать желаемое
- Узнать, как заручиться поддержкой нужных вам людей
- Получить инструменты для увеличения финансового потока через освобождение от блокирующих установок
- Открыть в себе новые возможности и раскрыть потенциал
- Обрести силы и вдохновение на новые свершения
- Узнать, как расстаться с пагубными привычками и пристрастиями
- Встать на путь к обретению здоровья и долголетия
- Обрести уверенность в себе и гармонию с миром и самим собой
4.
 «НЛП практик — полный курс НЛП за 10 минут»
«НЛП практик — полный курс НЛП за 10 минут» Пройти
Без выдачи сертификата.
- Срок обучения: 26 видео с обучающим контентом.
- Форма контента: лекции + задания в видео.
- Связь с преподавателем: нет.
- Срок регистрации на поток: без ограничений.
- Необходимый уровень знаний: для новичков.
- Проверка домашки: без проверки.
Обучающая программа: это один из бесплатных курсов НЛП — тренинг по НЛП от Александра Потапова в серии 10-ти минутных видео. Основы НЛП бесплатно онлайн. Без воды, только основная суть! Первый в мире открытый тренинг НЛП практик от Александра Потапова, в котором шаг за шагом раскрываются все темы курса и даются ответы на все вопросы.
Основы НЛП бесплатно онлайн. Без воды, только основная суть! Первый в мире открытый тренинг НЛП практик от Александра Потапова, в котором шаг за шагом раскрываются все темы курса и даются ответы на все вопросы.
Под видео вы можете написать конкретно вашу ситуацию или вопрос относящийся к этой теме нлп и получить ответ от сертифицированного тренера НЛП.
5.
«НЛП для начинающих. НЛП практик бесплатно. Введение.»Пройти
Без выдачи сертификата.
- Срок обучения: 12 видео с обучающим контентом.
- Форма контента: лекции + задания в видео.

- Связь с преподавателем: нет.
- Срок регистрации на поток: без ограничений.
- Необходимый уровень знаний: для новичков.
- Проверка домашки: без проверки.
Обучающая программа: цикл видео о том, что такое НЛП, кому полезно, где применять. Понятно, легко и с юмором. Первое видео из цикла НЛП практик для начинающих. В «НЛП для начинающих. Введение.» рассказывается про бесплатный курс, который будет полезен начинающим в НЛП.
Оцените автора
( Пока оценок нет )
НЛП для начинающих: полное руководство
Я был очарован обработкой естественного языка (НЛП) с тех пор, как начал заниматься наукой о данных. Я занимаюсь техническим письмом и теорией риторики, поэтому меня привлекают проекты, связанные с текстом, такие как анализ настроений и извлечение тем, потому что я хотел развить понимание того, как машинное обучение может дать представление о письменном языке.
Я всегда хотел, чтобы руководство, подобное этому, рассказывало, как извлекать данные из популярных социальных сетей. С ростом доступности мощных предварительно обученных языковых моделей, таких как BERT и ELMo, важно понимать, где искать и извлекать данные. К счастью, социальные сети являются богатым ресурсом для сбора наборов данных НЛП, и к ним легко получить доступ всего с помощью нескольких строк Python.
НЛП для начинающих: веб-скрейпинг Сайты социальных сетей
Лучшими сайтами для веб-скрейпинга являются Twitter, Reddit и Genius. Каждая из этих платформ предлагает невероятное количество данных, которые будут полезны практически для любой практики НЛП. Прежде чем начать, вам нужно знать основы Pandas и SQLite.
Предварительные требования
В этой статье рассказывается, как извлекать данные из Twitter, Reddit и Genius. Я предполагаю, что вы уже знакомы с основами библиотек Python Pandas и SQLite.
Управление ключами API
Прежде чем приступить к коду, важно подчеркнуть значение ключа API. Если вы новичок в управлении ключами API, обязательно сохраните их в файле
Если вы новичок в управлении ключами API, обязательно сохраните их в файле config.py , а не жестко кодируйте их в своем приложении. Убедитесь, что они не включены в какой-либо код, распространяемый в Интернете. API-ключи могут быть ценными (а иногда и очень дорогими), поэтому их необходимо защищать . Если вы беспокоитесь о утечке вашего ключа, большинство провайдеров позволяют вам восстановить его.
Добавьте файл конфигурации в свой файл gitignore, чтобы предотвратить его отправку в репозиторий!
Еще от Эрика КлеппенаКак практиковать Word2Vec для НЛП с использованием Python
Twitter API
Twitter предоставляет множество данных, к которым легко получить доступ через их API. С библиотекой Tweepy Python вы можете легко получать постоянный поток твитов на нужные темы. Твиттер отлично подходит для анализа тенденций и настроений.
Для этого руководства вам необходимо зарегистрировать приложение в Twitter, чтобы получить ключи API. Ознакомьтесь с официальной документацией Twitter, если вы не знакомы с их порталом для разработчиков!
Ознакомьтесь с официальной документацией Twitter, если вы не знакомы с их порталом для разработчиков!
Используйте pip для установки Tweepy и unidecode.
pip установить твипи пип установить юникод
Сохраните следующие ключи в файле конфигурации:
Использование Tweepy
При подключении Tweepy к Twitter используется OAuth2. Если вы новичок в аутентификации API, ознакомьтесь с официальным руководством по аутентификации Tweepy.
Чтобы сохранить данные из входящего потока, мне проще всего сохранить их в базе данных SQLite. Если вы не знакомы с таблицами SQL или вам нужно освежить знания, посмотрите примеры на этом бесплатном сайте или ознакомьтесь с моим руководством по SQL.
Функция unidecode() берет данные Unicode и пытается представить их в символах ASCII.
#импорт зависимостей импортировать твипи из твипи импортировать OAuthHandler из tweepy.streaming импортировать StreamListener импортировать json из unidecode импортировать unidecode время импорта импорт даты и времени #импортируйте ключи API из файла конфигурации.из конфига импортировать con_key, con_sec, a_token, a_secret sqlite3conn = sqlite3.connect("twitterStream.sqlite") c = соединение.курсор()
Мне нужно создать таблицу и сохранить данные. Я использую SQLite, потому что он легкий и не требует сервера. Плюс мне нравится хранить все данные в одном месте!
по определению create_table():
c.execute("СОЗДАТЬ ТАБЛИЦУ, ЕСЛИ Твиты НЕ СУЩЕСТВУЮТ (метка времени РЕАЛЬНАЯ, ТЕКСТ твита)")
conn.commit()
создать_таблицу()
Обратите внимание, что я использую IF NOT EXISTS , чтобы убедиться, что таблица еще не существует в базе данных. Не забудьте зафиксировать транзакцию, используя вызов conn.commit() .
Еще от встроенных экспертовПошаговое руководство по классификатору машинного обучения NLP
Создание класса StreamListener
Вот шаблонный код для извлечения твита и метки времени из потоковых данных твиттера и вставки их в базу данных.
прослушиватель класса (StreamListener):
def on_data (я, данные):
пытаться:
данные = json.loads (данные)
твит = unidecode (данные ['текст'])
time_ms = данные['timestamp_ms']
#print(твит, time_ms)
c.execute("ВСТАВИТЬ В твиты (метка времени, твит) ЗНАЧЕНИЯ (?, ?)", (время_мс, твит))
conn.commit()
время сна(2)
кроме KeyError как e:
печать (стр (е))
возврат (правда)
def on_error (я, код состояния):
если код_статуса == 420:
#возврат False в on_error отключает поток
вернуть ложь
пока верно:
пытаться:
аутентификация = OAuthHandler (con_key, con_sec)
auth.set_access_token(a_token, a_secret)
twitterStream = tweepy.Stream(авторизация, Слушатель())
twitterStream.filter(track=['DataScience'])
кроме Исключения как e:
печать (стр (е))
время сна(4)
Обратите внимание, что я замедляю поток, используя time. . sleep()
sleep()
Вы можете видеть, что код заключен в try/except , чтобы предотвратить прерывание потока из-за возможных сбоев. Кроме того, в документации рекомендуется использовать функцию on_error() в качестве прерывателя цепи, если приложение делает слишком много запросов.
Вы также заметите, что я оборачиваю объект потока в , а условие . Таким образом, он останавливается, если столкнется с ошибкой 420.
Обратите внимание, что twitterstream.filter использует дорожку для поиска ключевых слов в твитах. Если вы хотите следить за твитами определенного пользователя, используйте .filter(follow=[""]) .
Извлечение данных из базы данных SQLite
sql = '''выбрать твит из твитов
где твит не похож на «RT %»
упорядочить по метке времени desc'''
tweet_df = pd.read_sql(sql, соединение)
tweet_df
Пример Tweet DataFrame Ищете другие проекты НЛП? We Got You. 3 способа изучить НЛП с помощью Python
3 способа изучить НЛП с помощью Python
Reddit API
Как и Twitter, Reddit содержит огромное количество информации, которую легко собрать. Если вы не знаете, Reddit — это социальная сеть, которая работает как интернет-форум, позволяя пользователям публиковать сообщения на любую тему, которую они хотят. Пользователи формируют сообщества, называемые сабреддитами, и голосуют за или против постов в своих сообществах, чтобы решить, что просматривается в первую очередь, а что опускается на дно.
Я объясню, как получить ключ Reddit API и как извлечь данные из Reddit с помощью библиотеки PRAW. Хотя у Reddit есть API, Python Reddit API Wrapper, или сокращенно PRAW, предлагает упрощенный опыт. PRAW поддерживает Python 3.5+.
Взгляните на этот Python6 Новые потрясающие функции в Python 3.10
Начало работы с Reddit API
Для использования API требуется учетная запись пользователя Reddit. Это совершенно бесплатно и требует только адрес электронной почты.
Если вы впервые, выполните следующие действия, чтобы получить ключ API после входа в Reddit. Если у вас уже есть ключ, перейдите на страницу приложений.
Нажмите на учетную запись пользователя выпадающий список. Отображаются параметры пользователя.
Кнопка учетной записи пользователя Reddit.comНажмите Посетите старый Reddit в настройках пользователя. Страница изменится, и URL-адрес станет https://old.reddit.com/.
Щелкните ссылку настроек рядом с кнопкой выхода.
НастройкиЩелкните вкладку приложений на экране настроек.
Нажмите Вы разработчик? создать приложение … кнопка.
Регистрация Приложение Reddit.
Введите имя .
Выберите тип приложения .
Введите описание .
Используйте http://localhost:8080 в качестве URI перенаправления .
Нажмите , создайте приложение после заполнения полей.
Reddit API ClientОтобразится информация API, необходимая для подключения. Поздравляем с настройкой очистки данных Reddit!
Использование PRAW для извлечения данных Reddit
Рекомендуемый способ установки PRAW — использовать pip, а затем установить следующие пакеты для создания информационной панели.
pip install praw
Начните с импорта библиотек и файла конфигурации:
import praw импортировать панд как pd from config import cid, csec, ua
Создать экземпляр Reddit
Создать экземпляр Reddit только для чтения. Это означает, что вам не нужно вводить учетные данные Reddit, используемые для публикации ответов или создания новых тем; соединение только читает данные.
PRAW использует аутентификацию OAuth для подключения к Reddit API.
# создать соединение с Reddit reddit = praw.Reddit (client_id = cid, client_secret= csec, user_agent= ua)
Определение субреддитов
Вот список примеров, которые, я думаю, было бы интересно изучить:
новости, наука о данных, машинное обучение, игры, смешное, политика ? Я думал, вы никогда не спросите! Создайте виртуальную машину Linux на своем компьютере
Изучение объектов и атрибутов
Используйте класс субреддита в PRAW для получения данных из нужного субреддита. Данные можно упорядочить на основе следующих опций Reddit:
- hot — упорядочить по постам с наибольшим трафиком
- new — упорядочить по самым новым постам в ветке
- 900 13 топ — заказать посты с наибольшим количеством голосов
- восходящие — сортировать по набирающим популярность постам
Если вы хотите включить несколько сабреддитов, используйте символ + :
#single subreddit new 5 subreddit = reddit.subreddit('новости').new(limit = 5) # несколько субреддитов топ 5 subreddit = reddit.subreddit('news' + 'datascience').top(limit = 5)
Это возвращает объект , который содержит данные в атрибуте . Атрибут похож на ключ в словаре .
Данные связаны с атрибутом, принадлежащим объекту. Если 9Атрибут 0101 — это ключ , данные — это значение . Атрибуты генерируются динамически, поэтому лучше всего проверять, что доступно, с помощью встроенной в Python функции vars() .
Используйте этот шаблонный код, чтобы увидеть все атрибуты, принадлежащие объектам, представляющим сообщение Reddit. Это ДЛИННЫЙ список!
subreddit = reddit.subreddit('новости').new(limit = 1)
для поста в сабреддите:
pprint.pprint(vars(post)) Пример атрибутов пост-объектаОбратите внимание на интересующие атрибуты в списке:
- title — возвращает заголовок поста
- оценка — возвращает количество голосов «за» или «против»
- num_comments — возвращает количество комментариев в ветке
- selftext — возвращает текст сообщения
- created — возвращает метку времени для сообщения
- total_awards_received — возвращает количество наград, полученных постом
данные в Pandas DataFrame или сохранить их в базу данных SQLite как в примере с Twitter выше.
 В этом примере я сохраню его в Pandas DataFrame.
В этом примере я сохраню его в Pandas DataFrame.Произошла ошибка.
Невозможно выполнить JavaScript. Попробуйте посмотреть это видео на сайте www.youtube.com или включите JavaScript, если он отключен в вашем браузере.
НЛП для начинающихGenius Lyrics
Я фанат музыки, особенно хэви-метала. В хэви-метале тексты порой довольно сложны для понимания, поэтому я обращаюсь к Genius, чтобы расшифровать их. Genius — это платформа для аннотирования текстов песен и сбора информации о музыке, альбомах и исполнителях. Genius позволяет пользователям регистрировать клиент API.
Регистрация клиента API
Либо зарегистрироваться , либо 9Знак 0013 в
.Щелкните ссылку разработчиков .
Нажмите , чтобы создать клиент API .
Введите имя приложения .
Введите URL-адрес веб-сайта , если он у вас есть, иначе будет работать http://127. 0.0.1.
0.0.1.
Щелкните , сохраните . Отобразится клиент API.
Нажмите сгенерировать токен доступа , чтобы сгенерировать токен доступа.
Регистрация клиента APIИзвлечение текстов песен
По юридическим причинам Genius API не позволяет загружать тексты песен. Можно искать тексты песен, но не скачивать их. К счастью для всех, автор Medium Бен Уоллес разработал удобную оболочку для парсинга текстов. Посмотрите его исходный код на GitHub.
Я изменил оболочку Бена, чтобы упростить загрузку полного собрания произведений исполнителя, а не кодировать альбомы, которые я хочу включить. Я также добавил столбец исполнителя для хранения имени исполнителя.
Оболочка использует API, чтобы помочь URL-адресам ссылаться на тексты песен. Оттуда Beautiful Soup анализирует HTML для каждого URL. Результатом процесса является фрейм данных, который содержит название песни, URL-адрес, исполнителя, название альбома и текст:
Просмотрите оболочку GeniusArtistDataCollect
Оболочка представляет собой класс с именем GeniusArtistDataCollect() . Используйте его для подключения к API и получения текстов песен для указанного исполнителя. В примере я использую одну из моих любимых метал-групп The Black Dahlia Murder.
Используйте его для подключения к API и получения текстов песен для указанного исполнителя. В примере я использую одну из моих любимых метал-групп The Black Dahlia Murder.
Чтобы использовать GeniusArtistDataCollect(), создайте его экземпляр, передав токен доступа клиента и имя исполнителя .
g = GeniusArtistDataCollect(token, 'Убийство черного георгина')
Вызов get_artists_songs() из объекта GeniusArtistDataCollect . Это вернется как Pandas DataFrame .
song_df = g.get_artist_songs()song_df = g.get_artist_songs()
The Wrapper
Вот измененная оболочка:
import os импортировать повторно запросы на импорт импортировать панд как pd импортировать urllib.request из bs4 импортировать BeautifulSoup из токена импорта конфигурации класс GeniusArtistDataCollect: """Класс-оболочка, который может извлекать, очищать и упорядочивать все альбомные песни данного исполнителя.Использует Genius API и методы веб-скрейпинга для получения данных.""" def __init__(я, client_access_token, artist_name): """ Создание экземпляра объекта GeniusArtistDataCollect :param client_access_token: str — Токен для доступа к Genius API. Создайте его на https://genius.com/developers. :param artist_name:str - Имя интересующего исполнителя ЭТО БЫЛО УДАЛЕНО :param альбомы: список - список всех альбомов исполнителя, которые нужно собрать """ self.client_access_token = client_access_token self.artist_name = художник_имя #self.albums = альбомы self.base_url = 'https://api.genius.com/' self.headers = {'Авторизация': 'Носитель' + self.client_access_token} self.artist_songs = Нет поиск по определению (я, запрос): """Выполняет поисковый запрос в Genius API на основе параметра запроса. Возвращает ответ в формате JSON.""" request_url = self.base_url + 'поиск' данные = {'q': запрос} ответ = запросы.получить(запрос_url, данные=данные, заголовки=self.
headers).json() вернуть ответ деф get_artist_songs (я): """Получает песни пользователя self.artist_name и помещает их в pandas.DataFrame""" # Найдите исполнителя и получите его идентификатор search_artist = self.search(self.artist_name) artist_id = str(search_artist['response']['hits'][0]['result']['primary_artist']['id']) print("ID: " + artist_id) # Инициализировать DataFrame df = pd.DataFrame (столбцы = ['Название', 'URL']) # Перебрать все страницы песен исполнителя больше_страниц = Истина страница = 1 я = 0 в то время как больше_страниц: print("страница: " + ул(страница)) # Сделать запрос на получение песен исполнителя на заданной странице request_url = self.base_url + 'artists/' + artist_id + '/songs' + '?per_page=50&page=' + str(page) ответ = запросы.получить(запрос_url, заголовки=self.headers).json() распечатать (ответ) # Для каждой песни, для которой данный исполнитель является основным_исполнителем песни, добавьте название песни и # Genius URL-адрес DataFrame для песни в ответ['response']['songs']: если str(song['primary_artist']['id']) == artist_id: название = песня['название'] URL-адрес = песня ['URL-адрес'] df.
loc[i] = [название, URL] я += 1 страница += 1 если response['response']['next_page'] равен None: больше_страниц = Ложь # Получить HTML, название альбома и текст песни из вспомогательных методов в классе df['Исполнитель'] = self.artist_name df['html'] = df['URL'].apply(self.get_song_html) df['Album'] = df['html'].apply(self.get_album_from_html) #df['InAnAlbum'] = df['Album'].apply(лямбда a: self.is_track_in_an_album(a, self.albums)) #df = df[df['InAnAlbum'] == True] df['Lyrics'] = df.apply(лямбда-строка: self.get_lyrics(row.html), ось=1) дель дф['html'] self.artist_songs = дф вернуть self.artist_songs def get_song_html (я, URL): """Вычищает весь HTML-код параметра URL""" запрос = urllib.request.Request(url) request.add_header("Авторизация", "Носитель" + self.client_access_token) request.add_header ("Пользовательский агент", "завиток/7,9.8 (i686-pc-linux-gnu) libcurl 7.
9.8 (OpenSSL 0.9.6b) (включен ipv6)") страница = urllib.request.urlopen(запрос) html = BeautifulSoup(страница, "html") print("Очищено: " + URL) вернуть html деф get_lyrics (я, html): """Извлекает параметр html, чтобы получить текст песни на странице Genius в одном большом объекте String""" лирика = html.find("div", class_="лирика") все_слова = '' # Чистая лирика для строки в song.get_text(): all_words += строка # Удалить идентификаторы, такие как припев, куплет и т. д. all_words = re.sub(r'[\(\[].*?[\)\]]', '', all_words) # удалить пустые строки, лишние пробелы и специальные символы all_words = os.linesep.join([s вместо s в all_words.splitlines() if s]) all_words = all_words.replace('\r', '') all_words = all_words.replace('\n', ' ') all_words = all_words.replace(' ', ' ') вернуть все_слова def get_album_from_html (я, HTML): """Использует параметр html, чтобы получить название альбома песни на странице Genius""" синтаксический анализ = html.
findAll ("диапазон") альбом = '' для i в диапазоне (len (parse)): если parse[i].text == 'Альбом': я += 1 альбом = разбор[i].text.strip() перерыв вернуть альбом
Еще два примера веб-скрейпинга
В примере текстов песен Genius используется BeautifulSoup для извлечения текстов песен с веб-сайта. Веб-скрапинг — полезный метод, который упрощает сбор разнообразных данных. Я рассматриваю дополнительный пример парсинга веб-страниц в предыдущей статье. Хотя я еще не использовал его методы, коллега по встроенному эксперту Уилл Кёрсен просматривает и анализирует Википедию. Посмотрите его работу!
Уилл Кёрсен на встроенной Когда точности недостаточно, используйте точность и отзыв
Kaggle и Google Dataset Search
Хотя мне кажется, что собирать и создавать собственные наборы данных — это весело, Kaggle и Google Dataset Search предлагают удобные способы поиска структурированных и размеченных данных. Kaggle — популярная конкурентная платформа для обработки данных. Я включил список популярных наборов данных для проектов НЛП.
Kaggle — популярная конкурентная платформа для обработки данных. Я включил список популярных наборов данных для проектов НЛП.
- Определить, является ли новостной сюжет источником Onion или нет
- Рейтинги и описания Youtube
- Показы и описания Netflix
- Обзоры вин (я использовал это в нескольких статьях и проектах).
- Коллекция отзывов о еде Amazon
- Заголовки новостей для фейковых новостей
- Корпус для задач распознавания сущностей
- Твиты для анализа настроений авиакомпаний
- Обзор Yelp набор данных
Подробнее от встроенных экспертовАвтоматическое распознавание речи делает обращение в службу поддержки клиентов менее ужасным наборы. Приступить к обработке естественного языка может быть сложно, и я надеюсь, что это руководство упростит методы сбора текстовых данных. С помощью нескольких строк Python количество данных, доступных каждому на кончиках пальцев в Twitter, Reddit и Genius, ошеломляет!
Введение — Курс НЛП «Обнимание лица»
Добро пожаловать на 🤗 Курс!
Этот курс научит вас обработке естественного языка (NLP) с использованием библиотек из экосистемы Hugging Face — 🤗 Transformers, 🤗 Datasets, 🤗 Tokenizers и 🤗 Accelerate — а также Hugging Face Hub. Это совершенно бесплатно и без рекламы.
Это совершенно бесплатно и без рекламы.
Что ожидать?
Вот краткий обзор курса:
- Главы с 1 по 4 знакомят с основными понятиями библиотеки 🤗 Transformers. К концу этой части курса вы познакомитесь с тем, как работают модели Transformer, и узнаете, как использовать модель из Hugging Face Hub, точно настроить ее на наборе данных и поделиться своими результатами в Hub!
- Главы с 5 по 8 обучают основам 🤗 наборов данных и 🤗 токенизаторов, прежде чем погрузиться в классические задачи НЛП. К концу этой части вы сможете самостоятельно решать наиболее распространенные проблемы НЛП.
- Главы с 9 по 12 выходят за рамки NLP и исследуют, как модели Transformer можно использовать для решения задач обработки речи и компьютерного зрения. Попутно вы узнаете, как создавать и делиться демонстрационными версиями своих моделей, а также оптимизировать их для производственных сред. К концу этой части вы будете готовы применить 🤗 Transformers к (почти) любой задаче машинного обучения!
Этот курс:
- Требуется хорошее знание Python
- Лучше сдавать после вводного курса глубокого обучения, такого как «Практическое глубокое обучение для программистов» от fast.
 ai или одной из программ, разработанных DeepLearning.AI
ai или одной из программ, разработанных DeepLearning.AI - Не требует предварительного знания PyTorch или TensorFlow, хотя некоторое знакомство с любым из них поможет. такие модели, как наивный Байес и LSTM, о которых стоит знать!
Кто мы?
Об авторах:
Абубакар Абид защитил докторскую диссертацию в Стэнфорде в области прикладного машинного обучения. Во время работы над докторской диссертацией он основал Gradio, библиотеку Python с открытым исходным кодом, которая использовалась для создания более 600 000 демонстраций машинного обучения. Gradio была приобретена компанией Hugging Face, где Абубакар теперь является руководителем группы машинного обучения.
Мэтью Кэрриган — инженер по машинному обучению в Hugging Face. Он живет в Дублине, Ирландия, и ранее работал инженером по машинному обучению в Parse.ly, а до этого — научным сотрудником в Тринити-колледже в Дублине. Он не верит, что мы сможем достичь ОИИ за счет масштабирования существующих архитектур, но все равно возлагает большие надежды на бессмертие роботов.

Лисандра Дебют — инженер по машинному обучению в Hugging Face. Она работает над библиотекой 🤗 Transformers с самых ранних этапов разработки. Его цель — сделать НЛП доступным для всех, разработав инструменты с очень простым API.
Сильвен Гуггер — инженер-исследователь в Hugging Face и один из основных сопровождающих библиотеки 🤗 Transformers. Ранее он был научным сотрудником в fast.ai и написал в соавторстве с fastai и PyTorch 9 Deep Learning for Coders.0102 с Джереми Ховардом. Основное внимание в его исследованиях уделяется тому, чтобы сделать глубокое обучение более доступным путем разработки и улучшения методов, позволяющих моделям быстро обучаться с ограниченными ресурсами.
Давуд Хан — инженер по машинному обучению в Hugging Face. Он из Нью-Йорка и окончил Нью-Йоркский университет, изучая компьютерные науки. Проработав несколько лет iOS-инженером, Давуд ушел, чтобы основать Gradio вместе со своими коллегами-соучредителями.
 В конечном итоге Gradio была приобретена Hugging Face.
В конечном итоге Gradio была приобретена Hugging Face.Мерве Ноян — защитник разработчиков в Hugging Face, работающий над разработкой инструментов и созданием контента на их основе, чтобы демократизировать машинное обучение для всех.
Люсиль Солнье — инженер по машинному обучению в компании Hugging Face, занимающейся разработкой и поддержкой использования инструментов с открытым исходным кодом. Она также активно участвует во многих исследовательских проектах в области обработки естественного языка, таких как совместное обучение и BigScience.
Льюис Танстолл — инженер по машинному обучению в Hugging Face, специализирующийся на разработке инструментов с открытым исходным кодом и обеспечении их доступности для более широкого сообщества. Он также является соавтором книги О’Рейли «Обработка естественного языка с помощью трансформеров».
Леандро фон Верра — инженер по машинному обучению в команде открытого исходного кода в Hugging Face, а также соавтор книги О’Рейли «Обработка естественного языка с помощью трансформеров».
 У него есть многолетний опыт работы в отрасли по внедрению проектов NLP в производство, работая со всем стеком машинного обучения..
У него есть многолетний опыт работы в отрасли по внедрению проектов NLP в производство, работая со всем стеком машинного обучения..Часто задаваемые вопросы
Вот некоторые ответы на часто задаваемые вопросы:
Приводит ли прохождение этого курса к сертификации? В настоящее время у нас нет сертификации для этого курса. Тем не менее, мы работаем над сертификационной программой для экосистемы Hugging Face — следите за обновлениями!
Сколько времени я должен потратить на этот курс? Каждая глава этого курса рассчитана на прохождение в течение 1 недели, примерно 6-8 часов работы в неделю. Тем не менее, вы можете потратить столько времени, сколько вам нужно, чтобы пройти курс.
Где я могу задать вопрос, если он у меня есть? Если у вас есть вопрос по какому-либо разделу курса, просто нажмите на баннер « Задайте вопрос » в верхней части страницы, чтобы автоматически перенаправиться в нужный раздел форумов Hugging Face:
Обратите внимание, что список идей для проектов также доступен на форумах, если вы хотите попрактиковаться еще раз после прохождения курса.
- Где я могу получить код для курса? Для каждого раздела щелкните баннер в верхней части страницы, чтобы запустить код в Google Colab или Amazon SageMaker Studio Lab:
Блокноты Jupyter, содержащие весь код из курса, размещены на
Huggingface/notebooksрепо. Если вы хотите сгенерировать их локально, ознакомьтесь с инструкциями в репозитории курсаКак я могу участвовать в курсе? Есть много способов внести свой вклад в курс! Если вы нашли опечатку или ошибку, пожалуйста, откройте вопрос на
курсрепо. Если вы хотите помочь перевести курс на свой родной язык, ознакомьтесь с инструкциями здесь.Какой выбор был сделан для каждого перевода? Каждый перевод имеет глоссарий и файл
TRANSLATING.txt, в котором подробно описывается выбор, сделанный для жаргона машинного обучения и т. д. Вы можете найти пример для немецкого языка здесь.
