Что такое книжка МДП и как ее оформить
Система транспортировки грузов, значительно сокращающая время пересечения границ транзитных государств, была создана в рамках Конвенции о международной перевозке грузов с применением книжки МДП. Первые инициативы состоялись еще в 1949 г. и только в 1975 г. с учетом приобретенного опыта и новых законов была разработана современная версия Конвенции. Документ вступил в силу в 1978 г. и до сих пор утверждает единственную глобальную систему таможенного транзита более, чем в 50 странах мира.
Книжка МДП обеспечивает безопасность транспортных средств и контейнеров, контролируемый доступ к перевозимому грузу, взаимное признание правил всеми странами, подписавшими документ. Позволяет перевозчику обходиться без национальных таможенных документов и национальных гарантий уплаты таможенных сборов.
Что такое книжка МДП?
Расшифровка аббревиатуры МДП: Международные Дорожные Перевозки. Аналогичный термин на английском языке звучит TIR.
Таким образом, Carnet TIR упрощает таможенную процедуру, сокращает временные издержки, связанные с прохождением границ. Документ используется для платежа таможенных сборов, а также в случаях необходимости страхования ущерба, возникшего во время следования груза по международному маршруту. Подтверждает завершение перевозки. Существует электронная система, которая предоставляет возможность отслеживать книгу на маршруте следования груза, поэтому события, отраженные в документе, могут быть легко проверены сотрудниками таможен. Подробное описание в книжке каждого прохождения границы в последствие упрощает расследование претензий, споров и конфликтных ситуаций.
Представляет собой блокнот с отрывными и неотрывными цветными листами:
- темно-желтые – обложка, которая содержит правила пользования книжкой и штамп с датой завершения срока действия;
- желтые — грузовой манифест, содержащий данные с отрывных листов, (его таможенные службы не используют), и протокол о ДТП, который заполняется при необходимости;
- белые и зеленые (с корешками, предназначенные для отрывания) – они открывают и закрывают процедуру на одной таможне.
В целом книжка издается на французском языке. Только надписи на лицевой стороне обложки дублируются на английском. В заполненном варианте документ должен содержать информацию о странах отправления и назначения, таможне отправления и назначения, последовательности прохождения транзитных таможен и их отметки, данные о грузе с описанием и кодом ТЕ ВЭД, а также о транспортном средстве, выполняющем доставку. Указывается количество грузовых мест, и приводится список сопроводительных документов.
Книжка вместе с транспортным средством (контейнерами) представляется в каждой таможне (отправления, назначения и транзитных).
Согласно конвенции МДП срок действия книжки не может быть больше 75 дней, начиная от даты ее выдачи. Даже в последний день действия документа еще можно открыть ТИР и начать транспортировку. Книжка будет действовать, пока перевозка не завершится в таможне назначения.
Виды книжек
Книжки МДП выдаются с разным количеством листов. Выбор зависит от количества таможенных поцедур, запланированных на маршруте перевозки. Стандартные варианты блокнотов содержат 20, 14, 6 или 4 листа.
Важно! Используется по 2 листа на каждую таможню отправления, каждую транзитную страну и каждую таможню назначения. В дополнение в книжке должно остаться еще 2 листа.
Оформление книжки МДП
Для одного транспортного средства или одного состава транспортных средств книжка МДП заполняется шариковой ручкой только в одном экземпляре непосредственно владельцем (перевозчиком), работником таможни, сотрудником АСМАП.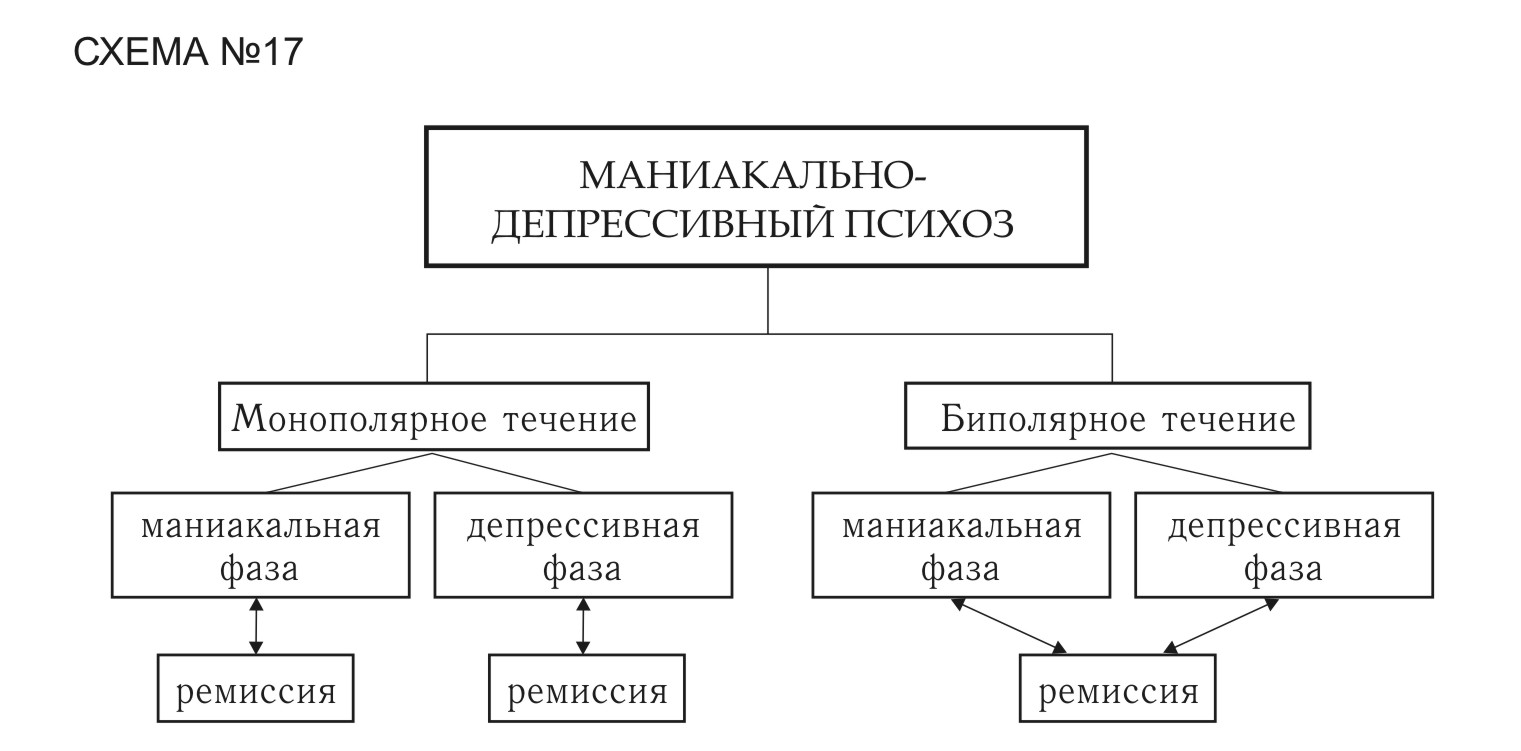
Темно-желтая обложка заполняется АСМАП в момент выдачи документа и перевозчиком. Грузовой манифест дублирует всю информацию отрывных листов и заполняется владельцем с предельной аккуратностью, чтобы информация соответствовала данным в транспортных документах и отрывных листах. Бланк манифеста содержит обязательные реквизиты:
- номер и срок действия книжки;
- наименование гарантийного органа, выдавшего книжку;
- реквизиты перевозчика, который является владельцем книжки;
- маршрут следования с указанием страны отправления и назначения;
- регистрационный номер транспортного средства и свидетельства о его допущении, номер контейнера или грузовых отделений с указанием количества, вида и номеров грузовых мест;
- описание груза, его вес, коды ТН ВЭД.
Белые и зеленые листы заполняются сотрудником таможни. Корешок белого цвета предназначен для таможни отправления и ввоза стран транзита и назначения. Корешок зеленого цвета – для таможни вывоза или назначения. Если книжка МДП задерживается, то используется отрывная часть задней обложки, которая выдается перевозчику в качестве подтверждения ее наличия.
Корешок зеленого цвета – для таможни вывоза или назначения. Если книжка МДП задерживается, то используется отрывная часть задней обложки, которая выдается перевозчику в качестве подтверждения ее наличия.
Где можно получить книжку МДП?
Книжку выдает представительство IRU страны-участницы конвенции TIR в России – это АСМАП (Ассоциация международных автомобильных перевозчиков). Чтобы получить Carnet TIR, заявитель должен иметь разрешение ФТС на выполнение международных перевозок грузов, оплатить соответствующий взнос, быть аккредитованным АСМАП и получить специальный сертификат на автотранспорт для международных грузоперевозок.
Особенности применения TIR в России
После распада СССР Россия стала правопреемником союза, который присоединился к Конвенции в 1982 г. Сегодня за внедрение системы МДП несет ответственность Ассоциация Международных Автомобильных Перевозчиков (АСМАП). С 2013 г. в РФ действие книжки значительно ограничили, так как ФТС не считало книжку способной предоставить достаточное обеспечение для уплаты таможенных сборов.
Важно! АСМАП гарантирует выплату таможенных платежей, если сумма не превышает 60 тыс. евро. В остальных случаях перевозчик должен вносить гарантийное обеспечение.
Какие грузы запрещено перевозить, используя книжку МДП?
Есть общепринятые в мире правила, согласно которым с книжкой МДП нельзя перевозить спирт (в т.ч. спиртсодержащую продукцию за исключением вина и пива) и табак (в т.ч. изделия из него кроме табака-сырца).
Для стран Европейского союза существуют дополнительные ограничения:
- молоко, сливки, молочные продукты, молочные жиры и масло;
- замороженное мясо крупного рогатого скота;
- сахар из тростника или свеклы;
- бананы (свежие и сушеные).
Проверка книжки МДП
Статус книжки МДП может быть легко проверен в любой момент следования по маршруту. Документ отслеживается в реальном времени с помощью специального приложения SafeTIR, разработанного IRU. SafeTIR позволяет:
Документ отслеживается в реальном времени с помощью специального приложения SafeTIR, разработанного IRU. SafeTIR позволяет:
- подтвердить завершение МДП перевозки;
- проверить документ в полном объеме;
- найти нарушения процедуры и устранить их;
- выявить и предупредить риски, которые могут быть вызваны ошибкой в документе, во время следования груза по маршруту.
Данные обычно загружаются за сутки, после чего к информации открывается доступ перевозчику, таможенным органам, уполномоченным сотрудникам организации, которая выдала книжку, страховым компаниям. Если выявляются нарушения процедуры МДП, то перевозчик обязан выплатить компенсацию АСМАП.
Правила заполнения книжки МДП
Книжка МДП может быть заполнена непосредственно владельцем в той части, в которой она должна быть им заполнена. Существуют подробные инструкции, которые помогут разобраться с многочисленными разделами. Но поскольку к точности и аккуратности заполнения документа предъявляются строгие требования, то рекомендуется делегировать функцию экспедиторам или таможенным брокерам, работающим на каждом таможенном пункте.
Если ошибка допущена, то исправления выполняются посредством вычеркивания некорректно внесенной информации и заверяются таможенной печатью. Если не выполнить одно из условий, то книжка становится недействительной.
Грузовой манифест заполняется на языке страны отправления (таможня может разрешить заполнять на другом языке). Данные впечатываются или вписываются разборчиво, чтобы легко читались. Иногда представители таможенных органов могут потребовать перевести манифест на национальный язык их государства, поэтому перевозчику лучше подготовить качественные переводы и иметь их при себе.
Парные белые и зеленые листки отрываются и заполняются сотрудниками таможни, а корешки остаются в книжке. Все отрывные листы должны быть подписаны владельцем книжки или его представителем. Первый лист отрывается в стране отправления после того, как осмотрен, опечатан и опломбирован груз. Второй лист отрывается, когда груз выезжает за пределы таможенной территории страны отправления. После выполнения доставки заполненная книжка МДП должна быть сдана в гарантийное объединение АСМАП.
Второй лист отрывается, когда груз выезжает за пределы таможенной территории страны отправления. После выполнения доставки заполненная книжка МДП должна быть сдана в гарантийное объединение АСМАП.
Важно! Если во время транспортировки повредились таможенные пломбы и/или нанесен ущерб грузу, перевозчик должен обратиться в ближайший таможенный орган (или в другую компетентную организацию). Его сотрудники должны составить протокол, который остается в книжке МДП до доставки груза в таможню назначения.
Образец книжки
Образец с расшифровкой книжки МДП, который можно скачать здесь, поможет самостоятельно заполнить бланки.
Больше примеров заполнения на официальном сайте ASMAP
Ошибки при заполнении и штрафы
Таможенные органы тщательно контролируют заполнение книжки с соблюдением требований Конвенции. Важна не только точность данных, но и аккуратность их введения.
Если будут выявлены ошибки в книжке МДП, допущенные даже таможенными органами других стран до того, как груз поступил на таможенную территорию РФ, то груз невозможно будет ввести на территорию России. Ошибки подлежат исправлению. Старые данные должны быть вычеркнуты, а точная информация дописана на всех соответствующих листах МДП. Внесенные изменения необходимо заверить сотрудником таможни, который оформлял TIR, и перевозчиком. За указание неверных данных и другие неисправленные ошибки выписывают штраф. Документы переоформляются, а груз, на время исправления ошибок, может быть задержан.
Ошибки подлежат исправлению. Старые данные должны быть вычеркнуты, а точная информация дописана на всех соответствующих листах МДП. Внесенные изменения необходимо заверить сотрудником таможни, который оформлял TIR, и перевозчиком. За указание неверных данных и другие неисправленные ошибки выписывают штраф. Документы переоформляются, а груз, на время исправления ошибок, может быть задержан.
+7 (423) 205-60-10, +7 (423) 205-60-20, [email protected]
Получить расчетЗадать вопрос
Что такое Carnet TIR, или Книжка МДП?
Carnet TIR (МДП «международные дорожные перевозки») представляет собой транспортный документ, оформляемый на одну перевозку и позволяющий облегчить, ускорить прохождения границ в системе международных перевозок (универсальной транзитной системе). С помощью данного документа транзит грузов из страны отправления в страну назначения выполняется под таможенными пломбами и печатями. Перевозка грузов с применением книжки МДП может подвергаться таможенному контроля на протяжении всего пути доставки автомобильным транспортом.
1. Что такое Carnet TIR, или Книжка МДП? Как работает система МДП?
МДП — универсальная транспортная система, разработанная в Европе для упрощения торговли и транспортного сообщения. Ее задача — максимально снизить административные и финансовые затраты, обеспечить странам-участницам международную гарантию оплаты пошлин и налогов, страхование товаров от транспортных рисков.
Применение книжек МДП Carnet TIR производится на территории стран-участниц Конвенции МДП с 1975 года. Сегодня в число членов входит 43 страны. Россия выступает полноправным членом Конвенции. Однако в связи с некоторыми разногласиями с ЕЭК ОНН с 2013 года на практике действие книжек МДП в РФ ограничено.
За развитие МДП отвечает МСАТ или IRU (Международный Союз Автомобильного Транспорта). В Российской Федерации данную функцию выполняет АСМАП (Ассоциация Международных Автомобильных Перевозок). Кто выдает TIR Carnet? Книжки МДП (ТИР) можно получить в представительствах IRU стран-участниц Конвенции TIR, а в РФ документы выдаются АСМАП.
2. Как выглядит TIR Carnet или книжка МДП
Carnet TIR — что это такое в грузоперевозках? Это блокнот большого формата с отрывными листами, позволяющий застраховать риски, связанные с международными перевозками. Документ имеет следующую структуру:
обложка книжки темно-желтого цвета,
грузовой манифест желтого цвета (книжка МДП не применяется для таможенных целей),
белые и зеленые парные отрывные листы с корешками,
протокол,
задняя сторона обложки, имеющая отрывную часть.
Книжка МДП содержит уникальный номер, включающий 2 латинские буквы и 7 цифр. Срок действия TIR Carnet (книжки МДП Карнет) указывается на обложке блокнота в виде штампа. Данная дата отражает, когда можно в последний раз открыть ТИР и начать процедуру международной дорожной перевозки.
Важно! Чтобы стать полноправным участником международных автомобильных перевозок по системе МДП, необходимо получить допуск в ФТС. Далее транспортная инспекция выдает на каждый тягач карточку допуска. Чтобы стать аккредитованным членом АСМАП необходимо заплатить взнос и получить таможенное свидетельство на прицепы. Все применяемые транспортные средства должны пройти сертификацию для международных грузоперевозок.
Далее транспортная инспекция выдает на каждый тягач карточку допуска. Чтобы стать аккредитованным членом АСМАП необходимо заплатить взнос и получить таможенное свидетельство на прицепы. Все применяемые транспортные средства должны пройти сертификацию для международных грузоперевозок.
Образец книжки МДП
Таможенные органы имеют право проводить национальные процедуры контроля. В случае обнаружения серьезных нарушений (повреждений пломб, полного/частичного уничтожения грузов и пр.), заполняется протокол книжки МДП. На основании данного документа таможня может инициировать расследование.
3. Грузовой манифест TIR Carnet
TIR Carnet содержит основные данные по международной перевозке груза:
очередность прохождения таможенных пунктов;
таможню отправления, таможню назначения;
сведения по грузам: коды ТН ВЭД, описание, масса брутто/нетто, число грузовых мест;
номера и список, накладных и других товаросопроводительных и транспортных документов;
количество грузовых мест с указанием таможни, на которую должны быть доставлены данные товары;
регистрационный номер транспорта, с помощью которого выполняется международная автомобильная перевозка;
печати, номера наложенных пломб и другие отметки таможни.

Для правильного заполнения книжки МДП Carnet Tir необходимо внимательно проанализировать инвойсы, упаковочные листы, CMR и пр. Запрещается допускать какие-либо помарки, имеющие двойное толкование данных. В книжке МДП не должно быть ошибок. Исправления допускаются только путем вычеркивания ошибочных данных с последующим заверением печати таможни. Иначе ТИР недействителен.
Документ может содержать 4, 6, 14, 20 листов, в зависимости от количества процедур МДП, которые следует открывать/закрывать за перевозку. При выборе книжки ТИР важно знать маршрут и понимать принцип выполнения перевозки. Это позволит понять на сколько листов должен быть документ.
4. Как работает Книжка МДП
По мере прохождения таможенных пунктов из книги последовательно удаляются листы. Корешки в блокноте остаются. Листы книжки МДП считаются парами (белые, зеленые). Первый лист означает, что ТИР открыт (груз взят под национальный контроль), второй — закрыт (груз вышел из-под национального таможенного контроля и процедура завершена). Если в блокноте нечетное количество корешков, это говорит о том, что ТИР не закрыт. Открытие TIR не означает фактическое начало грузоперевозки, а закрытие TIR — ее завершение. Особенность перевозки грузов с применением книжки МДП заключается в том, что транспортировка продукции до ее оформления и после ее завершения может идти по другой процедуре.
Если в блокноте нечетное количество корешков, это говорит о том, что ТИР не закрыт. Открытие TIR не означает фактическое начало грузоперевозки, а закрытие TIR — ее завершение. Особенность перевозки грузов с применением книжки МДП заключается в том, что транспортировка продукции до ее оформления и после ее завершения может идти по другой процедуре.
На каждую таможенную зону приходится четное число данных листков. Выехать за пределы зоны с открытым TIR нельзя — он должен быть закрыт для этой зоны. При планировании грузоперевозки важно помнить, что независимо от количества листов в книге таможен назначения должно быть не больше 3-х. В книжке МДП для таможен предусмотрено только 4 графы, в том числе, для таможни отправления. Важно правильно указывать последовательность таможенных пунктов. В противном случае можно совершить административное правонарушение.
5. Как работает система МДП в России
С 2013 года действие TIR в Российской Федерации сильно ограничено, причем именно в импортной сфере. Причиной стал конфликт, разразившийся между АСМАП и ФТС РФ. В итоге ФТС заявила о том что независимо от стоимости, TIR в России признается недостаточной мерой обеспечения уплаты сборов. При этом в таких странах Таможенного союза, как Беларусь и Казахстан, TIR действует без ограничений. Получается, что при ввозе товаров в Россию таможня работает с TIR на закрытие.
Причиной стал конфликт, разразившийся между АСМАП и ФТС РФ. В итоге ФТС заявила о том что независимо от стоимости, TIR в России признается недостаточной мерой обеспечения уплаты сборов. При этом в таких странах Таможенного союза, как Беларусь и Казахстан, TIR действует без ограничений. Получается, что при ввозе товаров в Россию таможня работает с TIR на закрытие.
При наличии книжки МДП Carnet TIR можно доехать до первой точки в РФ (до границы или таможни назначения — внутреннего таможенного поста). При заходе в Россию ТИР закрывается на границе. Если заход осуществляется через сопредельные государства ТС (например, Беларусь), после прохождения первого таможенного поста в России (внутреннего или пограничного) производится закрытие ТИРа. Для следующих пунктов на доставку нужно оформлять транзитные декларации и предоставить гарантию уплаты пошлин.
6. Сложности на российской границе
Возможна ситуация, при которой перевозчик, следующий в Россию, по пути встречает таможенный конвой по Беларуси. Конвой доводит перевозка до первой российской таможни, а не до таможни назначения. Как правило, это один из постов на российско-белорусской границе. Здесь происходит принудительное закрытие ТИР. Никакие уговоры на сотрудников таможни не действуют, а результате перевозчик «прогорает». Получается что он даже не доехал до первой российской таможни назначения, а ТИРа уже нет, и непонятно по какой таможенной процедуре следовать далее. И это при том, что он специально ехал через Беларусь, чтобы избежать проблем с TIR. Перевозчику приходится заполнять транзитную декларацию и предоставлять гарантийные обязательства уплаты сборов.
Конвой доводит перевозка до первой российской таможни, а не до таможни назначения. Как правило, это один из постов на российско-белорусской границе. Здесь происходит принудительное закрытие ТИР. Никакие уговоры на сотрудников таможни не действуют, а результате перевозчик «прогорает». Получается что он даже не доехал до первой российской таможни назначения, а ТИРа уже нет, и непонятно по какой таможенной процедуре следовать далее. И это при том, что он специально ехал через Беларусь, чтобы избежать проблем с TIR. Перевозчику приходится заполнять транзитную декларацию и предоставлять гарантийные обязательства уплаты сборов.
После закрытия ТИРа на открытие новой процедуры транзита на таможне дается не более 3-х часов. Если в этот срок перевозчик не успевает оформить документы, груз отправляется на СВХ. Дальнейшее развитие ситуации может быть следующим — транспорт помещается на платную стоянку или продукция выгружается на склад, затем выполняется оформление груза снова, с дополнительной оплатой таможенных платежей.
Если для груза предусмотрены дополнительные меры контроля со стороны таможни, например, перевозчик отправляется в Казахстан, он несет дополнительные временные и денежные затраты. До 2013 года подобных ситуаций не возникало. МСАТ и АСМАП надеются исправить ситуацию и восстановить прежнее действие книжек МДП в России.
7. Гарантийные ограничения
Книжка МДП не является универсальным решением в сфере международных автоперевозок. Согласно Конвенции МСАТ и АСМАП гарантируют оплату таможенных сборов на сумму до 60 000 евро. Если размеры таможенных сборов превышает эту цифру, ТИР не действует, и требуется предоставление дополнительного гарантийного обеспечения.
В Белоруссии это таможенный конвой, стоимость которого около 300 долларов США, за эту сумму сопровождает транспорт по территории Беларуси до границы с РФ.
В России применяются гарантийные поручительства, гарантии, сертификаты. Оформление данных документов выполняется на таможне после предварительного вынесения сборов. Ставка НДС, как при транзите, — 20%.
Ставка НДС, как при транзите, — 20%.
Перевозчик со своей стороны также может оформить гарантийное поручительство на таможенных постах РФ через агентов страховых компаний или таможенных брокеров, располагающих соответствующими лицензиями. Стоимость поручительства рассчитывается с учетом соотношения суммы таможенных сборов и протяженности маршрута до таможни назначения.
Важно! Для дорогостоящих грузов ТИР не оформляется. Чтобы не просчитаться, следует знать стоимость груза, код ТН ВЭД для расчета таможенных сборов. Расчет сборов осуществляется по формуле: размер пошлины по коду ТН ВЭД + 20% НДС от суммы стоимости товара и пошлины + сбор за таможенное оформление.
Однако страховые гарантии не являются защитой от любых неприятностей на пути следования груза. МСАТ гарантирует выплату до 60 000 евро. Но получит ее не перевозчик или собственник груза, а таможня. Кроме того, перевозчик не освобождается от финансовой ответственности при нарушении Конвенции МДП.
За каждую книжку МДП перевозчики перечисляют в АСМАП страховую премию 12,5 швейц. франков. Средства зачисляются на счет ОСАО«Ингосстрах». Но данная гарантия не предусматривает возмещения. Это страховка, за которую перевозчик при возникновении страхового случая, ничего не получает. Выгодоприобретатель — гарантийная цепь МДП (МСАТ, АСМАП, междугородние страховщики МСАТ).
франков. Средства зачисляются на счет ОСАО«Ингосстрах». Но данная гарантия не предусматривает возмещения. Это страховка, за которую перевозчик при возникновении страхового случая, ничего не получает. Выгодоприобретатель — гарантийная цепь МДП (МСАТ, АСМАП, междугородние страховщики МСАТ).
8. Предварительное Электронное Информирование ЭПИ
Это электронная декларация, содержащая сведения о грузоперевозке. Без ее подачи въехать на территорию Таможенного союза, просто показав книжку МДП, нельзя. После подачи ЭПИ сотрудники таможни присваивают перевозке индивидуальный MRN-номер (в виде штрих кода или цифр). Данный код водитель показывает на границе, и сотрудник таможни быстро находит ЭПИ в базе данных. После сверки с данными, содержащимися в сопроводительных документах, таможенник подтверждает номер MRN или направляет ЭПИ на правку. Действует специальный онлайн-сервис МСАТ — TIR-EPD. В нем можно оформить ЭПИ, если перевозка осуществляется по ТИРу. Если ТИР не применяется, а используется транзитная декларация, можно воспользоваться Порталом электронного представления сведений ФТС РФ или выбрать другие программы для оформления ЭПИ. Также данную задачу для вас решит таможенный брокер на пункте пропуска. Стоимость услуги зависит от количества кодов ТН ВЭД
Также данную задачу для вас решит таможенный брокер на пункте пропуска. Стоимость услуги зависит от количества кодов ТН ВЭД
9. Отслеживание книжки МДП – система SafeTIR
Электронная система контроля применения МДП книжек SafeTIR, работает через приложение CUTE-Wise. С ее помощью можно проверить действительность и статус каждой книжки МДП в режиме реального времени.
Задачами SafeTIR являются:
подтверждение о прекращении перевозки ТИР;
проверка книжки МДП, в том числе, таможенного штампа на корешке;
управление рисками в системе ТИР за счет электронного отслеживания нахождения книжки МДП;
выявление возможных нарушений и предупреждения их повторения;
упрощение процедур внутреннего расследования нарушений по конкретным книжкам МДП.
Таможенные органы передают информацию о прекращении TIR в МСАТ. Данные становятся доступными участникам системы МДП (таможенникам, страховщикам, транспортным операторам и др. ). SafeTIR позволяет таможне видеть статус книжки МДП до того, как она будет принята в оформление.
). SafeTIR позволяет таможне видеть статус книжки МДП до того, как она будет принята в оформление.
Если самостоятельно разобраться с вопросами оформления ТИР сложно, доверьте это дело профессионалам из компании «КВАТРО Логистик». Опытные брокеры возьмут на себя решение этих и других вопросов, связанных с таможенным оформлением, страхованием, сопровождением грузов.
Объяснение процесса принятия решений по Маркову | Построен в
Марковский процесс принятия решений (MDP) представляет собой математическую основу, используемую для моделирования задач принятия решений, когда результаты являются частично случайными и частично контролируемыми. Это структура, которая может решить большинство проблем обучения с подкреплением (RL).
Что такое марковский процесс принятия решений?
Марковский процесс принятия решений (MDP) — это математический инструмент, используемый для задач принятия решений, когда результаты частично случайны и частично контролируемы.
Я собираюсь описать проблему RL в широком смысле, и я буду использовать примеры из реальной жизни, оформленные как задачи RL, чтобы помочь вам лучше понять ее.
Вот что мы рассмотрим:
- Марковская терминология процесса принятия решений.
- Что такое марковское свойство?
- Объяснение марковского процесса.
- Марковский процесс вознаграждения (MRP).
- Марковский процесс принятия решений (MDP).
- Возврат (
G_t). - Полис (
π). - Функции значений.
- Функции оптимального значения марковского процесса принятия решений.
Марковская терминология процесса принятия решений
Прежде чем мы перейдем к MDP, нам необходимо рассмотреть несколько важных терминов, которые будут использоваться в этой статье:
- Агент: Агент обучения с подкреплением — это сущность которых мы обучаем принимать правильные решения.
 Например, робота, которого обучают передвигаться по дому, не разбиваясь.
Например, робота, которого обучают передвигаться по дому, не разбиваясь. - Окружающая среда: Окружающая среда — это среда, с которой взаимодействует агент. Например, дом, в котором движется робот. Агент не может манипулировать окружающей средой; он может контролировать только свои собственные действия. Другими словами, робот не может контролировать, где в доме стоит стол, но может ходить вокруг него.
- Состояние: Состояние определяет текущую ситуацию агента. Это может быть точное положение робота в доме, расположение его двух ног или его текущая поза. Все зависит от того, как вы решите проблему.
- Действие: Выбор, который делает агент на текущем временном шаге. Например, робот может двигать правой или левой ногой, поднимать руку, поднимать предмет или поворачивать вправо/влево и т. д. Мы заранее знаем набор действий (решений), которые может выполнить агент.
- Политика: Политика — это мыслительный процесс, стоящий за выбором действия.
 На практике это распределение вероятностей, назначенное набору действий. Высоко вознаграждающие действия будут иметь высокую вероятность, и наоборот. Если у действия низкая вероятность, это не значит, что оно вообще не будет выбрано. Просто вероятность того, что его выберут, меньше.
На практике это распределение вероятностей, назначенное набору действий. Высоко вознаграждающие действия будут иметь высокую вероятность, и наоборот. Если у действия низкая вероятность, это не значит, что оно вообще не будет выбрано. Просто вероятность того, что его выберут, меньше.
Мы начнем с основной идеи свойства Маркова, а затем продолжим более сложные уровни.
Что такое марковское свойство?
Свойство Маркова | Изображение: Rohan JagtapПредставьте, что робот, сидящий на стуле, встал и выставил правую ногу вперед. Итак, в данный момент он стоит правой ногой вперед. Это его текущее состояние.
Теперь, согласно свойству Маркова, текущее состояние робота зависит только от его непосредственно предыдущего состояния (или предыдущего временного шага), т. е. от состояния, в котором он находился, когда встал. И, видимо, не зависит от своего предшествующего состояния — сидящего на стуле. Точно так же его следующее состояние зависит только от его текущего состояния.
Формально, чтобы состояние S_t было марковским, вероятность того, что следующее состояние S_(t+1) будет s’, должна зависеть только от текущего состояния S_t = s_t , а не от остальных прошлых состояний S₁ = s₁ , S₂ = s₂ , … .
Подробнее о машинном обучении: как работает обратное распространение в нейронной сети?
Лекция о марковском процессе принятия решений с Дэвидом Сильвером. | Видео: Deep Mind
Объяснение марковского процесса
Вероятность перехода состояния. | Изображение: Rohan Jagtap Марковский процесс определяется как (S, P) , где S — это состояния, а P — вероятность перехода состояния. Он состоит из последовательности случайных состояний S₁, S₂ , … , где все состояния подчиняются марковскому свойству.
Вероятность перехода в состояние или P_ss ’ — вероятность перехода в состояние с’ из текущего состояния с.
Чтобы понять концепцию, рассмотрим приведенный выше пример цепи Маркова. Сидеть, стоять, разбиться и т. д. — это состояния, и даны соответствующие им вероятности перехода из одного состояния в другое.
Марковский процесс вознаграждения (MRP)
Вероятность перехода состояния и вознаграждение в MRP. | Изображение: Rohan Jagtap Марковский процесс вознаграждения (MRP) определяется (S, P, R, γ) , где S — это состояния, P — вероятность перехода состояния, R_s — вознаграждение, а γ — коэффициент дисконтирования, который будет рассмотрен в следующих разделах.
Награда за состояние R_s является ожидаемой наградой по всем возможным состояниям, в которые можно перейти из состояния s . Эта награда получена за нахождение в состоянии
Эта награда получена за нахождение в состоянии S_t . По соглашению считается, что вознаграждение получено после того, как агент покинет состояние, и, следовательно, считается равным 9.0024 Р_(т+1) .
Например:
Простой пример ППМ. | Изображение: Rohan Jagtap
Марковский процесс принятия решений (MDP)
Вероятность перехода состояния и вознаграждение в MDP | Изображение: Rohan Jagtap Марковский процесс принятия решений (MDP) определяется как (S, A, P, R, γ) , где A — набор действий. По сути это MRP с действиями. Введение в действия выявляет понятие контроля над марковским процессом. Раньше вероятность перехода состояния и вознаграждение за состояние были более или менее стохастическими (случайными). Однако теперь вознаграждение и следующее состояние также зависят от того, какое действие выберет агент. По сути, теперь агент может управлять своей судьбой (до некоторой степени)9. 0003
0003
Теперь мы обсудим, как использовать MDP для решения проблем с RL.
Возврат (G_t)
Возврат уравнения G_t. | Изображение: Rohan JagtapНаграды временные. Даже после выбора действия, дающего достойную награду, в долгосрочной перспективе мы можем упустить большую общую награду. Это долгосрочное общее вознаграждение и есть Возврат. Однако на практике мы рассматриваем Возвраты со скидкой.
Скидка (γ)
Переменная γ ∈ [0, 1] на рисунке является коэффициентом дисконтирования. Интуиция, стоящая за использованием скидки, заключается в том, что нет уверенности в будущих наградах. Хотя важно учитывать будущие вознаграждения для увеличения дохода, не менее важно ограничить вклад будущих вознаграждений в доход (поскольку вы не можете быть на 100 % уверены в будущем).0003
А еще потому, что пользоваться скидкой математически удобно.
Политика (π)
Уравнение политики. | Изображение: Rohan Jagtap Как упоминалось ранее, политика определяет мысль, лежащую в основе принятия решения (выбор действия). Он определяет поведение агента RL.
Он определяет поведение агента RL.
Формально политика представляет собой распределение вероятности по набору действий a при заданном текущем состоянии s . Дает вероятность выбора действия a в состоянии s .
Подробнее о машинном обучении: нейронные сети-трансформеры: пошаговое описание
Функции значений
Функция значений — это долгосрочное значение состояния или действия. Другими словами, это ожидаемый возврат по состоянию или действию. Это то, что мы действительно заинтересованы в оптимизации.
Функция значения состояния для MRP
Функция значения состояния для MRP. | Изображение: Рохан Джагтап Функция значения состояния v(s) является ожидаемым возвратом, начиная с состояния с .
Уравнение ожидания Беллмана для марковского процесса вознаграждения (MRP)
Уравнение Беллмана дает стандартное представление для функций ценности. Он разбивает функцию ценности на две составляющие:
Он разбивает функцию ценности на две составляющие:
- Немедленное вознаграждение
R_(t+1). - Дисконтированная стоимость будущего состояния
γ.v(S_(t+1)).
Давайте рассмотрим следующий сценарий (для простоты мы будем рассматривать только MRP):
Интуиция по уравнению Беллмана. | Изображение: Rohan Jagtap Агент может переходить из текущего состояния s в некоторое состояние s ’ . Теперь функция значения состояния в основном представляет собой ожидаемое значение доходности по всем с ’ . Теперь, используя то же определение, мы можем рекурсивно заменить возврат следующего состояния s ’ функцией значения s ’ . Это именно то, что делает уравнение Беллмана:
Это именно то, что делает уравнение Беллмана:
Теперь давайте решим это уравнение:
Решение для функции цены. | Изображение: Rohan Jagtap
Поскольку ожидание является дистрибутивным, мы можем решить для обоих R_(t+1) и v(s’) отдельно. Мы уже видели, что математическое ожидание R_(t+1) сверх S_t=s является государственной наградой R_s . И математическое ожидание v(s’) по всем s’ берется по определению математического ожидания.
Другими словами, награда за состояние — это постоянная ценность, которую мы так или иначе получим за то, что находимся в состоянии с . А другой член — это среднее значение состояния по всем с’ .
Функция значения состояния для марковского процесса принятия решений (MDP)
Функция значения состояния для MDP.
 | Изображение: Rohan Jagtap
| Изображение: Rohan JagtapЭто похоже на функцию стоимости для MRP, но есть небольшая разница, которую мы вскоре увидим.
Функция значения действия для марковского процесса принятия решений (MDP)
Функция значения действия для MDP. | Изображение: Рохан Джагтап
MDP вводят управление в MRP, рассматривая действия как параметр для перехода состояния. Значит, нужно оценивать действия наряду с состояниями. Для этого мы определяем функции ценности действия, которые дают нам ожидаемую отдачу от действий.
Функции значения состояния и функции значения действия тесно связаны. Мы увидим, как в следующем разделе.
Уравнение ожидания Беллмана (для MDP)
Уравнение ожидания Беллмана для MDP. | Изображение: Рохан Джагтап
Поскольку теперь мы знаем основы уравнения Беллмана, мы можем перейти к решению этого уравнения и посмотреть, чем оно отличается от уравнения Беллмана для MRP:
Интуиция по уравнению Беллмана.
 | Изображение: Rohan Jagtap
| Изображение: Rohan JagtapМы представляем состояния с помощью кружков и действия с помощью точек; обе приведенные выше диаграммы представляют собой представление одного и того же MDP на разных уровнях. Левая половина изображения — это представление, ориентированное на состояние, а правая — представление, ориентированное на действие.
Давайте сначала разберемся с цифрой:
- Обведите точку: Агент находится в состоянии s ; он выбирает действие и в соответствии с политикой. Скажем, мы учим агента играть в шахматы. Один временной шаг эквивалентен одному полному ходу (один ход белых и один ход черных соответственно). В этой части перехода агент выбирает действие (делает ход). Агент полностью контролирует эту часть, когда он выбирает действие часть полностью контролируется агентом, поскольку он выбирает действие.
- Точка в кружке: Среда воздействует на агента и переводит его в состояние, основанное на вероятности перехода.
 Продолжая пример с агентом, играющим в шахматы, отметим, что это часть перехода, в которой противник делает ход. После обоих ходов мы называем это полным переходом состояния. Агент не может контролировать эту часть, поскольку он не может контролировать то, как действует среда, а только свое собственное поведение.
Продолжая пример с агентом, играющим в шахматы, отметим, что это часть перехода, в которой противник делает ход. После обоих ходов мы называем это полным переходом состояния. Агент не может контролировать эту часть, поскольку он не может контролировать то, как действует среда, а только свое собственное поведение.
Теперь мы рассматриваем их как два отдельных мини-перехода:
Решение для функции значения состояния. | Изображение: Рохан ДжагтапПоскольку у нас есть переход от состояния к действию, мы берем ожидаемое значение действия для всех действий.
И это полностью удовлетворяет уравнению Беллмана, поскольку то же самое делается для функции ценности действия:
Решение для функции ценности действия. | Изображение: Rohan Jagtap
Мы можем подставить это уравнение в функцию значения состояния, чтобы получить значение с точки зрения рекурсивных функций значения состояния (и наоборот), подобных MRP:
Подстановка функции значения действия в функцию значения состояния и наоборот. | Изображение: Рохан Джагтап
| Изображение: Рохан Джагтап
Марковский процесс принятия решений Функции оптимального значения
Представьте, что если бы мы получили значение для всех состояний/действий MDP для всех возможных шаблонов действий, которые можно выбрать, то мы могли бы просто выбрать политику с наибольшим значением для состояния и действия. Уравнения выше представляют именно это. Если мы получим q∗(s, a) , то задача решена.
Мы можем просто присвоить вероятность 1 действию, имеющему максимальное значение для q∗ и 0 для остальных действий для всех заданных состояний.
Оптимальная политика. | Изображение: Rohan Jagtap
Уравнение оптимальности Беллмана
Уравнение оптимальности Беллмана для оптимальной функции значения состояния. | Изображение: Rohan Jagtap
Поскольку мы в любом случае собираемся выбрать действие, которое дает max q∗ , мы можем назначить это значение в качестве функции оптимального значения.
Уравнение оптимальности Беллмана для оптимальной функции ценности действия. | Изображение: Рохан Джагтап
В этом уравнении ничего существенно измениться не может, так как это та часть перехода, где действует среда; агент не может его контролировать. Однако, поскольку мы следуем оптимальной политике, функция ценности состояния будет оптимальной.
Мы можем решить большинство проблем RL с помощью MDP, как мы это сделали для робота и агента, играющего в шахматы. Просто определите набор состояний и действий.
В предыдущем разделе я сказал: «Представьте, что мы получили значение для всех состояний/действий MDP для всех возможных шаблонов действий, которые можно выбрать…». Однако это практически невыполнимо. Могут быть миллионы возможных паттернов переходов, и мы не можем оценить их все. Однако мы обсудили только формулировку любой проблемы RL в MDP и оценку агента в контексте MDP. Мы не исследовали поиск оптимальных значений/политики.
Существует множество итерационных решений для получения оптимального решения для MDP. Некоторые стратегии, о которых следует помнить, когда вы продвигаетесь вперед, включают:
Некоторые стратегии, о которых следует помнить, когда вы продвигаетесь вперед, включают:
- Итерация ценности.
- Итерация политики.
- САРСА.
- Q-обучение.
Марковский процесс принятия решений Определение, работа и примеры
Марковский процесс принятия решений (MDP) определяется как стохастический процесс принятия решений, который использует математическую основу для моделирования принятия решений динамической системой в сценариях, где результаты либо случайны, либо контролируются лицом, принимающим решения, которое принимает последовательные решения с течением времени. Эта статья объясняет MDP с помощью некоторых реальных примеров.
Содержание
- Что такое марковский процесс принятия решений?
- Как работает марковский процесс принятия решений?
- Примеры марковского процесса принятия решений
Что такое марковский процесс принятия решений?
Марковский процесс принятия решений (MDP) относится к стохастическому процессу принятия решений, который использует математическую основу для моделирования принятия решений динамической системой. Он используется в сценариях, где результаты либо случайны, либо контролируются лицом, принимающим решения, которое принимает последовательные решения с течением времени. MDP оценивают, какие действия следует предпринять лицу, принимающему решения, с учетом текущего состояния и среды системы.
Он используется в сценариях, где результаты либо случайны, либо контролируются лицом, принимающим решения, которое принимает последовательные решения с течением времени. MDP оценивают, какие действия следует предпринять лицу, принимающему решения, с учетом текущего состояния и среды системы.
MDP полагаются на такие переменные, как среда, действия агента и вознаграждения, чтобы определить следующее оптимальное действие системы. Они подразделяются на четыре типа — конечные, бесконечные, непрерывные или дискретные — в зависимости от различных факторов, таких как наборы действий, доступные состояния и частота принятия решений.
MDP существуют с начала 1950-х годов. Имя Марков относится к русскому математику Андрею Маркову, сыгравшему ключевую роль в формировании случайных процессов. Известно, что на первых порах MDP решали проблемы, связанные с управлением и контролем запасов, оптимизацией очередей и вопросами маршрутизации. Сегодня MDP находят применение при изучении задач оптимизации с помощью динамического программирования, робототехники, автоматического управления, экономики, производства и т. д.
д.
В искусственном интеллекте MDP моделируют последовательные сценарии принятия решений с вероятностной динамикой. Они используются для разработки интеллектуальных машин или агентов, которые должны работать дольше в среде, где действия могут привести к неопределенным результатам.
Модели MDP обычно популярны в двух областях ИИ: вероятностном планировании и обучении с подкреплением (RL).
- Вероятностное планирование — это дисциплина, использующая известные модели для достижения целей и задач агента. При этом он делает упор на то, чтобы направлять машины или агентов к принятию решений, позволяя им научиться вести себя для достижения своих целей.
- Обучение с подкреплением позволяет приложениям учиться на обратной связи, которую агенты получают из среды.
Давайте разберемся с этим на примере из реальной жизни :
Рассмотрим голодную антилопу в заповеднике дикой природы, ищущую пищу в окружающей среде. Натыкается на место с грибом справа и цветной капустой слева. Если антилопа съест гриб, в награду она получит воду. Однако, если он выберет цветную капусту, ближайшая клетка со львом откроется и освободит льва в святилище. Со временем антилопа учится выбирать сторону гриба, поскольку взамен этот выбор предлагает ценную награду.
Если антилопа съест гриб, в награду она получит воду. Однако, если он выберет цветную капусту, ближайшая клетка со львом откроется и освободит льва в святилище. Со временем антилопа учится выбирать сторону гриба, поскольку взамен этот выбор предлагает ценную награду.
В приведенном выше примере MDP существуют два важных элемента — агент и среда. Агентом здесь является антилопа, которая действует как лицо, принимающее решения. Окружающая среда показывает окружение (заповедник дикой природы), в котором обитает антилопа. Поскольку агент выполняет разные действия, возникают разные ситуации. Эти ситуации называются состояниями. Например, когда антилопа выполняет действие поедания гриба, она получает награду (воду) в соответствии с действием и переходит в другое состояние. Агент (антилопа) повторяет процесс в течение определенного периода и изучает оптимальное действие в каждом состоянии.
В контексте MDP мы можем формализовать, что антилопа знает оптимальное действие для выполнения (съесть гриб). Поэтому он не предпочитает есть цветную капусту, поскольку она приносит вознаграждение, которое может повредить его выживанию. Пример показывает, что MDP имеет важное значение для фиксации динамики проблем RL.
Поэтому он не предпочитает есть цветную капусту, поскольку она приносит вознаграждение, которое может повредить его выживанию. Пример показывает, что MDP имеет важное значение для фиксации динамики проблем RL.
Подробнее: Что такое HCI (взаимодействие человека и компьютера)? Значение, важность, примеры и цели
Как работает марковский процесс принятия решений?
Модель MDP работает с использованием ключевых элементов, таких как агент, состояния, действия, вознаграждения и оптимальные политики. Агент относится к системе, ответственной за принятие решений и выполнение действий. Он работает в среде, подробно описывающей различные состояния, в которых находится агент, когда он переходит из одного состояния в другое. MDP определяет механизм того, как одни состояния и действия агента приводят к другим состояниям. Более того, агент получает вознаграждение в зависимости от выполняемого им действия и достигнутого им состояния (текущего состояния). Политика для модели MDP раскрывает следующие действия агента в зависимости от его текущего состояния.
Политика для модели MDP раскрывает следующие действия агента в зависимости от его текущего состояния.
Платформа MDP имеет следующие ключевые компоненты:
- S : состояния ( s ∈ S )
- А : Действия (а ∈ А )
- P (S T+1 | S T .A T ) : вероятности перехода
- R (с) : Награда
Графическое представление модели MDP выглядит следующим образом:
Модель MDP использует свойство Маркова, которое гласит, что будущее можно определить только из настоящего состояния, которое инкапсулирует всю необходимую информацию из прошлого. Свойство Маркова можно оценить с помощью следующего уравнения:
P[S t+1 |S t ] = P[S t+1 9009 9 |S 1 ,S 2 ,S 3 ……S t ]
Согласно этому уравнению вероятность следующего состояния (P[S t+1 ]) при текущем состоянии (S t ) равна определяется вероятностью следующего состояния (P[S t+1 ]) с учетом всех предыдущих состояний 00 3 ……S т ) . Это означает, что MDP использует только настоящее/текущее состояние для оценки следующих действий без каких-либо зависимостей от предыдущих состояний или действий.
Это означает, что MDP использует только настоящее/текущее состояние для оценки следующих действий без каких-либо зависимостей от предыдущих состояний или действий.
Функция политики и значения
Известно, что политика ( Π) определяет оптимальное действие агента в текущем состоянии, чтобы он получил максимальное вознаграждение. Проще говоря, он связывает действия с состояниями.
Π: S -> A
Чтобы определить наилучшую политику, важно определить доходность, которая раскрывает вознаграждение агента в каждом состоянии. В результате метод горизонта не предпочтительнее, поскольку он фокусируется на краткосрочных или долгосрочных вознаграждениях. Вместо этого вводится переменная под названием «дисконтированный фактор (γ)». Правило гласит, что если γ имеет значения, близкие к нулю, то приоритет отдается немедленным вознаграждениям. Впоследствии, если γ показывает значения, близкие к единице, то акцент смещается на долгосрочное вознаграждение. Следовательно, метод дисконтированного бесконечного горизонта является ключом к выявлению наилучшей политики.
Следовательно, метод дисконтированного бесконечного горизонта является ключом к выявлению наилучшей политики.
Функция значения В(с) определяет возврат вознаграждения в каждом конкретном состоянии. Его формула характеризуется ожидаемой суммой дисконтированных будущих вознаграждений:
Функцию ценности можно разделить на две составляющие: вознаграждение текущего состояния и дисконтированное значение вознаграждения следующего состояния. Эта разбивка выводит уравнение Беллмана, как показано ниже:
Здесь стоит отметить, что действия и вознаграждения агента варьируются в зависимости от политики. Это означает, что функция ценности специфична для политики.
Функция оптимального значения может быть решена с помощью итерационных методов, таких как оценки методом Монте-Карло, динамическое программирование или обучение на основе временных разностей. Политика, которая выбирает максимальное оптимальное значение с учетом текущего состояния, называется оптимальной политикой. Математически это представлено следующим уравнением:
Математически это представлено следующим уравнением:
Таким образом, политика является следствием текущего состояния, при этом на каждом временном шаге новая политика оценивается на основе информации о текущем состоянии. Это возможно с помощью нескольких методов, таких как итерация политики, Q-обучение, итерация значений и линейное программирование для решения оптимальной функции политики.
Давайте теперь посмотрим на реальный пример, чтобы лучше понять работу MDP:
У нас есть проблема, в которой нам нужно решить, должны ли племена охотиться на оленей или нет в близлежащем лесу, чтобы обеспечить долгосрочную прибыль. Каждый олень приносит фиксированную прибыль. Однако, если племена охотятся сверх лимита, это может привести к более низкому урожаю в следующем году. Следовательно, нам нужно определить оптимальную долю оленей, которую можно поймать, получая при этом максимальную отдачу в течение более длительного периода.
Постановка задачи в этом случае может быть упрощена: охотиться на определенную часть оленей или нет. В контексте MDP проблема может быть выражена следующим образом:
В контексте MDP проблема может быть выражена следующим образом:
Штаты : Количество оленей в лесу в рассматриваемом году. Четыре состояния включают пустое, низкое, среднее и высокое, которые определяются следующим образом:
- Пусто : Нет доступных для охоты оленей
- Низкий : Доступное количество оленей ниже порогового значения t_1
- Средний : Доступное количество оленей между t_1 и t_2
- Высокий : Доступное количество оленей превышает пороговое значение t_2
Действия : Действия включают go_hunt и no_hunting, где go_hunt подразумевает отлов определенного количества оленей. Важно отметить, что для пустого состояния единственным возможным действием является no_hunting.
Награды : Охота в каждом штате приносит определенные награды. Награды за охоту в разных штатах, таких как низкий, средний и высокий, могут быть 5000 долларов, 50000 долларов и 100000 долларов соответственно. Более того, если действие приводит к пустому состоянию, вознаграждение составляет -200 тысяч долларов. Это связано с необходимостью электронного разведения новых оленей, что требует времени и денег.
Более того, если действие приводит к пустому состоянию, вознаграждение составляет -200 тысяч долларов. Это связано с необходимостью электронного разведения новых оленей, что требует времени и денег.
Переходы состояний : Охота в состоянии вызывает переход в состояние с меньшим количеством оленей. Впоследствии действие no_hunting вызывает переход в состояние с большим количеством оленей, за исключением «высокого» состояния.
Подробнее: Что такое дерево решений? Алгоритмы, шаблоны, примеры и лучшие практики
Примеры марковского процесса принятия решений
MDP внесли значительный вклад в несколько прикладных областей, таких как информатика, электротехника, производство, исследование операций, финансы и экономика, телекоммуникации и т. д. на.
Ниже перечислены несколько простых примеров, в которых MDP продолжает играть неизбежную роль:
1. Проблемы маршрутизации
Последовательное принятие решений на основе MDP используется для решения проблем маршрутизации, подобных тем, которые выявлены в задаче коммивояжера (TSP). ). TSP можно разбить на следующие компоненты:
). TSP можно разбить на следующие компоненты:
- Продавец = агент,
- Доступные маршруты = действия, которые агент может выполнять в текущем состоянии,
- Награды = стоимость прохождения определенных маршрутов и
- Цель = оптимальная политика, снижающая общую стоимость на все время поездки.
2. Управление обслуживанием и ремонтом динамических систем
Проблемы обслуживания и ремонта относятся к динамическим системам, таким как автомобили, автобусы или грузовики, которые со временем изнашиваются из-за действий в различных условиях. Решения в этом случае могут относиться к бездействию, выполнению задач по ремонту или замене критических компонентов транспортного средства. Постановка этой задачи в рамках MDP позволяет системе выбирать действия, которые помогают минимизировать затраты на техническое обслуживание автомобиля в течение всего срока его службы.
3. Проектирование интеллектуальных машин
Достижения в области искусственного интеллекта и машинного обучения привели к широкому использованию MDP в робототехнике, сложных автономных системах, автономных транспортных средствах, автоматизированных системах и т. д. MDP используются в моделях обучения с подкреплением, которые учат роботов и машины тому, как автономно учиться и выполнять определенные задачи.
д. MDP используются в моделях обучения с подкреплением, которые учат роботов и машины тому, как автономно учиться и выполнять определенные задачи.
Например, DeepMind Technologies, дочерняя компания Google, объединяет платформу MDP с нейронными сетями и обучает вычислительные системы играть в игры Atari лучше, чем люди. Компания также использовала MDP для обучения машин играть в настольные игры, такие как AlphaGo. DeepMind Technologies также использовала платформу MDP для обучения смоделированных роботов ходьбе и бегу.
4. Разработка игр-викторин
MDP широко используются для разработки игр-викторин с определенными уровнями. На каждом уровне задается вопрос, правильный ответ на который приносит денежное вознаграждение. По мере повышения уровня вопросы усложняются и влекут за собой более высокие награды.
В играх-викторинах, если участник хорошо играет и правильно отвечает на все вопросы, то он получает за это вознаграждение, а также возможность решить, играть ли викторину оттуда или выйти из игры. Если участник выходит, он, возможно, может сохранить все заработанные награды. Однако, если он решит играть и не сможет правильно ответить на вопрос на определенном уровне, он потеряет все накопленные награды. Цель таких игр — оценить действия по игре или выходу из нее при максимальном вознаграждении.
Если участник выходит, он, возможно, может сохранить все заработанные награды. Однако, если он решит играть и не сможет правильно ответить на вопрос на определенном уровне, он потеряет все накопленные награды. Цель таких игр — оценить действия по игре или выходу из нее при максимальном вознаграждении.
5. Управление временем ожидания на перекрестке
MDP помогают определить продолжительность работы светофора. Цель здесь состоит в том, чтобы максимизировать количество транспортных средств, которые могут проехать через транспортные развязки, сохраняя при этом контроль времени их ожидания. Это может быть перекресток с двусторонним движением, где движение может проходить в любом направлении, например, на запад или на юг, и так далее. Также предполагается наличие в системе данных о количестве автомобилей, подъезжающих к перекрестку с помощью датчиков. Светофоры в этом случае красные и зеленые. Здесь каждый шаг занимает несколько секунд (2 или 5). С помощью MDP вы можете решить, менять сигнал светофора или нет, в зависимости от транспортных средств на перекрестке и времени их ожидания.
6. Определение количества пациентов для госпитализации
Ежедневно определенное количество пациентов посещают больницу по разным причинам. Затем больница должна решить, сколько пациентов она может принять, учитывая такие факторы, как:
- количество уже госпитализированных пациентов,
- количество доступных кроватей и
- — общее количество пациентов, которые выздоравливают и выписываются ежедневно.
Определяя количество пациентов для госпитализации, больница также намеревается максимизировать количество пациентов, которые выздоравливают в течение определенного периода времени. Обе эти цели могут быть достигнуты путем разработки для них MDP.
Помимо приведенных выше примеров из реальной жизни, MDP жизненно важны для оптимизации телекоммуникационных протоколов, упрощения торговли акциями и тонкой настройки управления очередями в производственных секторах.
См. Подробнее : Линейная регрессия против логистической регрессии: понимание 13 ключевых различий
TakeAway
Процесс принятия решений Марков является стохастическим инструментом принятия решений, основанным на принципе свойства Markov.
