Социоматрица
Вначале следует построить простейшую социоматрицу. Пример дан в таблице (см. табл. «Пример социоматрицы»). Результаты выборов разносятся по матрице с помощью условных обозначений.
Анализ социоматрицы по каждому критерию дает достаточно наглядную картину взаимоотношений в группе. Могут быть построены суммарные социоматрицы, дающие картину выборов по нескольким критериям, а также социоматрицы по данным межгрупповых выборов.
Основное достоинство социоматрицы — возможность представить выборы в числовом виде, что, в свою очередь, позволяет проранжировать членов группы по числу полученных и отданных выборов, установить порядок влияний в той или иной конкретной группе. На основе социоматрицы строится социограмма — карта социометрических выборов (социометрическая карта), производится расчет социометрических индексов.
Социограмма
Социограмма
— схематическое изображение реакции
испытуемых друг на друга при ответах
на социометрический критерий.
Социограммная техника является существенным дополнением к табличному подходу в анализе социометрического материала, ибо она дает возможность более глубокого качественного описания и наглядного представления групповых явлений.
Анализ социограммы начинается с отыскания центральных, наиболее влиятельных членов, затем взаимных пар и группировок. Группировки составляются из взаимосвязанных лиц, стремящихся выбирать друг друга. Наиболее часто в социометрических измерениях встречаются положительные группировки из 2, 3 членов, реже из 4 и более членов (рис. 2).
Социометрические индексы
Различают
персональные социометрические индексы
(ПСИ) и групповые (ГСИ). Первые характеризуют
индивидуальные социально-психологические
свойства личности в роли члена группы.
Вторые дают числовые характеристики
целостной социометрической конфигурации
выборов в группе. Они описывают свойства
групповых структур общения.
Они описывают свойства
групповых структур общения.
Основными ПСИ являются:
индекс социометрического статуса i-члена;
индекс объема, интенсивности и концентрации взаимодействия ij-члена.
Символы i и j обозначают одно и то же лицо, но в разных ролях: i — выбираемый, j — выбирающий, ij — совмещение ролей.
Индекс социометрического статуса i-члена группы определяется по формуле (см.ниже)
Социометрический
статус — это свойство личности как
элемента социометрической структуры
занимать определенную пространственную
позицию (локус) в ней, т.е. определенным
образом соотноситься с другими элементами.
Такое свойство развито у элементов
групповой структуры неравномерно и для
сравнительных целей может быть измерено
числом — индексом социометрического
статуса.
Возможен
расчет Сi + — положительного и Сi +
-отрицательного статуса в группах малой
численности (N). Индекс эмоциональной
экспансивности j -члена группы высчитывается
по формуле (см. ниже)
ниже)
Индекс показывает среднюю активность группы при решении задач социометрического теста (в расчете на каждого члена).
Индекс психологической взаимности в группе («сплоченности группы») высчитывается по формуле (см.ниже)
Надежность рассмотренной процедуры зависит прежде всего от правильного отбора критериев социометрии, что диктуется программой исследования и предварительным знакомством со спецификой группы.
Использование социометрического теста позволяет проводить измерение авторитета формального и неформального лидеров для перегруппировки людей в бригадах так, чтобы снизить напряженность в коллективе, возникающую из-за взаимной неприязни некоторых членов группы.
Социометрическая
методика проводится групповым методом,
ее проведение не требует больших
временных затрат (до 15 мин.). Она весьма
полезна в прикладных исследованиях,
особенно в работах по совершенствованию
отношений в коллективе.
Пример социоматрицы для группы, численностью n членов
Примечание: + положительный выбор; — отрицательный выбор
Социограмма
Социограмма — схематическое изображение реакции испытуемых друг на друга при ответах на социометрический критерий. Социограмма позволяет произвести сравнительный анализ структуры взаимоотношений в группе в пространстве на некоторой плоскости («щите») с помощью специальных знаков (рис. 1).
Социограммная техника является существенным дополнением к табличному подходу в анализе социометрического материала, ибо она дает возможность более глубокого качественного описания и наглядного представления групповых явлений.
Анализ социограммы
начинается с отыскания центральных,
наиболее влиятельных членов, затем
взаимных пар и группировок. Группировки
составляются из взаимосвязанных лиц,
стремящихся выбирать друг друга.
Наиболее часто в социометрических
измерениях встречаются положительные
группировки из 2,3 членов, реже из 4 и
более членов (рис. 2).
Группировки
составляются из взаимосвязанных лиц,
стремящихся выбирать друг друга.
Наиболее часто в социометрических
измерениях встречаются положительные
группировки из 2,3 членов, реже из 4 и
более членов (рис. 2).
Социометрические индексы
Различают персональные социометрические индексы (ПСИ) и групповые (ГСИ). Первые характеризуют индивидуальные социально-психологические свойства личности в роли члена группы. Вторые дают числовые характеристики целостной социометрической конфигурации выборов в группе. Они описывают свойства групповых структур общения.
Основными ПСИ являются:
—индекс социометрического статуса i-члена;
—индекс эмоциональной экспансивности j-члена;
—индекс объема, интенсивности и концентрации взаимодействия ij-члена.
Символы i и j обозначают одно и то же лицо, но в разных ролях: i — выбираемый, j — выбирающий, ij — совмещение ролей.
Индекс социометрического статуса i-члена группы определяется по формуле:
где Ci
-— социометрический статус i-члена,
Rj
— полученные i-членом
выборы,
— знак алгебраического суммирования
числа полученных выборовi-члена,
N
— число членов группы.
Социометрический
статус — это свойство личности как
элемента социометрической структуры
занимать определенную пространственную
позицию (локус) в ней, т.е. определенным
образом соотноситься с другими элементами.
Такое свойство развито у элементов
групповой структуры неравномерно и для
сравнительных целей может быть измерено
числом — индексом социометрического
статуса. Элементы социометрической
структуры — это личности, члены
группы. Каждый из них в той или иной мере
взаимодействует с каждsм,
общается, непосредственно обменивается
информацией и т.д. В то же время каждый
член группы, являясь частью целого
(группы), своим поведением воздействует
на свойства целого. Реализация этого
воздействия протекает через различные
социально-психологические формы
взаимовлияния. Субъективную меру этого
влияния подчеркивает величина
социометрического статуса. Но личность
может влиять на других двояко: либо
положительно, либо отрицательно. Поэтому
принято говорить о положительном и
отрицательном статусе.
Возможен расчет Ci + — положительного и Ci- —отрицательного статуса в группах малой численности (N).
Индекс эмоциональной экспансивности j-члена группы высчитывается по формуле:
где Ej — эмоциональная экспансивность j-члена, R — сделанные j-членом выборы (+,-).
С психологической точки зрения показатель экспансивности характеризует потребность личности в общении. Из ГСИ наиболее важными являются:
Индекс эмоциональной экспансивности группы высчитывается по формуле:
где Ag—экспансивность группы, N — число членов группы.
Индекс показывает среднюю активность группы при решении задач социометрического теста (в расчете на каждого члена).
Индекс психологической взаимности в группе («сплоченности группы») высчитывается по формуле:
где Gg
— взаимность в группе по результатам
положительных выборов, Aij+
— число положительных взаимных связей
в группе, N -— число членов группы.
Надежность рассмотренной процедуры зависит прежде всего от правильного отбора критериев социометрии, что диктуется программой исследования и предварительным знакомством со спецификой группы.
Использование социометрического теста позволяет проводить измерение авторитета формального и неформального лидеров для перегруппировки людей в бригадах так, чтобы снизить напряженность в коллективе, возникающую из-за взаимной неприязни некоторых членов группы.
Социометрическая методика проводится групповым методом, ее проведение не требует больших временных затрат (до 15 мин.). Она весьма полезна в прикладных исследованиях, особенно в работах по совершенствованию отношений в коллективе. Но она не является радикальным способом разрешения внутригрупповых проблем, причины которых следует искать не в симпатиях и антипатиях членов группы, а в более глубоких источниках.
11
р — Таблица исходных данных к матрице смежности/социоматрице
спросил
Изменено 5 лет, 1 месяц назад
Просмотрено 286 раз
Часть R Language CollectiveУ меня есть таблица данных, устроенная так:
ID Категория 1 Категория 2 Категория 3 Название 1 Пример 1 Пример 2 Пример 3 Название 2 Пример 1 Пример 2 Пример 4 Название 3 Пример 5 Пример 6 Пример 4 .... .... .... .....
Пытаюсь превратить в таблицу вот так:
Имя 1 Имя 2 Имя 3 .... Имя 1 0 2 0 Имя 2 2 0 1 Имя 3 0 1 0 ....
Где каждая ячейка в выходной таблице представляет, сколько категорий оказались одинаковыми при сравнении идентификаторов. Это также может быть то, сколько категорий были разными, любая из них будет работать. Я изучил матрицы смежности и социоматрицы при переполнении стека, а также некоторые рекомендации по сопоставлению матриц, но не думаю, что моя таблица данных настроена правильно. Есть ли у кого-нибудь рекомендации, как это сделать?
РЕДАКТИРОВАТЬ: Ах, извините. Я использую R в качестве моей программы. Оставил этот бит
- r
- сортировка
- матрица
- матрица смежности
Вы можете сделать это, сначала поместив свои данные в длинный формат, после чего это становится довольно простым упражнением:
900 14 # твой данные tdf <- data.frame(ID = paste0("Имя", 1:3), cat1 = paste0("Пример", c(1,1,5)), cat2 = paste0("Пример ", c(2,2,6)), cat3= paste0("Пример ", c(3,4,4))) тдф #> ID cat1 cat2 cat3 #> 1 Имя 1 Пример 1 Пример 2 Пример 3 #> 2 Название 2 Пример 1 Пример 2 Пример 4 #> 3 Имя 3 Пример 5 Пример 6 Пример 4 # категории лишние, важна связь ID с # значения примера, поэтому мы преобразуем df в длинный формат, используя # функция плавления из пакета reshape2 lfd <- reshape2::melt(tdf, id. vars = «ID»)
#> Предупреждение: атрибуты не идентичны для переменных меры; они будут
#> быть отброшенным
# создаем матрицу принадлежности
adj1 <- as.matrix(таблица(lfd$ID, lfd$value))
прил1
#> #> Пример 1 Пример 2 Пример 3 Пример 4 Пример 5 Пример 6
#> Имя 1 1 1 1 0 0 0
#> Имя 2 1 1 0 1 0 0
#> Имя 3 0 0 0 1 1 1
# Матрица смежности — это просто произведение
id_id_adj_mat <- adj1 %*% t(adj1)
# Установите диагональ на ноль (в настоящее время диагональ отображает степень каждого узла)
диаг(id_id_adj_mat) <- 0
id_id_adj_mat
#> #> Имя 1 Имя 2 Имя 3
#> Имя 1 0 2 0
#> Имя 2 2 0 1
#> Имя 3 0 1 0 2
vars = «ID»)
#> Предупреждение: атрибуты не идентичны для переменных меры; они будут
#> быть отброшенным
# создаем матрицу принадлежности
adj1 <- as.matrix(таблица(lfd$ID, lfd$value))
прил1
#> #> Пример 1 Пример 2 Пример 3 Пример 4 Пример 5 Пример 6
#> Имя 1 1 1 1 0 0 0
#> Имя 2 1 1 0 1 0 0
#> Имя 3 0 0 0 1 1 1
# Матрица смежности — это просто произведение
id_id_adj_mat <- adj1 %*% t(adj1)
# Установите диагональ на ноль (в настоящее время диагональ отображает степень каждого узла)
диаг(id_id_adj_mat) <- 0
id_id_adj_mat
#> #> Имя 1 Имя 2 Имя 3
#> Имя 1 0 2 0
#> Имя 2 2 0 1
#> Имя 3 0 1 0 2Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и парольОпубликовать как гость
Электронная почтаТребуется, но никогда не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.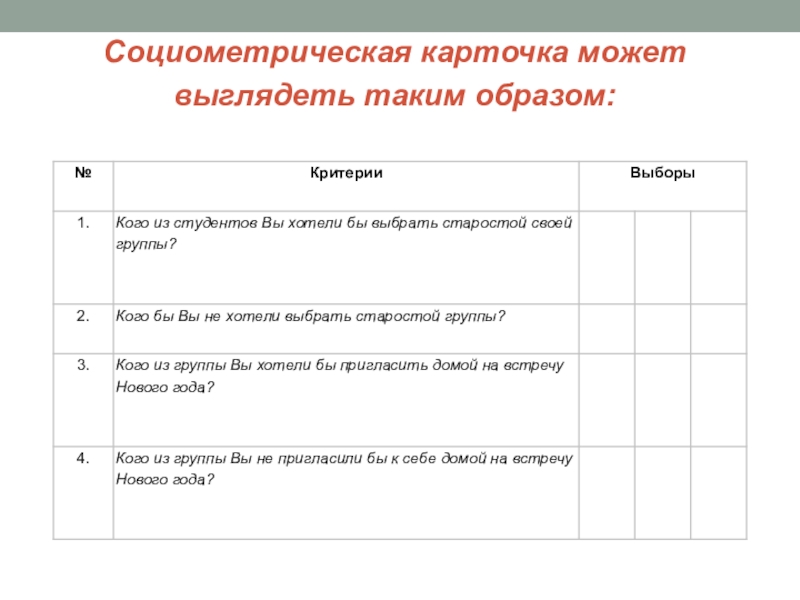
networking — Сохранение имен вершин при преобразовании в список краев в R testmat
<- sna::rgraph(длина(имена_вершин)) dimnames(testmat) <- list(vertex_names, vertex_names) испытательный стенд #> 153 154 155 156 157 158 #> 153 0 0 0 1 1 0 #> 154 1 0 0 1 0 1 #> 155 1 1 0 0 0 1 #> 156 1 0 1 0 1 1 #> 157 1 0 1 1 0 0 #> 158 0 1 1 1 1 0 maxsymmetrizedfile <- sna::symmetrize(testmat, правило = "слабый") dimnames(maxsymmetrizedfile) <- dimnames(testmat) maxsymmetrizedfile #> 153 154 155 156 157 158 #> 153 0 1 1 1 1 0 #> 154 1 0 1 1 0 1 #> 155 1 1 0 1 1 1 #> 156 1 1 1 0 1 1 #> 157 1 0 1 1 0 1 #> 158 0 1 1 1 1 0 maxsymm_edge имеет атрибут с именем "vnames" , который отсутствует в вашем примере.
maxsymm_edge <- sna::as.edgelist.sna(maxsymmetrizedfile) maxsymm_edge #> snd rec val #> [1,] 2 1 1 #> [2,] 3 1 1 #> [3,] 4 1 1 #> [4,] 5 1 1 #> [5,] 1 2 1 #> [6,] 3 2 1 #> [7,] 4 2 1 #> [8,] 6 2 1 #> [9,] 1 3 1 #> [10,] 2 3 1 #> [11,] 4 3 1 #> [12,] 5 3 1 #> [13,] 6 3 1 #> [14,] 1 4 1 #> [15,] 2 4 1 #> [16,] 3 4 1 #> [17,] 5 4 1 #> [18,] 6 4 1 #> [19,] 1 5 1 #> [20,] 3 5 1 #> [21,] 4 5 1 #> [22,] 6 5 1 #> [23,] 2 6 1 #> [24,] 3 6 1 #> [25,] 4 6 1 #> [26,] 5 6 1 #> атрибут(,"n") #> [1] 6 #> атрибут(,"vnames") #> [1] "153" "154" "155" "156" "157" "158" # *********
Мы можем проиндексировать "vnames" , включенных в список краев (что совпадает с vertex_names ).
(vnames <- attr(maxsymm_edge, "vnames")) #> [1] "153" "154" "155" "156" "157" "158" (snd_indices <- maxsymm_edge[ "snd"]) #> [1] 2 3 4 5 1 3 4 6 1 2 4 5 6 1 2 3 5 6 1 3 4 6 2 3 4 5 vnames[snd_indices] #> [1] "154" "155" "156" "157" "153" "155" "156" "158" "153" "154" "156" "157" #> [13] "158" "153" "154" "155" "157" "158" "153" "155" "156" "158" "154" "155" #> [25] "156" "157" (rec_indices <- maxsymm_edge[ "snd"]) #> [1] 2 3 4 5 1 3 4 6 1 2 4 5 6 1 2 3 5 6 1 3 4 6 2 3 4 5 vnames[rec_indices] #> [1] "154" "155" "156" "157" "153" "155" "156" "158" "153" "154" "156" "157" #> [13] "158" "153" "154" "155" "157" "158" "153" "155" "156" "158" "154" "155" #> [25] "156" "157"
Таким образом, мы можем построить фрейм данных напрямую следующим образом:
el_df <- data.frame( snd = attr(maxsymm_edge, "vnames")[maxsymm_edge[ "snd"]], rec = attr(maxsymm_edge, "vnames")[maxsymm_edge[ "rec"]], значение = maxsymm_edge [ "значение"], stringsAsFactors = FALSE # значение по умолчанию, если R.Version()$major >= 4 ) el_df #> snd rec val #> 1 154 153 1 #> 2 155 153 1 #> 3 156 153 1 #> 4 157 153 1 #> 5 153 154 1 #> 6 155 154 1 #> 7 156 154 1 #> 8 158 154 1 #> 9153 155 1 #> 10 154 155 1 #> 11 156 155 1 #> 12 157 155 1 #> 13 158 155 1 #> 14 153 156 1 #> 15 154 156 1 #> 16 155 156 1 #> 17 157 156 1 #> 18 158 156 1 #> 19 153 157 1 #> 20 155 157 1 #> 21 156 157 1 #> 22 158 157 1 #> 23 154 158 1 #> 24 155 158 1 #> 25 156 158 1 #> 26 157 158 1
Почему фрейм данных вместо матрицы? Поскольку имена вершин и "val" имеют разные типы ( символ против double ), поэтому попытка сделать это (в лучшем случае) приведёт "val" к набору строк.
ул(эл_дф) #> 'data.frame': 18 набл. из 3 переменных: #> $ snd: chr "154" "155" "156" "157" ... #> $ rec: chr "153" "153" "153" "153" ... #> $ val: число 1 1 1 1 1 1 1 1 1 1 ...
Но это имеет значение, только если вы собираетесь использовать "val" . Сеть не взвешена, поэтому вы можете индексировать "vnames" , чтобы вместо этого построить список ребер матрицы (или использовать as., чтобы удалить этот столбец и перейти от фрейма данных к матрице). matrix(el_df[ 1:2])
matrix(el_df[ 1:2])
Имея все это в виду, мы можем сделать еще один шаг и создать функцию, которая обрабатывает всю операцию:
as_edge_list_df <- function(adj_mat, use_vertex_names = TRUE) {
Melted <- do.call(cbind, lapply(list(row(adj_mat), col(adj_mat), adj_mat), as.vector)) # 3 столбца матрицы индекса строки, индекса столбца и значений `x`
filtered <- Melted[ 3] != 0, ] # удалить строки, где столбец 3 равен 0
if (use_vertex_names && !is.null(dimnames(adj_mat))) { # если нам не нужны имена вершин
if (!all(rownames(adj_mat) == colnames(adj_mat))) { # в случае неправильного формата `adj_mat`
stop("Имена строк не совпадают с именами столбцов.")
}
vertex_names <- rownames(adj_mat)
данные.кадр(
snd = имена_вершин[отфильтровано[ 1L]],
rec = имена_вершин[отфильтровано[ 2L]],
val = отфильтровано[ 3L]
)
} еще {
данные.кадр(
snd = фильтрованный [ 1 л],
rec = отфильтровано[ 2L],
val = отфильтровано[ 3L]
)
}
}
Затем протестируйте его.
