Что такое НЛП и как оно работает, техники нейролингвистического программирования
Нейролингвистическое программирование (НЛП) — это учение о способах эффективной коммуникации и саморазвития. Сторонники теории утверждают, что с помощью конкретных приемов мышления и поведения человек может изменить свою жизнь, а также целенаправленно влиять на других людей.
Это плакаты времен Второй мировой войны. Иллюстраторы использовали узнаваемые жесты и мимику, чтобы воздействовать на аудиторию. Героиня первого постера должна была повысить моральный дух рабочих, а герой второго — обращался конкретно к каждому человеку с помощью жеста
Аббревиатура НЛП включает в себя три основных понятия:
- Нейро — прием информации через органы чувств, а также все нейронные процессы ее обработки.
- Лингвистика — язык, слова и фразы, с помощью которых люди общаются между собой, а также мыслят.
- Программирование — контроль повседневных действий, четкие алгоритмы и схемы мышления и поведения.


С помощью определенных жестов, поведения, слов и фраз, человек легче входит в доверие, вызывает у собеседника положительные эмоции на интуитивном уровне, убеждает.
Во время публичных выступлений Барак Обама часто демонстрировал открытые ладони. Этот жест означает: «Моим словам можно доверять, я честен с вами»
А еще человек может влиять не только на других, но и на себя. Сторонники НЛП стараются контролировать свои слова и мысли, используют самогипноз. Они верят, что простые фразы, которые мы говорим сами себе, влияют на состояние и развитие личности.
Нейролингвистическое программирование признают псевдонаукой, а все эксперименты в этой области являются недостаточно достоверными. При этом авторы и «эксперты» теории продолжают писать книги, выпускать онлайн-курсы, запускать марафоны и зарабатывать на этом.
Работают ли приемы НЛП на самом деле, неизвестно. Но отдельные психологические методики активно применяют в политике, продажах, переговорах, педагогике.
Кто и когда придумал НЛП
Нейролингвистическое программирование зародилось в США в начале семидесятых. Теорию активно развивали студент‑психолог Ричард Бендлер и профессор лингвистики Джон Гриндер. Позднее к ним присоединились психотерапевты Вирджиния Сатир, Фриц Перлз, Милтон Эриксон, антрополог Грегори Бейтсон и лингвист Альфред Коржибски.
Свои наработки Бендлер и Гриндер изложили в книге The Structure of Magic (1975). Концепция стала быстро приносить авторам большие деньги — они проводили тренинги и активно продвигали методику по всему миру.
Курсы Бендлера посещал оратор и брокер Джордан Белфорт — прототип героя Леонардо Ди Каприо в фильме «Волк с Уолл-стрит», которого судили за мошенничество и отмывание денег.
Харизматичный герой фильма активно использует приемы НЛП — жесты, мимику, словесные манипуляции
Основные техники нейролингвистического программирования
В НЛП используют индивидуальные и групповые практики. Авторы методики утверждают, что их более сотни. Приведем в пример несколько самых популярных техник.
Приведем в пример несколько самых популярных техник.
Моделирование. Если ты хочешь быть успешным как Стив Джобс, нужно думать, одеваться, говорить и вести себя как Стив Джобс. А еще окружить себя людьми, на которых хочешь быть похожим.
Аффирмация. «Я успешен, я притягиваю людей, я магнит для денег» — подобные убеждения нужно повторять про себя ежедневно, чтобы настроиться на позитивные мысли и привлечь желаемое в свою жизнь.
На YouTube есть много видео, которые «заряжают» на успех, удачу, счастье
Фрейминг. Этот прием иллюстрирует фраза: «Если я не могу изменить ситуацию, я могу изменить свое отношение к ней». Важно рассмотреть проблему или событие под другим углом, сделать выводы и найти позитивные стороны.
Создание якоря. По мнению сторонников НЛП, человек может создать себе цветовой, вкусовой, обонятельный или звуковой стимул, который вызывает конкретные чувства и эмоции. Например, можно сделать якорь на чувство радости или спокойствия. Потрогал мочку уха — и справился с внешними раздражителями.
Потрогал мочку уха — и справился с внешними раздражителями.
Гипноз и самогипноз. Воздействуют на подсознание человека, иногда в скрытой для объекта форме.
Одна из методик гипноза НЛП — тройная спираль Милтона Эриксона. Ее суть в том, что человек должен рассказать собеседнику три истории. Сначала рассказывает первую, но ближе к ее финалу резко переходит ко второй, не связывая их между собой. Затем рассказывает третью историю, в которой содержится основной важный посыл. А далее заканчивает вторую и первую истории.
Это выглядит как сумбурный эмоциональный рассказ, но на самом деле повествование строится так специально. Считается, что собеседник начнет искать логику между историями. В этот момент мозг слушателя максимально восприимчив, и основной тезис проникнет прямо в подсознание.
Жесты и мимика. Адепты теории уверены, что человек транслирует и воспринимает огромный объем информации через невербалику. Контролируя постановку рук и ног, позу и улыбку, человек может воздействовать на слушателей и собеседников.
Отсюда рождаются следующие рекомендации: ораторам и политикам демонстрировать открытые ладони, менеджерам продаж — не скрещивать ноги и руки в разговоре с клиентом. А еще копировать жесты собеседника и даже подстраивать свой ритм дыхания под его.
Техники НЛП в рекламе и продвижении
Некоторые приемы нейролингвистического программирования применяют в рекламе: слоганах, креативах, видеороликах, баннерах.
Трюизмы. Необходимо написать 2-3 предложения, которые считаются общепризнанной истиной, а между ними вставить свое рекламное послание. Считается, что слушатель автоматически примет рекламное сообщение за истину.
Встречают по одежке. Неважно, какой вы человек, окружающие всегда сначала оценивают внешность. С помощью одежды человек самовыражается и транслирует собственное «я», создает образ. Чтобы собрать его грамотно, многие успешные личности обращаются к стилистам (рекламное сообщение). Правильно подобранная одежда помогает выглядеть более стильно, статусно или, наоборот, креативно и мило.
Импликатура. Хитрый прием, когда продавец напрямую не говорит о достоинствах товара, но при этом они становятся очевидны для читателя. Часто используется в рекламных слоганах.
Кетчуп стал еще вкуснее — А ведь он и раньше был вкусным.
Что делает наш сок особенным? — Ммм, этот сок особенный!
А еще этот прием позволяет обойти закон о рекламе и сравнить товар с конкурентами в свою пользу.
Рекламный ответ Hyundai отечественному автопрому
«Пожалуй». По закону о рекламе нельзя говорить, что ваш товар лучший среди конкурентов. Чтобы обойти это правило, добавьте вводное слово «пожалуй» в рекламный слоган и пропишите главное УТП своего продукта.
Якорение. Важны не только оффер и достоинства товара, а еще эмоции, которые он вызывает. Поэтому, наряду с текстом, маркетологи активно используют нужные изображения, музыку, видеоряд. Так создают устойчивые ассоциации аудитории с продуктом.
Видеоролик от производителя детского питания «Тема» наполнен добрыми ассоциациями: солнечная квартира, яркие обои, улыбающиеся родственники и счастливый малыш
А еще якорение активно используют в кино, художественной литературе, новостях, политической и социальной рекламе.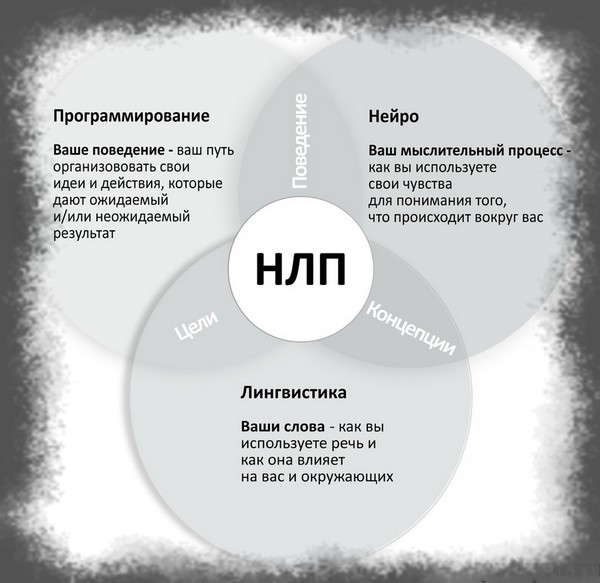 Это помогает усилить впечатление. Монстры в фильмах ужасов любят нападать в грозу, а когда герою фильма грустно — непременно идет дождь.
Это помогает усилить впечатление. Монстры в фильмах ужасов любят нападать в грозу, а когда герою фильма грустно — непременно идет дождь.
Вживленная оценка. Конкретный эпитет для продукта используют постоянно во всей рекламной коммуникации. Тогда аудитория начинает воспринимать его как истинный, автоматически повторяет в речи и связывает с продуктом.
Иллюзия выбора. Технику часто применяют менеджеры продаж в магазине или по телефону. Вместо того чтобы спросить, будете ли вы покупать продукт, они в нужный момент оставляют вас без выбора.
Вы будете оплачивать картой или наличными?
Каталог удобнее выслать на почту или в мессенджер?
А вообще этот прием работает в реальной жизни, в ежедневной коммуникации. Просто создайте иллюзию выбора, и собеседник быстрее отреагирует на вашу просьбу.
«Ты наденешь платье или джинсы?» вместо «Давай скорее одевайся в школу!».
«Ты хочешь пропылесосить сейчас или после обеда?» вместо «Почему ковер еще грязный!»
Синестезия.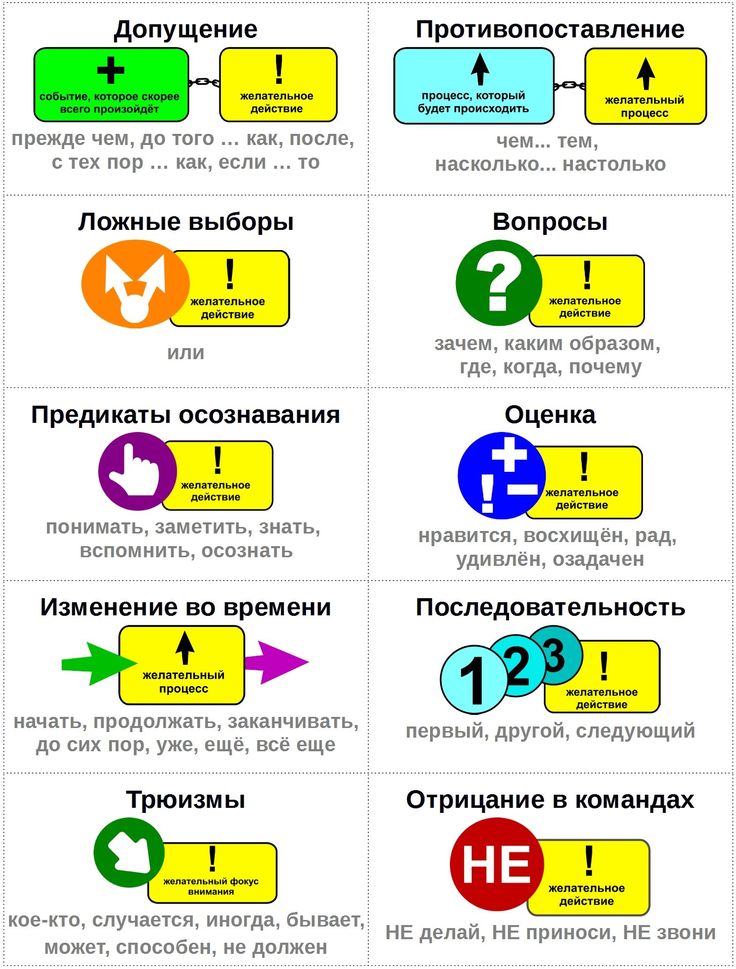 Ярко выражается в личных продажах. При коммуникации стараются задействовать все органы чувств покупателя: дать понюхать аромат, нанести крем на руку, положить в руки флаер. При этом продавцу важно работать грамотно, чтобы не оттолкнуть нетактильного покупателя излишней напористостью.
Ярко выражается в личных продажах. При коммуникации стараются задействовать все органы чувств покупателя: дать понюхать аромат, нанести крем на руку, положить в руки флаер. При этом продавцу важно работать грамотно, чтобы не оттолкнуть нетактильного покупателя излишней напористостью.
Аромат свежей выпечки в магазинах будоражит обонятельные рецепторы и внушает покупателю: «Купи эту хрустящую булочку»
Обобщения. Расскажите о значимой группе людей, которые используют ваш продукт, и сыграйте на желании ваших клиентов стать частью этой группы. Или сделайте акцент на значимых ценностях.
НЛП: за и против
Эффективность приемов НЛП научно не доказана. Считается, что авторы методики применяют сомнительную терминологию, смешивают понятия, а также используют устаревшие данные об устройстве мозга и психики человека.
Некоторые психологи и психотерапевты внедряют НЛП в лечении фобий и невротических состояний. Такой подход подвергается критике научного сообщества.
Неизвестно, насколько нейролингвистическое программирование работает в рекламе и продажах. Используемые приемы — скорее попытка усилить эффект от рекламного сообщения, привлечь внимание. Если продукт неинтересен аудитории и откровенно плох, вряд ли НЛП поможет его продать.
Главные мысли
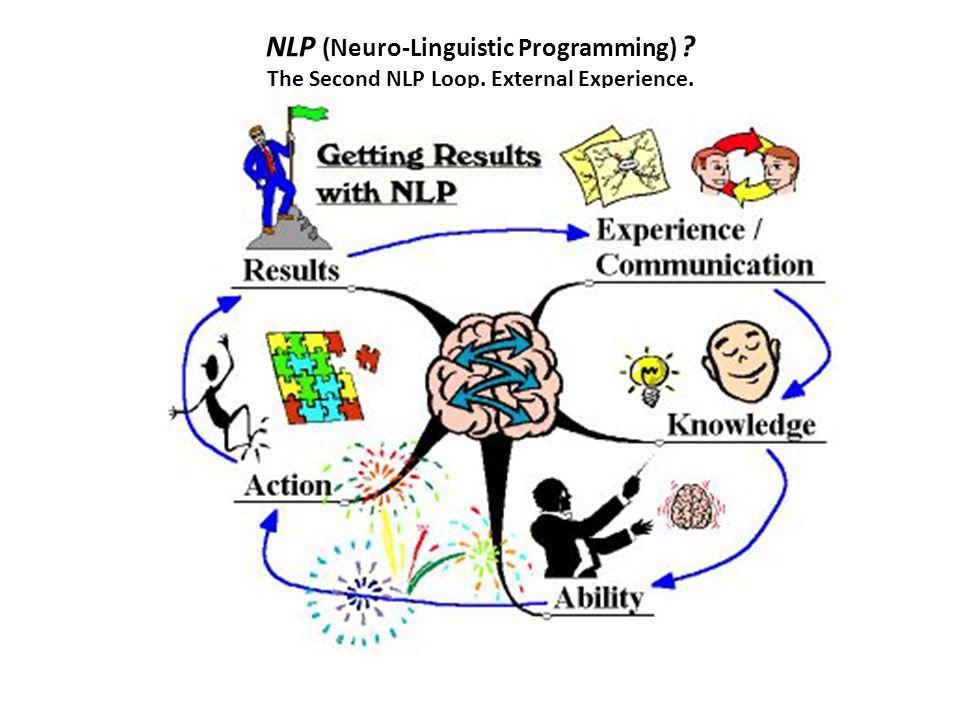
Что такое НЛП (Нейролингвистическое программирование)?
Нейро-Лингвистическое Программирование – это направление практической психологии, которое изучает успешные стратегии мышления и поведения людей в различных контекстах жизни.
Всё НЛП базируется на одном фундаментальном принципе:
Если хоть один человек на Земле что-то умеет, то этому могут научиться ВСЕ!
Т.е., зная то, каким образом устроен человеческий опыт, можно любой навык или любую успешную стратегию поведения человека изучить и описать в виде пошаговой инструкции, которой может воспользоваться любой желающий. Именно сочетание эффективности и практичности данных

Сегодня НЛП накопило большой багаж мощнейших технологий, которые могут позволить Вам значительно повысить свою эффективность в таких контекстах жизни, как: переговоры, отношения, познание себя, бизнес, цели, управление эмоциями и др.
Почему важно обучаться технологиям НЛП?
Мы с Вами привыкли действовать по определенным шаблонам поведения. Например: кто-то систематически ставит цели и систематически их не достигает, кто-то систематически проваливает переговоры, кто-то постоянно злится на детей или «соседей по пробке». И нам часто кажется, что так действовать нормально, т.к.
Это то же самое, как если бы мы, желая открыть дверь, дергали её в другую сторону. С открытой дверью всё просто, если она не откроется, то мы толкнем или потянем её туда, куда надо, но, что делать если нужная дверь закрыта на замок, от которого у Вас нет ключа? У многих из нас бывают ситуации в которых раз от раза мы не получаем тех результатов, которых хотим, и каждый раз мы повторяем всё теже ошибки. И это происходит, т.к. мы не знаем, как можно поступить более эффективно.
И это происходит, т.к. мы не знаем, как можно поступить более эффективно.
Технологии НЛП – это набор ключей от множества дверей, за которыми открывается большое количество возможностей и изменений. Как эффективно вести переговоры? Как управлять своими эмоциями? Как понять своего супруга или супругу? Как мотивировать себя на достижение целей? Как понять, что на самом деле важно в жизни? И это только малая часть вопросов на которые НЛП даёт простые и очень эффективные ответы.
Большинство людей, которые обучаются технологиям НЛП отмечают значительные перемены в своей жизни в лучшую сторону за счет расширения своих возможностей влиять на себя и окружающий Мир.
Что люди говорят об НЛП:
Баранников Константин
Бизнес-консультант
Я считаю НЛП основой большинства моих достижений.
Попова Анна
Руководитель отдела
НЛП перевернуло восприятие всего происходящего вокруг. Могу сказать смело — супер, советую всем!
Могу сказать смело — супер, советую всем!
Галушко Антон
Предприниматель
НЛП — это в первую очередь инструмент для совершенствования себя в любых контекстах.
Калинина Лариса
Предприниматель
Пути к целям стали более предсказуемыми, и получается делать меньше «телодвижений» и ошибок.
Стало интересно, что же такое нейролингвистическое программирование? Посетите мастер-класс «НЛП-старт»
Что такое обработка естественного языка? — Объяснение НЛП
Что такое НЛП?
Обработка естественного языка (NLP) — это технология машинного обучения, которая дает компьютерам возможность интерпретировать, манипулировать и понимать человеческий язык. Сегодня организации имеют большие объемы голосовых и текстовых данных из различных каналов связи, таких как электронная почта, текстовые сообщения, новостные ленты социальных сетей, видео, аудио и многое другое. Они используют программное обеспечение НЛП для автоматической обработки этих данных, анализа намерений или настроений в сообщении и реагирования в режиме реального времени на человеческое общение.
Они используют программное обеспечение НЛП для автоматической обработки этих данных, анализа намерений или настроений в сообщении и реагирования в режиме реального времени на человеческое общение.
Почему важно НЛП?
Обработка естественного языка (NLP) имеет решающее значение для полного и эффективного анализа текстовых и речевых данных. Он может работать с различиями в диалектах, сленге и грамматическими неточностями, типичными для повседневных разговоров.
Компании используют его для нескольких автоматизированных задач, таких как:
• Обработка, анализ и архивирование больших документов
• Анализ отзывов клиентов или записей колл-центра
• Запуск чат-ботов для автоматизированного обслуживания клиентов
• Ответы на вопросы «кто-что-когда-где»
• Классификация и извлечение текста
Вы также можете интегрировать НЛП в клиентские приложения для более эффективного общения с клиентами. Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает сократить расходы, избавляет агентов от траты времени на избыточные запросы и повышает удовлетворенность клиентов.
Эта автоматизация помогает сократить расходы, избавляет агентов от траты времени на избыточные запросы и повышает удовлетворенность клиентов.
Каковы варианты использования НЛП для бизнеса?
Предприятия используют программное обеспечение и инструменты для обработки естественного языка (NLP) для упрощения, автоматизации и рационализации операций эффективно и точно. Ниже мы приводим несколько примеров использования.
Редактирование конфиденциальных данных
Предприятия, работающие в сфере страхования, права и здравоохранения, обрабатывают, сортируют и извлекают большие объемы конфиденциальных документов, таких как медицинские записи, финансовые данные и личные данные. Вместо проверки вручную компании используют технологию NLP для редактирования личной информации и защиты конфиденциальных данных. Например, Chisel AI помогает страховым компаниям извлекать номера полисов, даты истечения срока действия и другие личные атрибуты клиентов из неструктурированных документов с помощью Amazon Comprehend.
Взаимодействие с клиентами
Технологии НЛП позволяют чатам и голосовым ботам быть более похожими на людей при общении с клиентами. Предприятия используют чат-ботов, чтобы масштабировать возможности и качество обслуживания клиентов, сводя к минимуму эксплуатационные расходы. Компания PubNub, которая создает программное обеспечение для чат-ботов, использует Amazon Comprehend для внедрения локализованных функций чата для своих клиентов по всему миру. T-Mobile использует НЛП, чтобы определять определенные ключевые слова в текстовых сообщениях клиентов и предлагать персонализированные рекомендации. Университет штата Оклахома развертывает чат-бот для вопросов и ответов, чтобы отвечать на вопросы студентов с помощью технологии машинного обучения.
Бизнес-аналитика
Маркетологи используют инструменты NLP, такие как Amazon Comprehend и Amazon Lex, чтобы получить обоснованное представление о том, что клиенты думают о продукте или услугах компании. Просматривая определенные фразы, они могут оценить настроение и эмоции клиентов в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях при анализе настроений и помогают контакт-центрам получать полезную информацию из аналитики вызовов.
Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях при анализе настроений и помогают контакт-центрам получать полезную информацию из аналитики вызовов.
Как работает НЛП?
Обработка естественного языка (NLP) объединяет вычислительную лингвистику, машинное обучение и модели глубокого обучения для обработки человеческого языка.
Компьютерная лингвистика
Компьютерная лингвистика — это наука о понимании и построении моделей человеческого языка с помощью компьютеров и программных инструментов. Исследователи используют методы компьютерной лингвистики, такие как синтаксический и семантический анализ, для создания схем, которые помогают машинам понимать разговорный человеческий язык. Такие инструменты, как языковые переводчики, синтезаторы текста в речь и программное обеспечение для распознавания речи, основаны на вычислительной лингвистике.
Машинное обучение
Машинное обучение — это технология, которая обучает компьютер с помощью образцов данных для повышения его эффективности. В человеческом языке есть несколько особенностей, таких как сарказм, метафоры, вариации в структуре предложений, а также исключения из грамматики и использования, на изучение которых у людей уходят годы. Программисты используют методы машинного обучения, чтобы научить приложения NLP распознавать и точно понимать эти функции с самого начала.
В человеческом языке есть несколько особенностей, таких как сарказм, метафоры, вариации в структуре предложений, а также исключения из грамматики и использования, на изучение которых у людей уходят годы. Программисты используют методы машинного обучения, чтобы научить приложения NLP распознавать и точно понимать эти функции с самого начала.
Глубокое обучение
Глубокое обучение — это особая область машинного обучения, которая учит компьютеры учиться и думать, как люди. Он включает в себя нейронную сеть, состоящую из узлов обработки данных, структура которых напоминает человеческий мозг. Благодаря глубокому обучению компьютеры распознают, классифицируют и связывают сложные закономерности во входных данных.
Обычно внедрение НЛП начинается со сбора и подготовки неструктурированных текстовых или речевых данных из таких источников, как облачные хранилища данных, опросы, электронные письма или внутренние приложения бизнес-процессов.
Предварительная обработка
Программное обеспечение НЛП использует методы предварительной обработки, такие как токенизация, выделение корней, лемматизация и удаление стоп-слов, чтобы подготовить данные для различных приложений.
Вот описание этих методов:
- Токенизация разбивает предложение на отдельные единицы слов или фраз.
- Основы и лемматизация упрощают слова до их корневой формы. Например, эти процессы превращают «запуск» в «запуск».
- Удаление стоп-слов обеспечивает удаление слов, не добавляющих существенного значения предложению, таких как «для» и «с».
Обучение
Исследователи используют предварительно обработанные данные и машинное обучение для обучения моделей НЛП выполнению определенных приложений на основе предоставленной текстовой информации. Обучение алгоритмов НЛП требует загрузки в программное обеспечение больших выборок данных для повышения точности алгоритмов.
Развертывание и вывод
Затем специалисты по машинному обучению развертывают модель или интегрируют ее в существующую производственную среду. Модель НЛП получает входные данные и прогнозирует выходные данные для конкретного варианта использования, для которого предназначена модель. Вы можете запустить приложение НЛП на реальных данных и получить требуемый результат.
Вы можете запустить приложение НЛП на реальных данных и получить требуемый результат.
Что такое задачи НЛП?
Методы обработки естественного языка (NLP), или задачи NLP, разбивают человеческий текст или речь на более мелкие части, которые могут быть легко поняты компьютерными программами. Общие возможности обработки и анализа текста в НЛП приведены ниже.
Тегирование частей речи
Это процесс, при котором программное обеспечение НЛП помечает отдельные слова в предложении в соответствии с их контекстуальным употреблением, например, существительные, глаголы, прилагательные или наречия. Это помогает компьютеру понять, как слова образуют значимые отношения друг с другом.
Устранение неоднозначности смысла слов
Некоторые слова могут иметь разные значения при использовании в разных сценариях. Например, слово «летучая мышь» означает разные вещи в этих предложениях:
- Летучая мышь — ночное существо.
- Игроки в бейсбол бьют по мячу битой.
Благодаря устранению неоднозначности смысла слова программное обеспечение НЛП идентифицирует предполагаемое значение слова либо путем обучения его языковой модели, либо путем обращения к словарным определениям.
Распознавание речи
Распознавание речи преобразует голосовые данные в текст. Процесс включает в себя разбиение слов на более мелкие части и понимание акцентов, оскорблений, интонации и нестандартного использования грамматики в повседневном разговоре. Ключевым применением распознавания речи является транскрипция, которую можно выполнять с помощью сервисов преобразования речи в текст, таких как Amazon Transcribe.
Машинный перевод
Программное обеспечение для машинного перевода использует обработку естественного языка для преобразования текста или речи с одного языка на другой с сохранением контекстуальной точности. Сервис AWS, поддерживающий машинный перевод, называется Amazon Translate.
Распознавание именованных объектов
Этот процесс идентифицирует уникальные имена для людей, мест, событий, компаний и многого другого. Программное обеспечение НЛП использует распознавание именованных объектов для определения отношений между различными объектами в предложении.
Программное обеспечение НЛП использует распознавание именованных объектов для определения отношений между различными объектами в предложении.
Рассмотрим следующий пример: «Джейн поехала в отпуск во Францию и побаловала себя местной кухней».
Программное обеспечение НЛП выберет «Джейн» и «Франция» в качестве особых сущностей в предложении. Это может быть дополнительно расширено за счет разрешения совместных ссылок, определяющего, используются ли разные слова для описания одного и того же объекта. В приведенном выше примере «Джейн» и «она» указывают на одного и того же человека.
Анализ настроений
Анализ настроений — это основанный на искусственном интеллекте подход к интерпретации эмоций, передаваемых текстовыми данными. Программное обеспечение НЛП анализирует текст на наличие слов или фраз, выражающих неудовлетворенность, счастье, сомнение, сожаление и другие скрытые эмоции.
Каковы подходы к обработке естественного языка?
Ниже мы приводим некоторые распространенные подходы к обработке естественного языка (NLP).
НЛП с учителем
Методы НЛП с учителем обучают программное обеспечение набором помеченных или известных входных и выходных данных. Сначала программа обрабатывает большие объемы известных данных и учится получать правильные выходные данные из любых неизвестных входных данных. Например, компании обучают инструменты НЛП классифицировать документы в соответствии с определенными метками.
Неконтролируемое НЛП
Неконтролируемое НЛП использует статистическую языковую модель для прогнозирования шаблона, который возникает при подаче немаркированного ввода. Например, функция автозаполнения в текстовых сообщениях предлагает релевантные слова, которые имеют смысл для предложения, отслеживая ответ пользователя.
Понимание естественного языка
Понимание естественного языка (NLU) — это подмножество НЛП, основное внимание в котором уделяется анализу смысла предложений. NLU позволяет программе находить похожие значения в разных предложениях или обрабатывать слова, имеющие разные значения.
Генерация естественного языка
Генерация естественного языка (NLG) фокусируется на создании разговорного текста, как это делают люди, на основе определенных ключевых слов или тем. Например, интеллектуальный чат-бот с возможностями NLG может общаться с клиентами так же, как и персонал службы поддержки.
Как AWS может помочь с вашими задачами НЛП?
AWS предоставляет самый широкий и полный набор сервисов искусственного интеллекта и машинного обучения (AI/ML) для клиентов с любым уровнем знаний. Эти сервисы подключены к обширному набору источников данных.
Для клиентов, которым не хватает навыков машинного обучения, которым нужно ускорить выход на рынок или которые хотят добавить интеллектуальные возможности в существующий процесс или приложение, AWS предлагает ряд языковых сервисов на основе машинного обучения. Это позволяет компаниям легко добавлять интеллектуальные функции в свои приложения ИИ с помощью предварительно обученных API для речи, транскрипции, перевода, анализа текста и функций чат-бота.
Вот список языковых сервисов AWS на основе машинного обучения:
- Amazon Comprehend помогает находить ценные сведения и взаимосвязи в тексте
- Amazon Transcribe выполняет автоматическое распознавание речи
- Amazon Translate свободно переводит текст
- Amazon Polly превращает текст в естественно звучащую речь
- Amazon Lex помогает создавать чат-ботов для взаимодействия с клиентами
- Amazon Kendra выполняет интеллектуальный поиск корпоративных систем, чтобы быстро находить нужный контент
Для клиентов, которые хотят создать стандартное решение для обработки естественного языка (NLP) в своем бизнесе, рассмотрите Amazon SageMaker . SageMaker упрощает подготовку данных, а также создание, обучение и развертывание моделей машинного обучения для любого варианта использования благодаря полностью управляемой инфраструктуре, инструментам и рабочим процессам, включая предложения без кода для бизнес-аналитиков.
С помощью Hugging Face в Amazon SageMaker можно развертывать и настраивать предварительно обученные модели от Hugging Face, поставщика моделей НЛП с открытым исходным кодом, известного как Transformers. Это сокращает время, необходимое для настройки и использования этих моделей НЛП, с недель до минут.
Начните работу с NLP, создав аккаунт AWS уже сегодня.
Что это такое и как это работает?
Обработка естественного языка (NLP) позволяет машинам разбивать и интерпретировать человеческий язык. Он лежит в основе инструментов, которые мы используем каждый день — от программного обеспечения для перевода, чат-ботов, спам-фильтров и поисковых систем до программного обеспечения для исправления грамматики, голосовых помощников и инструментов мониторинга социальных сетей.
Начните свое путешествие по НЛП с помощью инструментов без кода
ПОПРОБУЙТЕ СЕЙЧАС
В этом руководстве вы узнаете об основах обработки естественного языка и некоторых ее проблемах, а также узнаете о самых популярных приложениях NLP в бизнесе. Наконец, вы сами убедитесь, насколько легко начать работу с инструментами обработки естественного языка без кода.
Наконец, вы сами убедитесь, насколько легко начать работу с инструментами обработки естественного языка без кода.
- Что такое обработка естественного языка (NLP)?
- Как работает обработка естественного языка?
- Проблемы обработки естественного языка
- Примеры обработки естественного языка
- Обработка естественного языка с помощью Python
- Учебное пособие по обработке естественного языка (NLP)
Что такое обработка естественного языка (NLP)?
Обработка естественного языка (NLP) — это область искусственного интеллекта (ИИ), которая делает человеческий язык понятным для машин. НЛП сочетает в себе возможности лингвистики и информатики для изучения правил и структуры языка и создания интеллектуальных систем (работающих на основе машинного обучения и алгоритмов НЛП), способных понимать, анализировать и извлекать смысл из текста и речи.
Для чего используется НЛП?
НЛП используется для понимания структуры и значения человеческого языка путем анализа различных аспектов, таких как синтаксис, семантика, прагматика и морфология. Затем информатика преобразует эти лингвистические знания в основанные на правилах алгоритмы машинного обучения, которые могут решать конкретные проблемы и выполнять желаемые задачи.
Затем информатика преобразует эти лингвистические знания в основанные на правилах алгоритмы машинного обучения, которые могут решать конкретные проблемы и выполнять желаемые задачи.
Возьмем, к примеру, Gmail. Электронные письма автоматически классифицируются как Рекламные акции , Социальные , Основные или Спам благодаря задаче NLP, называемой извлечением ключевых слов. «Читая» слова в строках темы и связывая их с заранее определенными тегами, машины автоматически узнают, к какой категории отнести электронные письма.
Преимущества НЛП
НЛП обладает многими преимуществами, но вот лишь несколько преимуществ высшего уровня, которые помогут вашему бизнесу стать более конкурентоспособным:
- Выполняйте крупномасштабный анализ. Обработка естественного языка помогает машинам автоматически понимать и анализировать огромные объемы неструктурированных текстовых данных, таких как комментарии в социальных сетях, заявки в службу поддержки, онлайн-обзоры, новостные отчеты и многое другое.

- Автоматизируйте процессы в режиме реального времени. Инструменты обработки естественного языка могут помочь машинам научиться сортировать и направлять информацию практически без участия человека — быстро, эффективно, точно и круглосуточно.
- Адаптируйте инструменты NLP к своей отрасли. Алгоритмы обработки естественного языка могут быть адаптированы к вашим потребностям и критериям, таким как сложный, специфичный для отрасли язык — даже сарказм и неправильно используемые слова.
Как работает обработка естественного языка?
Используя векторизацию текста, инструменты НЛП преобразуют текст во что-то, что может понять машина, затем алгоритмы машинного обучения получают обучающие данные и ожидаемые выходные данные (теги), чтобы обучить машины проводить ассоциации между конкретным вводом и соответствующим ему выводом. Затем машины используют методы статистического анализа для создания своего собственного «банка знаний» и определяют, какие функции лучше всего представляют тексты, прежде чем делать прогнозы для невидимых данных (новых текстов):
В конечном счете, чем больше данных подается этим алгоритмам НЛП, тем точнее модели анализа текста будут.
Анализ настроений (показан на диаграмме выше) — одна из самых популярных задач НЛП, в которой модели машинного обучения обучаются классифицировать текст по полярности мнений (положительные, отрицательные, нейтральные и все промежуточные).
Попробуйте самостоятельно провести анализ настроений, набрав текст в модели НЛП ниже
Протестируйте с помощью собственного текста
Это лучший инструмент анализа настроений!!!Результаты
Positive99.1%
Самым большим преимуществом моделей машинного обучения является их способность обучаться самостоятельно, без необходимости определять правила вручную. Вам просто нужен набор соответствующих обучающих данных с несколькими примерами для тегов, которые вы хотите проанализировать. А с помощью передовых алгоритмов глубокого обучения вы можете объединять несколько задач обработки естественного языка, таких как анализ тональности, извлечение ключевых слов, классификация тем, обнаружение намерений и т. д., чтобы работать одновременно и получать очень подробные результаты.
д., чтобы работать одновременно и получать очень подробные результаты.
Общие задачи и методы НЛП
Многие задачи обработки естественного языка включают синтаксический и семантический анализ, используемый для разбиения человеческого языка на машиночитаемые фрагменты.
Синтаксический анализ , также известный как синтаксический анализ или синтаксический анализ, идентифицирует синтаксическую структуру текста и отношения зависимости между словами, представленные на диаграмме, называемой деревом синтаксического анализа.
Семантический анализ фокусируется на определении значения языка. Однако, поскольку язык многозначен и неоднозначен, семантика считается одной из самых сложных областей НЛП.
Семантические задания анализируют структуру предложений, взаимодействий слов и связанных с ними понятий в попытке раскрыть значение слов, а также понять тему текста.
Ниже мы перечислили некоторые из основных подзадач как семантического, так и синтаксического анализа:
Токенизация
Токенизация — важная задача обработки естественного языка, используемая для разбиения строки слов на семантически полезные единицы, называемые токены .
Токенизация предложений разделяет предложения в тексте, а токенизация слов разделяет слова внутри предложения. Как правило, токены слов разделяются пробелами, а токены предложений — точками. Однако вы можете выполнять высокоуровневую токенизацию для более сложных структур, таких как слова, которые часто встречаются вместе, иначе называемые словосочетаниями (например, New York ).
Пример того, как разбиение слов упрощает текст:
Вот пример того, как разбиение слов упрощает текст:
Обслуживание клиентов не может быть лучше! = «обслуживание клиентов» «не может» «не быть» «лучше».
Тегирование части речи
Тегирование части речи (сокращенно PoS-тегирование) предполагает добавление категории части речи к каждому маркеру в тексте. Некоторые общие теги PoS: глагол , прилагательное , существительное , местоимение , союз , предлог , пересечение и другие. В этом случае приведенный выше пример будет выглядеть так:
«Обслуживание клиентов»: СУЩЕСТВИТЕЛЬНОЕ, «может»: ГЛАГОЛ, «не»: НАРЕЧИЕ, быть»: ГЛАГОЛ, «лучше»: ПРИЛАГАТЕЛЬНОЕ, «!»: ПУНКТУАЦИЯ
Маркировка PoS полезна для определения отношений между словами и, следовательно, понимать смысл предложений.
Анализ зависимостей
Грамматика зависимостей относится к способу соединения слов в предложении. Таким образом, синтаксический анализатор зависимостей анализирует, как «главные слова» связаны и изменяются другими словами, а также понимает синтаксическую структуру предложения:
Анализ избирательного округа
Анализ избирательного округа направлен на визуализацию всей синтаксической структуры предложения путем определения грамматики структуры фразы. Он состоит из использования абстрактных терминальных и нетерминальных узлов, связанных со словами, как показано в этом примере:
Вы можете попробовать различные алгоритмы и стратегии синтаксического анализа в зависимости от характера текста, который вы собираетесь анализировать, и уровня сложности, который вы хотите анализировать. хотел бы достичь.
Лемматизация и стемминг
Когда мы говорим или пишем, мы склонны использовать флективные формы слова (слова в их различных грамматических формах). Чтобы сделать эти слова более понятными для компьютеров, НЛП использует лемматизацию и выделение корней, чтобы преобразовать их обратно в корневую форму.
Чтобы сделать эти слова более понятными для компьютеров, НЛП использует лемматизацию и выделение корней, чтобы преобразовать их обратно в корневую форму.
Слово в том виде, в каком оно появляется в словаре – его корневая форма – называется леммой. Например, термины «есть, есть, есть, были и были», группируются под леммой «быть». Итак, если мы применим эту лемматизацию к «У африканских слонов по четыре когтя на передних лапах», результат будет выглядеть примерно так:
У африканских слонов по четыре когтя на передних лапах = «африканский», «слон», «есть», «4», «гвоздь», «на», «их», «нога»]
Этот пример полезен, чтобы увидеть, как лемматизация изменяет предложение, используя его базовую форму (например, слово «ноги» было изменено на «нога»)
Когда мы говорим об основах, корневая форма слова называется основой.Определение основы «обрезает» слова, поэтому основы слов не всегда могут быть семантически правильными.
Например, если объединить слова «консультироваться», «консультант», «консалтинг» и «консультанты», получится корневая форма «консультироваться».
В то время как лемматизация основана на словаре и выбирает подходящую лемму в зависимости от контекста, выделение корней работает с отдельными словами без учета контекста. Например, в предложении:
«Это лучше»
Слово «лучше» преобразуется в слово «хорошо» с помощью лемматизатора, но не изменяется по корню. Несмотря на то, что стеммеры могут давать менее точные результаты, их проще построить и они работают быстрее, чем лемматизаторы. Но лемматизаторы рекомендуются, если вы ищете более точные лингвистические правила.
Удаление стоп-слов
Удаление стоп-слов — важный шаг в обработке текста НЛП. Он включает в себя отфильтровывание часто встречающихся слов, которые не добавляют семантической ценности предложению, например, that to, at, for, is, и т. д.
Вы даже можете настроить списки стоп-слов, включив в них слова, которые вы хочу игнорировать.
Предположим, вы хотите классифицировать обращения в службу поддержки клиентов по их темам. В этом примере: «Здравствуйте, у меня проблемы со входом в систему с моим новым паролем» , может быть полезно удалить стоп-слова, такие как «привет» , «я» , «ам» , «с» , «мой» , поэтому у вас останутся слова, которые помогите разобраться в теме тикета: «беда» , «вход» , «новый» , «пароль» .
В этом примере: «Здравствуйте, у меня проблемы со входом в систему с моим новым паролем» , может быть полезно удалить стоп-слова, такие как «привет» , «я» , «ам» , «с» , «мой» , поэтому у вас останутся слова, которые помогите разобраться в теме тикета: «беда» , «вход» , «новый» , «пароль» .
Значение слова Word Sense
В зависимости от контекста слова могут иметь разные значения. Возьмем слово «книга» , например:
- Вы должны прочитать эту книгу ; это отличный роман!
- Вам следует забронировать рейсы как можно скорее.
- Вы должны закрыть книг до конца года.
- Вы должны делать все по книге , чтобы избежать возможных осложнений.
Существуют два основных метода, которые можно использовать для устранения многозначности слов (WSD): основанный на знаниях (или словарный подход) или контролируемый подход . Первый пытается сделать вывод о значении, наблюдая словарные определения неоднозначных терминов в тексте, а второй основан на алгоритмах обработки естественного языка, которые извлекают уроки из обучающих данных.
Первый пытается сделать вывод о значении, наблюдая словарные определения неоднозначных терминов в тексте, а второй основан на алгоритмах обработки естественного языка, которые извлекают уроки из обучающих данных.
Распознавание именованных объектов (NER)
Распознавание именованных объектов является одной из самых популярных задач семантического анализа и включает в себя извлечение объектов из текста. Сущностями могут быть имена, места, организации, адреса электронной почты и многое другое.
Извлечение отношений, еще одна подзадача НЛП, идет еще дальше и находит отношения между двумя существительными. Например, во фразе «Сьюзен живет в Лос-Анджелесе» человек (Сьюзан) связан с местом (Лос-Анджелес) семантической категорией «живет в».
Классификация текста
Классификация текста — это процесс понимания значения неструктурированного текста и организации его в предопределенные категории (теги). Одной из самых популярных задач классификации текста является анализ тональности, целью которого является категоризация неструктурированных данных по тональности.
Другие задачи классификации включают обнаружение намерений, моделирование темы и определение языка.
Проблемы обработки естественного языка
Существует множество проблем обработки естественного языка, но одна из основных причин сложности НЛП заключается просто в том, что человеческий язык неоднозначен.
Даже людям трудно правильно анализировать и классифицировать человеческий язык.
Возьмем, к примеру, сарказм. Как научить машину понимать выражение, которое говорит противоположное истине? В то время как люди легко уловили бы сарказм в этом комментарии, ниже было бы сложно научить машину интерпретировать эту фразу:
«Если бы мне давали по доллару за каждую умную вещь, которую вы говорите, я был бы беден».
Чтобы полностью понять человеческий язык, специалистам по обработке и анализу данных необходимо научить инструменты НЛП не ограничиваться определениями и порядком слов, понимать контекст, двусмысленность слов и другие сложные понятия, связанные с сообщениями. Но им также необходимо учитывать другие аспекты, такие как культура, происхождение и пол, при тонкой настройке моделей обработки естественного языка. Сарказм и юмор, например, могут сильно различаться в разных странах.
Но им также необходимо учитывать другие аспекты, такие как культура, происхождение и пол, при тонкой настройке моделей обработки естественного языка. Сарказм и юмор, например, могут сильно различаться в разных странах.
Обработка естественного языка и мощные алгоритмы машинного обучения (часто несколько совместно используемых) совершенствуются и упорядочивают хаос человеческого языка, вплоть до таких понятий, как сарказм. Мы также начинаем видеть новые тенденции в НЛП, поэтому мы можем ожидать, что НЛП произведет революцию в способах взаимодействия людей и технологий в ближайшем будущем и в будущем.
Примеры обработки естественного языка
Хотя обработка естественного языка продолжает развиваться, сегодня уже существует множество способов ее использования. Большую часть времени вы будете подвергаться обработке естественного языка, даже не осознавая этого.
Часто НЛП работает в фоновом режиме с инструментами и приложениями, которые мы используем каждый день, помогая компаниям улучшить наш опыт. Ниже мы выделили некоторые из наиболее распространенных и наиболее эффективных способов использования обработки естественного языка в повседневной жизни:
Ниже мы выделили некоторые из наиболее распространенных и наиболее эффективных способов использования обработки естественного языка в повседневной жизни:
11 распространенных примеров НЛП
- Фильтры электронной почты
- Виртуальные помощники, голосовые помощники или умные колонки
- Онлайн-поиск двигатели
- Предиктивный текст и автозамена
- Отслеживание настроений бренда в социальных сетях
- Сортировка отзывов клиентов
- Автоматизация процессов в службе поддержки
- Чат-боты
- Автоматическое обобщение
- Машинный перевод
- Генерация естественного языка использования НЛП. Когда они были впервые представлены, они были не совсем точными, но благодаря многолетнему обучению машинному обучению на миллионах выборок данных электронные письма в наши дни редко попадают не в тот почтовый ящик.
Виртуальные помощники, голосовые помощники или умные колонки
Наиболее распространенными из них являются Siri от Apple и Alexa от Amazon.
 Виртуальные помощники используют технологию машинного обучения NLP для понимания и автоматической обработки голосовых запросов. Алгоритмы обработки естественного языка позволяют индивидуально обучать помощников отдельными пользователями без дополнительного ввода, учиться на предыдущих взаимодействиях, вызывать связанные запросы и подключаться к другим приложениям.
Виртуальные помощники используют технологию машинного обучения NLP для понимания и автоматической обработки голосовых запросов. Алгоритмы обработки естественного языка позволяют индивидуально обучать помощников отдельными пользователями без дополнительного ввода, учиться на предыдущих взаимодействиях, вызывать связанные запросы и подключаться к другим приложениям.Ожидается, что использование голосовых помощников будет продолжать расти в геометрической прогрессии, поскольку они используются для управления домашними системами безопасности, термостатами, освещением и автомобилями — даже чтобы вы знали, что у вас заканчивается в холодильнике.
Онлайн-поисковики
Всякий раз, когда вы выполняете простой поиск в Google, вы используете машинное обучение НЛП. Они используют хорошо обученные алгоритмы, которые ищут не только связанные слова, но и намерения искателя. Результаты часто меняются ежедневно, следуя трендовым запросам и трансформируясь вместе с человеческим языком.
 Они даже учатся предлагать темы и предметы, связанные с вашим запросом, которые, возможно, даже не осознавали, что вас интересуют.
Они даже учатся предлагать темы и предметы, связанные с вашим запросом, которые, возможно, даже не осознавали, что вас интересуют.Предиктивный текст
Каждый раз, когда вы печатаете текст на своем смартфоне, вы видите НЛП в действии. Часто вам нужно набрать всего несколько букв слова, и приложение для обмена текстовыми сообщениями предложит вам правильный вариант. И чем больше вы пишете, тем точнее он становится, часто распознавая часто используемые слова и имена быстрее, чем вы можете их напечатать.
Интеллектуальный текст, автозамена и автозаполнение стали настолько точными в программах обработки текстов, таких как MS Word и Google Docs, что они могут заставить нас чувствовать, что нам нужно вернуться в начальную школу.
Мониторинг настроений бренда в социальных сетях
Анализ настроений — это автоматизированный процесс классификации мнений в тексте как положительных, отрицательных или нейтральных. Его часто используют для отслеживания настроений в социальных сетях.
 Вы можете отслеживать и анализировать настроения в комментариях о вашем бренде в целом, продукте, конкретной функции или сравнивать свой бренд с конкурентами.
Вы можете отслеживать и анализировать настроения в комментариях о вашем бренде в целом, продукте, конкретной функции или сравнивать свой бренд с конкурентами.Представьте, что вы только что выпустили новый продукт и хотите определить первоначальную реакцию ваших клиентов. Возможно, клиент написал в Твиттере о своем недовольстве обслуживанием клиентов. Отслеживая анализ настроений, вы можете сразу обнаружить эти негативные комментарии и немедленно ответить.
Быстрая сортировка отзывов клиентов
Классификация текста — это основная задача НЛП, которая назначает предопределенные категории (теги) тексту на основе его содержания. Он отлично подходит для организации качественной обратной связи (обзоры продуктов, обсуждения в социальных сетях, опросы и т. д.) по соответствующим темам или категориям отделов.
Retently, платформа SaaS, использовала инструменты НЛП для классификации ответов NPS и мгновенного получения полезной информации:
Retently обнаружила наиболее актуальные темы, упомянутые клиентами, и какие из них они больше всего ценят.
 Ниже вы можете видеть, что большинство ответов относились к «функциям продукта», за которыми следуют «UX продукта» и «поддержка клиентов» (последние две темы были упомянуты в основном промоутерами).
Ниже вы можете видеть, что большинство ответов относились к «функциям продукта», за которыми следуют «UX продукта» и «поддержка клиентов» (последние две темы были упомянуты в основном промоутерами).Автоматизация процессов обслуживания клиентов
Другие интересные применения НЛП связаны с автоматизацией обслуживания клиентов. Эта концепция использует технологию на основе искусственного интеллекта для устранения или сокращения рутинных ручных задач в службе поддержки клиентов, экономя драгоценное время агентов и повышая эффективность процессов.
Согласно бенчмарку Zendesk, технологическая компания получает +2600 запросов в службу поддержки в месяц. Получение большого количества обращений в службу поддержки по разным каналам (электронная почта, социальные сети, чат и т. д.) означает, что компаниям необходимо иметь стратегию классификации каждого поступающего обращения.
Классификация текста позволяет компаниям автоматически маркировать входящие запросы в службу поддержки клиентов в соответствии с их темой, языком, настроением или срочностью.
 Затем на основе этих тегов они могут мгновенно направлять заявки наиболее подходящему пулу агентов.
Затем на основе этих тегов они могут мгновенно направлять заявки наиболее подходящему пулу агентов.Uber разработала собственный рабочий процесс маршрутизации билетов, который включает в себя маркировку билетов по стране, языку и типу (эта категория включает вложенные теги Водитель-партнер, вопросы о платежах, потерянных предметах и т. д. ), и в соответствии с некоторыми правилами приоритизации, такими как отправка запросов от новых клиентов ( New Driver-Partners ), отправляются в начало списка.
Чат-боты
Чат-бот — это компьютерная программа, имитирующая человеческий разговор. Чат-боты используют NLP, чтобы распознавать смысл предложения, определять релевантные темы и ключевые слова, даже эмоции, и предлагать лучший ответ на основе своей интерпретации данных.
Поскольку клиенты жаждут быстрой, персонализированной и круглосуточной поддержки, чат-боты стали героями стратегий обслуживания клиентов. Чат-боты сокращают время ожидания клиентов, предоставляя немедленные ответы, и особенно хорошо справляются с обработкой рутинных запросов (которые обычно представляют собой наибольший объем запросов в службу поддержки клиентов), позволяя агентам сосредоточиться на решении более сложных проблем.
 На самом деле, чат-боты могут решить до 80% обычных запросов в службу поддержки клиентов.
На самом деле, чат-боты могут решить до 80% обычных запросов в службу поддержки клиентов.Помимо поддержки клиентов, чат-боты могут использоваться для рекомендации продуктов, предоставления скидок и бронирования, а также для многих других задач. Для этого большинство чат-ботов следуют простой логике «если/то» (они запрограммированы так, чтобы определять намерения и связывать их с определенным действием) или предоставляют набор вариантов на выбор.
Автоматическое суммирование
Автоматическое суммирование заключается в сокращении текста и создании новой краткой версии, содержащей наиболее важную информацию. Это может быть особенно полезно для суммирования больших фрагментов неструктурированных данных, таких как научные статьи.
Существует два разных способа использования НЛП для обобщения:
- Извлечение наиболее важной информации из текста и использование ее для создания резюме (резюмирование на основе извлечения)
- Применение методов глубокого обучения для перефразирования текста и создавать предложения, которых нет в первоисточнике (обобщение на основе абстракции) .
Автоматическое суммирование может быть особенно полезным для ввода данных, когда необходимая информация извлекается, например, из описания продукта и автоматически вводится в базу данных.
Машинный перевод
Возможность перевода текста и речи на разные языки всегда была одним из основных интересов в области НЛП. Начиная с первых попыток перевода текста с русского на английский в 1950-х годах и заканчивая современными нейронными системами глубокого обучения, машинный перевод (МТ) претерпел значительные улучшения, но по-прежнему сопряжен с проблемами.
Google Translate, Microsoft Translator и приложение для перевода Facebook — это лишь некоторые из ведущих платформ для универсального машинного перевода. В августе 2019 г., Модель машинного перевода Facebook AI с английского на немецкий заняла первое место в конкурсе, проводимом Конференцией по машинному обучению (WMT). Переводы, полученные с помощью этой модели, были определены организаторами как «сверхчеловеческие» и признаны намного превосходящими переводы, выполненные экспертами-людьми.
Еще одна интересная разработка в области машинного перевода связана с настраиваемыми системами машинного перевода, адаптированными к конкретной области и обученными понимать терминологию, связанную с определенной областью, такой как медицина, юриспруденция и финансы. Lingua Custodia, например, представляет собой инструмент машинного перевода, предназначенный для перевода технических финансовых документов.
Наконец, одно из последних нововведений машинного перевода — адаптивный машинный перевод, состоящий из систем, способных учиться на исправлениях в режиме реального времени.
Генерация естественного языка
Генерация естественного языка (NLG) — это подраздел НЛП, предназначенный для создания компьютерных систем или приложений, которые могут автоматически создавать все виды текстов на естественном языке, используя семантическое представление в качестве входных данных. Некоторые из приложений NLG — это ответы на вопросы и обобщение текста.
В 2019 году компания Open AI, занимающаяся искусственным интеллектом, выпустила GPT-2, систему генерации текста, которая представляет собой новаторское достижение в области ИИ и выводит область NLG на совершенно новый уровень.
Система была обучена на огромном наборе данных из 8 миллионов веб-страниц и способна генерировать связные и высококачественные фрагменты текста (например, новостные статьи, рассказы или стихи) с минимальными подсказками.Модель работает лучше, когда в нее входят популярные темы, широко представленные в данных (такие как Brexit, например), в то время как она дает худшие результаты, когда запрашивается узкоспециализированный или технический контент. Тем не менее, его возможности только начинают изучаться.
Обработка естественного языка с помощью Python
Теперь, когда вы получили некоторое представление об основах НЛП и его текущих приложениях в бизнесе, вам может быть интересно, как применить НЛП на практике.
Существует множество библиотек с открытым исходным кодом, предназначенных для обработки естественного языка. Эти библиотеки бесплатны, гибки и позволяют вам создать полное и индивидуальное решение NLP.
Однако создание целой инфраструктуры с нуля требует многолетнего опыта работы с данными и программирования, или вам, возможно, придется нанять целые команды инженеров.
SaaS-инструменты, с другой стороны, представляют собой готовые к использованию решения, которые позволяют вам интегрировать НЛП в инструменты, которые вы уже используете, просто и с минимальной настройкой. Подключить инструменты SaaS к вашим любимым приложениям через их API очень просто, для этого требуется всего несколько строк кода. Это отличная альтернатива, если вы не хотите тратить время и ресурсы на изучение машинного обучения или НЛП.
Взгляните на дебаты «Создать или купить», чтобы узнать больше.
Вот список лучших инструментов НЛП:
- MonkeyLearn — это платформа SaaS, которая позволяет создавать настраиваемые модели обработки естественного языка для выполнения таких задач, как анализ настроений и извлечение ключевых слов. Разработчики могут подключать модели NLP через API в Python, а те, у кого нет навыков программирования, могут загружать наборы данных через интеллектуальный интерфейс или подключаться к повседневным приложениям, таким как Google Sheets, Excel, Zapier, Zendesk и другим.
- Natural Language Toolkit (NLTK) — это набор библиотек для создания программ Python, которые могут решать самые разные задачи NLP. Это самая популярная библиотека Python для НЛП, за ней стоит очень активное сообщество, и она часто используется в образовательных целях. Существует руководство и учебник по использованию NLTK, но это довольно крутая кривая обучения.
- SpaCy — бесплатная библиотека с открытым исходным кодом для расширенной обработки естественного языка в Python. Он был специально разработан для создания приложений НЛП, которые могут помочь вам понять большие объемы текста.
- TextBlob — это библиотека Python с простым интерфейсом для выполнения различных задач НЛП. Созданная на основе NLTK и другой библиотеки под названием Pattern, она интуитивно понятна и удобна для пользователя, что делает ее идеальной для начинающих. Узнайте больше о том, как использовать TextBlob и его функции.
Учебное пособие по обработке естественного языка
Решения SaaS, такие как MonkeyLearn, предлагают готовые к использованию шаблоны NLP для анализа определенных типов данных.
В этом руководстве ниже мы покажем вам, как выполнять анализ тональности в сочетании с извлечением ключевых слов с использованием нашего индивидуального шаблона.1. Выберите ключевое слово + шаблон анализа тональности
2. Загрузите текстовые данные
Если у вас нет файла CSV, используйте наш пример набора данных.
3. Сопоставьте столбцы CSV с полями панели мониторинга
В этом шаблоне есть только одно поле: текст . Если в вашем наборе данных несколько столбцов, выберите столбец с текстом, который вы хотите проанализировать.
4. Назовите свой рабочий процесс
5. Дождитесь импорта данных
6. Изучите панель управления!
Вы можете:
- Фильтровать по настроению или ключевому слову.
- Поделитесь по электронной почте с другими коллегами.
Заключительные слова об обработке естественного языка
Обработка естественного языка меняет способ анализа и взаимодействия с языковыми данными с помощью обучающих машин, чтобы понимать текст и речь и выполнять автоматизированные задачи, такие как перевод, обобщение, классификация и добыча.
