Читать онлайн «Развитие памяти. Методики НЛП», Мартин Лейвиц – Литрес
Введение
Нейролингвистическое программирование, или НЛП, по сей день не признано официальной наукой. Тем не менее, это одно из психологических учений за многие годы доказало свою эффективность. Суть НЛП – в том, что, желая совершенствоваться, вы «программируете» себя на успех. Эта методика работает в самых разных сферах человеческого бытия. С помощью НЛП вы можете избавиться от комплексов, психологических проблем и застарелых болячек.
Мы расскажем вам о том, как с помощью НЛП можно развить память. Необходимость хорошей памяти сложно переоценить. Согласитесь: если вы сможете выучить стихотворение или иностранный язык в разы быстрее, чем обычно, вам станет легче жить. Хорошая память нужна не только школьникам и студентам, но и людям в любом возрасте и всех профессий. Обретя способность стремительно осваивать что-то новое и оперативно запоминать массивы информации, вы получите жизнь в новом качестве. Это и профессиональный рост, и развитие творческого потенциала, и материальная независимость.
Это и профессиональный рост, и развитие творческого потенциала, и материальная независимость.
Методики НЛП для развития памяти основаны на раскрытии образного мышления. Занимаясь всего по часу-полтора в день, вы очень скоро заметите, что даже восприятие мира меняется к лучшему. Проще станет общаться, работать с новой информацией, выходить из зоны комфорта и достигать высот в профессиональном и личностном росте.
Нейролингвистическое программирование основано на игре с собой и реальностью. Именно поэтому методы НЛП, описанные в данной книге, несложны и не заставят вас скучать. Вы можете заниматься в одиночестве, в компании и с маленькими детьми.
Приглашаем вас в удивительный мир прекрасной памяти!
Глава первая. НЛП и память – в чем подвох?
Нейролингвистическое программирование появилось не так давно. В основе его – копирование успешных людей и избавление от внутренних «барьеров». Ведь недаром мудрецы утверждают: мы сами мешаем себе достигать светлого будущего. С раннего детства вокруг каждого из нас возникают всевозможные ограничения. Они могут быть полезными – «не суй вилку в розетку, будет больно», или вредными – «у тебя всё равно не получится». Общее в этих психологических табу – их цепкость. Они похожи на сорняки – забивают естественный для ребёнка интерес к новому, детскую непосредственность и веру в себя.
С раннего детства вокруг каждого из нас возникают всевозможные ограничения. Они могут быть полезными – «не суй вилку в розетку, будет больно», или вредными – «у тебя всё равно не получится». Общее в этих психологических табу – их цепкость. Они похожи на сорняки – забивают естественный для ребёнка интерес к новому, детскую непосредственность и веру в себя.
Избавившись от барьеров, можно достичь всего желаемого. И уж конечно, развить прекрасную память.
1.1. Нейролингвистическое программирование – что это?
Изначально НЛП разрабатывалось для психологической помощи людям. Причём в основу легли методы наиболее эффективных в середине двадцатого века психотерапевтов. С помощью методов нейролингвистического программирования мы учимся прежде всего наблюдать за окружающими и самими собой, изменять разрушительные внутренние программы.
Нейролингвистическое программирование – это одно из направлений практической психологии и психотерапии. Появилось оно в шестидесятых годах благодаря работе Ричарда Бендлера и Джона Гриндера в Калифорнийском университете. Изначально эффективность НЛП заключалась в копировании поведения успешных людей и анализе свойственных им особенностей речи, телодвижений, движений глаз. Что удивительно, при всей эффективности НЛП по сей день не признано академической наукой. Причём критики разделяются на два лагеря: первые утверждают, что методы НЛП аморальны, вторые – что они просто не работают, а потому являются шарлатанством. Впрочем, это нисколько не мешает практиковать различным школам нейролингвистическое программирование.
Изначально эффективность НЛП заключалась в копировании поведения успешных людей и анализе свойственных им особенностей речи, телодвижений, движений глаз. Что удивительно, при всей эффективности НЛП по сей день не признано академической наукой. Причём критики разделяются на два лагеря: первые утверждают, что методы НЛП аморальны, вторые – что они просто не работают, а потому являются шарлатанством. Впрочем, это нисколько не мешает практиковать различным школам нейролингвистическое программирование.
Как же действуют методы НЛП? По утверждению «первооткрывателей» практики, мы узнаём мир благодаря пяти чувствам, после чего информация трансформируется под влиянием внутренних убеждений, речевых особенностей и телодвижений. То есть объективная реальность остаётся нам недоступной. Живём же мы в так называемой субъективной, личностно-ориентированной реальности.
Субъективная реальность зависит от наших убеждений, восприятия, поведения. Каким образом? Мы оцениваем любое событие, касающееся нашей жизни. Например, барышня сталкивается с несчастной любовью. Она страдает, рыдает, думает, что раз «тот самый» мужчина не реагирует на неё, значит, и все остальные тоже её не оценят. Итог – отсутствие личной жизни… Или школьник не смог выучить стихотворение, получил «двойку» в дневник. В подсознании его закладывается: «У меня отвратительная память, я никогда и ничего не добьюсь». По этой схеме жизнь и продолжается…
Например, барышня сталкивается с несчастной любовью. Она страдает, рыдает, думает, что раз «тот самый» мужчина не реагирует на неё, значит, и все остальные тоже её не оценят. Итог – отсутствие личной жизни… Или школьник не смог выучить стихотворение, получил «двойку» в дневник. В подсознании его закладывается: «У меня отвратительная память, я никогда и ничего не добьюсь». По этой схеме жизнь и продолжается…
Техники НЛП работают с языковыми шаблонами и характерными телодвижениями. Эффективность нейролингвистического программирования вы сможете испытать на себе.
Методы НЛП* в практике психологического консультирования и коучинга
Вступление
* Нейролингвистическое программирование
Более 45 лет методы НЛП успешно используются в психотерапии, коучинге, менеджменте и образовании. В основе метода – стройная конструкция, система предположений и убеждений о широких возможностях каждого человека, наличии у него скрытых ресурсов и готовности к позитивным изменениям. Простые, но эффективные техники НЛП помогают решить целый спектр важнейших консультативных задач и повысить эффективность психологической помощи в целом.
Простые, но эффективные техники НЛП помогают решить целый спектр важнейших консультативных задач и повысить эффективность психологической помощи в целом.
На программу приглашаются психологи-консультанты и психотерапевты – представители различных терапевтических школ и направлений, специалисты в области коучинга, а также студенты старших курсов профильных учебных заведений.
В результате обучения участники смогут:
- познакомиться с основными принципами нейролингвистического программирования;
- освоить базовые техники НЛП и расширить свой профессиональный репертуар;
- понять алгоритм включения инструментов НЛП в процесс психотерапии и коучинга;
- получить опыт такого консультирования с последующим анализом его эфективности.
В программе
- Нейролингвистическое программирование и его важные составляющие.
- Почему НЛП – полезный инструмент для консультанта?
- Как работает нейролингвистическое программирование?
-
Целеполагание: помощь клиенту в постановке целей и позитивных, мотивирующих задач.
- Самоуправление: умственный тренинг для достижения высокоэффективных состояний.
- «Чтение» людей: техники активного слушания, наблюдения и правильного задавания вопросов.
- Взаимопонимание (раппорт): установление доверительных отношений с клиентом с помощью невербальной коммуникации.
- Каналы коммуникации: распознавание разных стилей мышления, использование полученной информации для построения раппорта и позитивного влияния на клиента.
- Ценности: идентификация ценностей клиента, использование полученной информации для усиления раппорта и мотивации клиента достигать поставленных целей.
- Влияние: настойчивость, творческий подход и чуткость в коммуникации как инструменты влияния специалиста.
- Домашнее задание для развития у участников навыков использования техник НЛП в консультировании.
Формы работы
мини-лекции, просмотр мультимедийных презентаций, фото- и видеоматериалов, самодиагностика, отработка практических навыков, выполнение домашнего задания, супервизия.
Объем программы 24 академических часа
Удостоверение о повышении квалификации.
Отзывов пока нет
Вы можете оставить отзыв о программе в своем личном кабинете, в разделе Посещенные события.
Резюме
10 Методы обработки естественного языка
Введение
Обработка естественного языка (NLP) — это способность компьютерного программного обеспечения интерпретировать устную и письменную человеческую речь, часто известную как естественный язык. Это часть ИИ (искусственного интеллекта).
НЛП зародилось в лингвистике и существует уже более 50 лет. Он имеет широкий спектр практического применения, включая медицинские исследования, поисковые системы и корпоративную разведку.
НЛП — это метод анализа текста, который позволяет роботам интерпретировать человеческую речь. Благодаря этому взаимодействию человека с компьютером стало возможным автоматическое суммирование текста, анализ настроений, извлечение тем, распознавание именованных сущностей, тегирование частей речи, извлечение связей, выделение корней и другие практические приложения.
Благодаря этому взаимодействию человека с компьютером стало возможным автоматическое суммирование текста, анализ настроений, извлечение тем, распознавание именованных сущностей, тегирование частей речи, извлечение связей, выделение корней и другие практические приложения.
Интеллектуальный анализ текста, машинный перевод и автоматические ответы на вопросы — все это примеры того, как используется НЛП.
НЛП считается сложным предметом в компьютерных науках. Человеческий язык редко бывает точным или простым для понимания. Чтобы понять человеческий язык, нужно понять не только слова, но и понятия и то, как они связаны с созданием смысла.
Несмотря на то, что язык является одной из самых простых вещей для человеческого разума, его неоднозначность делает НЛП сложной темой для понимания компьютерами.
- Стемминг и лемматизация
Стемминг или лемматизация — один из наиболее важных методов НЛП в конвейере предварительной обработки.
Например, при поиске товаров на Amazon предположим, что мы хотим отображать товары не только по точному термину, который мы ввели в поле поиска, но и по другим альтернативным вариантам введенного нами слова.
Если мы введем «рубашки» в поле поиска, весьма вероятно, что мы захотим просмотреть результаты поиска товаров, имеющие форму «рубашка». Подобные слова в английском языке кажутся разными в зависимости от времени и того, где они используются во фразе.
Такие слова, как идти, идти и идти, например, одно и то же, но используются по-разному в зависимости от контекста фразы. Подход НЛП с определением основы или лемматизацией направлен на создание корневых слов из этих вариантов слов.
Выделение стемминга — это рудиментарный эвристический процесс, который пытается достичь вышеупомянутой цели путем срезания концов слов, что может привести или не привести к осмысленному термину в конце.
С другой стороны, лемматизация — это более продвинутый подход, который направлен на правильное выполнение задач за счет использования словарного запаса и морфологического изучения слов. Он возвращает базовую или словарную форму слова, называемого леммой, удаляя флективные окончания.
Удаление стоп-слов — это операция предварительной обработки, которая следует за определением корней или лемматизацией. Многие слова в любом языке служат лишь наполнителями и не имеют никакого значения.
В основном это слова, которые используются для связи предложений (союзы — «потому что», «и», «так как») или для иллюстрации отношения слова к другим словам (предлоги — «под», «выше», « в», «в»).
Эти слова составляют большую часть человеческой речи, но не особенно эффективны для построения модели НЛП.
Например, при классификации текста удаление стоп-слов из текста помогает модели сосредоточиться на терминах, определяющих значение текста в наборе данных (жанровая классификация, фильтрация спама, автоматическое создание тегов).
Удаление стоп-слов может не потребоваться для таких задач, как сводка текста и машинный перевод. Стоп-слова могут быть удалены различными способами с использованием таких библиотек, как Genism, SpaCy и NLTK.
Чтобы узнать о методе НЛП удаления стоп-слов, мы воспользуемся пакетом SpaCy. Для большинства языков SpaCy включает в себя список стоп-слов.
- Тренировка изображений
Обучение воображению, часто известное как ментальная репетиция, представляет собой классический подход нейролингвистического программирования, основанный на визуализации.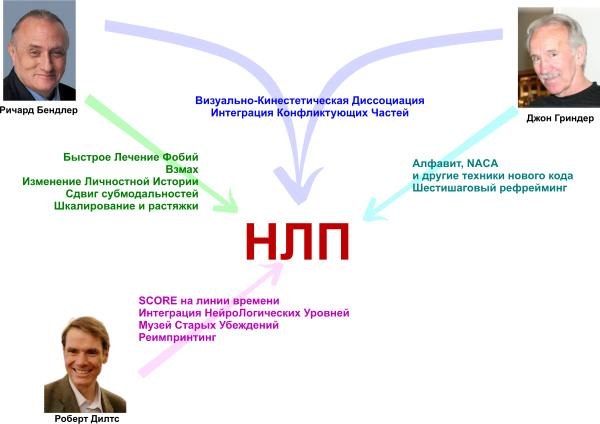
Цель состоит в том, чтобы увидеть, как вы эффективно завершаете деятельность, будь то презентация или отработка удара в гольф. Обратите внимание на свое поведение: уверенное, решительное и непринужденное.
Почувствуйте уверенность в себе и энергию, которая вас окружает. Предоставьте как можно больше информации. Этот тип метода НЛП имеет решающее значение для вселения полной уверенности в себе и своих талантах.
- Извлечение ключевых слов
Извлечение ключевых слов, часто называемое идентификацией ключевых слов или анализом ключевых слов, представляет собой метод обработки естественного языка (NLP) для анализа текста.
Основная цель этого подхода — автоматическое извлечение наиболее часто встречающихся слов и фраз из основного текста.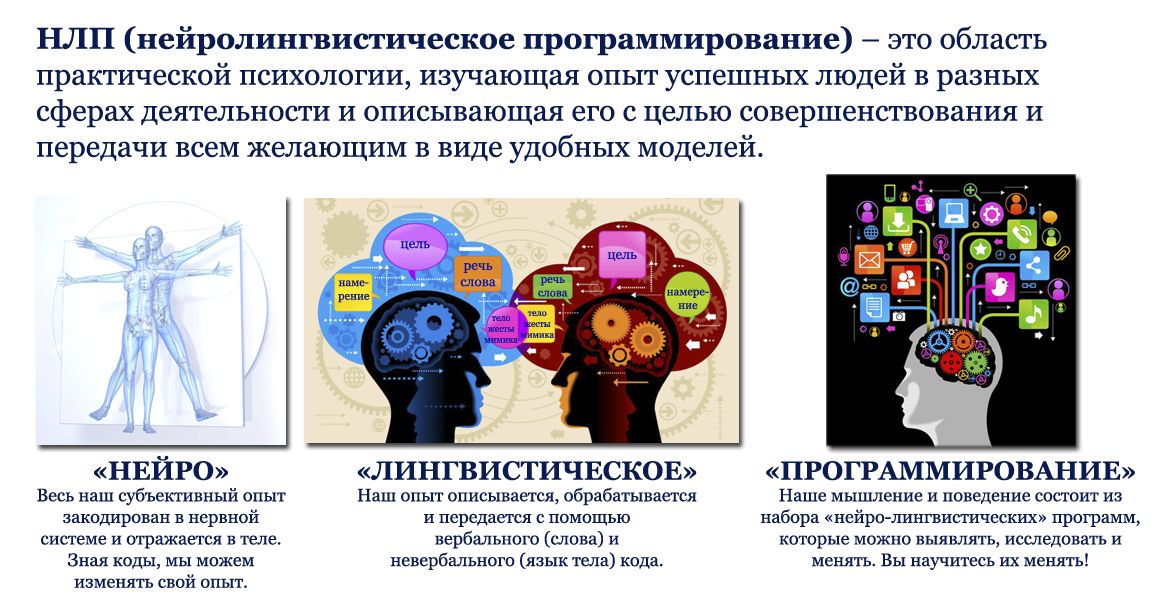 Он часто используется в качестве первого шага в обобщении основных концепций текста и передаче основных тем текста.
Он часто используется в качестве первого шага в обобщении основных концепций текста и передаче основных тем текста.
Сила машинного обучения и искусственного интеллекта скрыта в основе методов извлечения ключевых слов. Они используются для извлечения и упрощения заданного текста, чтобы компьютер мог его интерпретировать.
Алгоритм можно настроить и использовать в различных контекстах, начиная от учебных материалов и заканчивая разговорным текстом в сообщениях в социальных сетях.
В современных условиях извлечение ключевых слов имеет множество применений, включая мониторинг социальных сетей, обслуживание клиентов/отзывы, исследование продуктов и SEO. (Здесь)
- Тематическое моделирование
Методы извлечения ключевых слов могут использоваться для сокращения большого объема текста до нескольких основных ключевых слов и понятий. Вероятно, вы можете вывести из этого основную мысль текста.
Вероятно, вы можете вывести из этого основную мысль текста.
Тематическое моделирование — тематическое моделирование на основе неконтролируемого машинного обучения, которое не требует размеченных данных для обучения — еще один, более сложный подход к определению темы текста.
Коррелированная тематическая модель, латентное распределение Дирихле и латентный анализ настроений — вот некоторые из методов, которые можно использовать для моделирования текстовой темы. Скрытый метод Дирихле является наиболее часто используемым методом.
Этот метод исследует текст, разбивая его на слова и утверждения, а затем извлекая из этих слов и утверждений различные предметы. Все, что вам нужно сделать, это предоставить алгоритму основной текст, а он сделает все остальное.
- Распознавание именованных объектов
Распознавание именованных сущностей, или NER (потому что мы, технические специалисты, любим аббревиатуры), представляет собой подход к обработке естественного языка, который помечает и извлекает «именованные личности» из текста для последующего анализа.
NER связан с анализом настроений, как показано в примере ниже. NER, с другой стороны, просто помечает идентификаторы, будь то названия организаций, лица, имена собственные, местоположения или что-то еще, и отслеживает, сколько раз они появляются в наборе данных.
Количество раз, когда идентификатор (термин, относящийся к определенному объекту) появляется в отзывах клиентов, может указывать на необходимость решения конкретной проблемы.
Он может отображать предпочтения определенных типов элементов в обзорах и поисковых запросах, позволяя вам адаптировать каждый путь клиента к уникальному пользователю и тем самым улучшить его клиентский опыт. Ваш вклад и идеи контент-команд являются единственными ограничениями для приложения NER.
- Текстовое резюме
Это очень весело. Обобщение текста — это использование обработки естественного языка для разбиения жаргона, будь то научный, медицинский, технический или иной, на его самые основные понятия, чтобы сделать его более понятным.
Наши языки сложны, поэтому это может показаться пугающим. С другой стороны, программное обеспечение для сводки текста может быстро синтезировать сложный язык в компактный результат, используя фундаментальные алгоритмы связывания существительных и глаголов.
- Частота термина – обратная частота документа (TF-IDF)
TF-IDF вычисляет «веса», которые описывают, насколько важно слово для документа в наборе документов, в отличие от CountVectorizer (также известного как корпус).
Значение TF-IDF увеличивается прямо пропорционально количеству раз, которое слово встречается в документе, и компенсируется количеством документов в корпусе, содержащих этот термин.
Иными словами, чем выше показатель TF-IDF, тем более редкой, отличительной или ценной является фраза, и наоборот. У него есть приложения для поиска информации, такие как поисковые системы, которые стремятся предложить наиболее релевантные результаты для того, что вы ищете.
У него есть приложения для поиска информации, такие как поисковые системы, которые стремятся предложить наиболее релевантные результаты для того, что вы ищете.
- Сумка слов
Модель Bag of Words (BoW) представляет собой представление, преобразующее текст в векторы фиксированной длины. Это позволяет нам преобразовывать текст в числа, которые затем можно использовать в моделях машинного обучения.
Модель просто связана с частотой слов в тексте и не имеет отношения к их расположению. Он имеет приложения в НЛП, категоризации документов и поиске информации из документов. (Здесь)
- Аспект Майнинг
Интеллектуальный анализ аспектов — это метод определения многих особенностей текста. Он извлекает исчерпывающую информацию из текста при использовании в сочетании с анализом настроений. Тегирование по частям речи — один из самых простых способов анализа аспектов.
Он извлекает исчерпывающую информацию из текста при использовании в сочетании с анализом настроений. Тегирование по частям речи — один из самых простых способов анализа аспектов.
Когда анализ аспектов и тональность применяются к тексту примера, результат отражает цель текста:
Аспекты и настроения:
Обслуживание клиентов – минус
Колл-центр – минус
Агент – отрицательный
Ценообразование/Премиум – положительный
Заключение
Желание людей, чтобы компьютеры понимали их и общались с ними на разговорных языках, столь же древнее, как и сами компьютеры. Эта концепция больше не является просто концепцией благодаря быстрому технологическому прогрессу и алгоритмам машинного обучения. Это факт, который мы можем видеть и чувствовать в нашей повседневной жизни. Эта концепция лежит в основе обработки естественного языка.
Это факт, который мы можем видеть и чувствовать в нашей повседневной жизни. Эта концепция лежит в основе обработки естественного языка.
Обработка естественного языка — одна из самых актуальных тем и областей в настоящее время. Компании и академические учреждения стремятся разработать компьютерные системы, которые полностью понимают и используют человеческие языки. С момента своего основания в 1960-х, виртуальные агенты и переводчики быстро продвинулись вперед.
Приложения и методы обработки естественного языка
Что такое обработка естественного языка?
Обработка естественного языка подразумевает способность машин понимать и извлекать смысл из человеческих языков.
Машины могут понимать человеческий язык. Это может быть в форме речи/текста. Он использует ML (машинное обучение) для достижения цели искусственного интеллекта. Конечная цель состоит в том, чтобы соединить то, как люди общаются, и то, что могут понять компьютеры.
Если мы представим это математически, он содержит следующие термины:
- НЛП : НЛП (обработка естественного языка) отвечает за такие процессы, как решения и действия.
- NLU : NLU (понимание естественного языка) понимает смысл текста.
- NLG : NLG (генерация естественного языка) создает текст на человеческом языке из структурированных данных, которые система генерирует для ответа.
Подмножество техники искусственного интеллекта используется для сокращения разрыва в общении между компьютером и людьми.
Сколько существует типов?
Существует три разных уровня лингвистического анализа-
- Синтаксис — Какая часть данного текста является грамматически правильной.
- Семантика — Что означает данный текст?
- Прагматика — Какова цель текста?
Это подмножество техники искусственного интеллекта, которая используется для сокращения разрыва в общении между компьютером и человеком.НЛП имеет дело с различными аспектами языка, такими как:Нажмите, чтобы узнать об эволюции и будущем обработки естественного языка
- Фонология — Это систематическая организация звуков в языке.
- Морфология — Изучение образования слов и их взаимоотношений друг с другом.
- Распределительный — использует крупномасштабную статистическую тактику машинного обучения и глубокого обучения.
- Frame-Based — Предложения, которые синтаксически различны, но семантически одинаковы, представлены внутри структуры данных (фрейма) для стереотипной ситуации.
- Теоретический . Этот подход основан на идее, что предложения относятся к реальному миру (небо голубое), а части предложения могут быть объединены для представления всего смысла.
- Интерактивное обучение — предполагает прагматичный подход, и пользователь несет ответственность за обучение компьютера шаг за шагом изучению языка в интерактивной учебной среде.

Важность приложений
С помощью NLP можно выполнять определенные задачи, такие как автоматическая речь и автоматическое написание текста, за меньшее время. В связи с наличием значительных данных (текста) вокруг, почему бы нам не использовать компьютеры с неутомимой готовностью и способностью запускать несколько алгоритмов для выполнения задач в кратчайшие сроки. Эти задачи включают в себя другие приложения NLP, такие как автоматическое суммирование (для создания сводки заданного текста) и машинный перевод (перевод одного языка на другой).Какие два процесса лучше всего подходят для обработки естественного языка?
Если текст состоит из речи, выполняется преобразование речи в текст. Механизм обработки естественного языка включает два процесса:- Понимание естественного языка
- Генерация естественного языка
Понимание естественного языка
NLU или Natural Language Understanding пытается понять смысл данного текста. Характер и структура каждого слова внутри текста должны быть известны для NLU. Для понимания структуры NLU пытается разрешить следующую двусмысленность, присутствующую в естественном языке:
Характер и структура каждого слова внутри текста должны быть известны для NLU. Для понимания структуры NLU пытается разрешить следующую двусмысленность, присутствующую в естественном языке:- Лексическая неоднозначность — Слова имеют несколько значений
- Синтаксическая неоднозначность — Предложение содержит несколько деревьев синтаксического анализа.
- Семантическая неоднозначность — Предложение, имеющее несколько значений
- Анафорическая двусмысленность — Фраза или слово, которое упоминалось ранее, но имеет другое значение.
Далее смысл каждого слова понимается с помощью лексикона (словаря) и набора грамматических правил. Однако некоторые разные слова имеют сходное значение (синонимы) и слова, имеющие более одного значения (полисемия).
Генерация естественного языка
Это процесс автоматического создания текста из структурированных данных в удобочитаемом формате со значимыми фразами и предложениями. С проблемой генерации естественного языка трудно справиться. Это подмножество генерации естественного языка НЛП, разделенное на три предлагаемых этапа —
С проблемой генерации естественного языка трудно справиться. Это подмножество генерации естественного языка НЛП, разделенное на три предлагаемых этапа —
- Планирование текста — Выполняется упорядочение основного контента в структурированных данных.
- Планирование предложений — предложения объединяются со структурированными данными для представления потока информации.
- Реализация — Грамматически правильные предложения создаются, наконец, для представления текста.
Интеллектуальный анализ текста и обработка естественного языка
Он отвечает за понимание значения и структуры данного текста. Интеллектуальный анализ текста или текстовая аналитика — это процесс извлечения скрытой информации из текстовых данных посредством распознавания образов. Он используется для понимания значения (семантики) заданных текстовых данных, в то время как интеллектуальный анализ текста используется для понимания структуры (синтаксиса) заданных текстовых данных. Как пример — я нашел свой кошелек возле банка. Задача состоит в том, чтобы выяснить, в конце концов, что «банк» относится к финансовому институту или «речному берегу».
Как пример — я нашел свой кошелек возле банка. Задача состоит в том, чтобы выяснить, в конце концов, что «банк» относится к финансовому институту или «речному берегу».
Что такое большие данные?
По словам автора, доктора Кирка Борна, главного специалиста по данным, определение больших данных описывается как «большие данные — это все, измеряемое и отслеживаемое».Большие данные для обработки естественного языка
Сегодня около 80 % всех данных доступны в необработанном виде. Большие данные поступают из информации, хранящейся как в крупных организациях, так и на предприятиях. Примеры включают информацию о сотрудниках, записи о покупках компании, продажах, бизнес-транзакциях, предыдущие записи организаций, социальные сети и т. д. Хотя человек использует язык, который неоднозначен и неструктурирован для интерпретации компьютерами, тем не менее с помощью НЛП это большие неструктурированные данные могут быть использованы для развития шаблонов внутри данных, чтобы лучше узнать информацию, содержащуюся в данных. Он может решить серьезные проблемы делового мира с помощью больших данных. Будь то любой бизнес розничной торговли, здравоохранения, бизнеса, финансовых учреждений.
Он может решить серьезные проблемы делового мира с помощью больших данных. Будь то любой бизнес розничной торговли, здравоохранения, бизнеса, финансовых учреждений.Глубокое обучение для приложений НЛП
- Он использует подход, основанный на правилах, который представляет слова как закодированные векторы «горячего».
- Традиционный метод фокусируется на синтаксическом представлении вместо семантического представления.
- Пакет слов — модель классификации не может различать определенные контексты.
3 уровня возможностей глубокого обучения интеллекта
- Выразительность — это качество описывает, насколько хорошо машина может аппроксимировать универсальные функции.
- Обучаемость — Насколько хорошо и быстро система глубокого обучения может изучить свою проблему.
- Обобщаемость — Насколько хорошо машина может делать прогнозы на данных, которые она не обучала.

Применение глубокого обучения в НЛП
| Алгоритмы глубокого обучения | Использование НЛП |
|---|---|
Нейронная сеть — NN (канал) | — Тегирование части речи— Токенизация — Распознавание именованных сущностей — Извлечение намерений |
Рекуррентные нейронные сети — (RNN) | — Машинный перевод— Система ответов на вопросы — Подписи к изображениям |
Рекурсивные нейронные сети | — Разбор предложений— Анализ тональности — Обнаружение перефразирования — Классификация отношений — Обнаружение объекта |
Сверточная нейронная сеть — (CNN) | — Классификация предложений/текстов— Извлечение и классификация отношений — Обнаружение спама — Категоризация поисковых запросов — Извлечение семантических отношений |
Какова роль NLP в анализе журналов и добыче журналов?
Его методы широко используются в анализе бревен и добыче бревен. Для преобразования сообщений журнала в структурированную форму используются различные методы, такие как токенизация, выделение корней, лемматизация, синтаксический анализ и т. д. После того, как журналы доступны в хорошо документированной форме, выполняется анализ журналов и анализ журналов для извлечения полезной информации и извлечения знаний из информации. Пример в случае журнала ошибок, вызванного сбоем сервера.
Для преобразования сообщений журнала в структурированную форму используются различные методы, такие как токенизация, выделение корней, лемматизация, синтаксический анализ и т. д. После того, как журналы доступны в хорошо документированной форме, выполняется анализ журналов и анализ журналов для извлечения полезной информации и извлечения знаний из информации. Пример в случае журнала ошибок, вызванного сбоем сервера.
Что такое журнал?
Коллекция сообщений от различных сетевых устройств и оборудования во временной последовательности представляет собой журнал. Журналы могут быть направлены в файлы, находящиеся на жестких дисках, или могут быть отправлены по сети в виде потока сообщений сборщику журналов. Журналы обеспечивают процесс обслуживания и отслеживания производительности оборудования, настройки параметров, аварийных ситуаций и восстановления систем, а также оптимизации приложений и инфраструктуры.Подмножество искусственного интеллекта. Он обрабатывает большие объемы данных человеческого языка.Это сквозной процесс между системой и людьми. Читать различия между НЛП, НЛУ и НЛГ?
Что такое анализ журнала?
Анализ журналов — это процесс извлечения информации из журналов с учетом различного синтаксиса и семантики сообщений в файлах журналов и интерпретации контекста с приложением для проведения сравнительного анализа файлов журналов, поступающих из различных источников, для обнаружения аномалий и поиска корреляций.Что такое добыча бревен?
Интеллектуальный анализ журналов или обнаружение знаний журналов — это процесс извлечения шаблонов и корреляций в журналах для выявления знаний и прогнозирования обнаружения аномалий, если есть какие-либо внутренние сообщения журнала.Каковы лучшие методы обработки естественного языка?
Различные методы, используемые для анализа журнала, описаны ниже.Распознавание образов
Это один из таких методов, который включает сравнение сообщений журнала с сообщениями, хранящимися в книге шаблонов, для фильтрации сообщений.
Нормализация текста
Нормализация сообщений журнала выполняется для преобразования различных сообщений в один и тот же формат. Это делается, когда разные сообщения журнала имеют разную терминологию, но одна и та же интерпретация исходит из разных источников, таких как приложения или операционные системы.Автоматическая классификация текста и тегирование
Классификация и маркировка различных сообщений журнала включает в себя упорядочение сообщений и их маркировку различными ключевыми словами для последующего анализа.Искусственное невежество
Это своего рода метод, использующий алгоритмы машинного обучения для отбрасывания неинтересных сообщений журнала. Он также используется для обнаружения аномалий в обычной работе систем.Сосредоточьтесь на том, чтобы помочь компьютерам понять, как люди говорят и пишут. Читайте о естественном языке обработки в AI
Погружение в приложения для обработки естественного языка
Это сложная область, представляющая собой пересечение искусственного интеллекта, компьютерной лингвистики и компьютерных наук.
Начало работы с обработкой естественного языка
Пользователю необходимо импортировать файл, содержащий написанный текст. Затем пользователь должен выполнить следующие шаги.| Техника | Пример | Выход |
|---|---|---|
| Сегментация предложения | Марк встретился с президентом. Он сказал: «Привет! Что случилось, Алекс? | — Предложение 1 — Марк встретился с президентом. — Предложение 2 — Он сказал: «Привет! Что случилось, Алекс? |
| Токенизация | Мой телефон пытается «заряжаться» из состояния «разрядка». | — [Мой] [телефон] [пытается] [в] [‘] [заряжается] [‘][от] [‘][разряжается] [‘] [состояние][.] |
| Стемминг/лемматизация | Алкоголь, Пьяный, Пьяный | — Напиток |
| Маркировка части речи | Если ты его построишь, он придет. | — В — предлоги и подчинительные союзы. — PRP — личное местоимение — VBP — глагол существительное 3-е лицо единственного числа форма настоящего времени.  — PRP- Личное местоимение — MD — Модальные глаголы — VB — Основная форма глагола |
| Разбор | Марк и Джо зашли в бар. | — (S(NP(NP Mark) and (NP(Joe)) — (VP(пошел (PP в (NP бар)))) |
| Распознавание именованных объектов | Давай встретимся с Алисой в 6 утра в Индии. | — Давай встретимся с Алисой в 6 утра в Индии — Местоположение человека и времени |
| Разрешение базовой ссылки | Марк зашел в торговый центр. Он думал, что это торговый центр. | — Марк зашел в торговый центр. Он думал, что это торговый центр. |
- Сегментация предложения — Определяет границы предложений в данном тексте, т.е. где заканчивается одно предложение и начинается другое предложение. Предложения часто заканчиваются знаком препинания «.»
- Токенизация — идентифицирует разные слова, числа и другие знаки препинания.

- Stemming — удаляет окончание слов, например, «еда», сокращается до «есть».
- Тегирование части речи (POS) — Каждому слову в предложении назначается собственный тег части речи, например, обозначение слова как существительного или наречия.
- Синтаксический анализ — включает в себя разделение данного текста на разные категории. Чтобы ответить на вопрос, подобный этой части предложения, измените другую часть предложения.
- Распознавание именованных объектов — Идентифицирует такие объекты, как лица, местонахождение и время в документах.
- Резолюция Co-Reference — Речь идет об определении отношения данного слова в предложении с предыдущим и последующим предложением.
Наши решения предназначены для различных отраслей промышленности с акцентом на удовлетворение постоянно меняющихся маркетинговых потребностей. Нажмите здесь, чтобы узнать о наших решениях Google Cloud для работы с естественными языками
Каковы основные области применения обработки естественного языка?
Помимо использования в больших данных, интеллектуальном анализе журналов и анализе журналов, у него есть и другие важные области применения. Хотя термин «НЛП» не так популярен, как «большие данные», «машинное обучение», но мы используем его каждый день.
Хотя термин «НЛП» не так популярен, как «большие данные», «машинное обучение», но мы используем его каждый день.Автоматический суммировщик текста
Учитывая входной текст, задача состоит в том, чтобы написать сводку текста, отбрасывая нерелевантные точки.Анализ текста на основе тональности
Это делается для данного текста, чтобы предсказать тему текста, например, передает ли текст суждение, мнение или обзоры и т. Д.Текстовая классификация
Это выполняется для классификации различных журналов, новостей в соответствии с их доменом. Также возможна многодокументная классификация. Известным примером классификации текста является обнаружение спама в электронных письмах. В зависимости от стиля письма в журнале его атрибут можно использовать для определения имени автора.Извлечение информации
Извлечение информации — это то, что предлагает почтовой программе автоматически добавлять события в календарь.Как XenonStack может вам помочь?
Раскройте реальную ценность ваших данных с помощью наших услуг и решений для обработки и анализа данных. Воспользуйтесь преимуществами решений для бизнес-аналитики и консалтинга в области обработки данных, чтобы ускорить рост вашего предприятия.
Воспользуйтесь преимуществами решений для бизнес-аналитики и консалтинга в области обработки данных, чтобы ускорить рост вашего предприятия.Решения для анализа текста
Text Analytics или Text Mining относится к автоматическому извлечению важной информации из текста. Извлечение включает в себя структурирование входного текста, обнаружение закономерностей в структурированных данных и интерпретацию результатов. Процесс интеллектуального анализа текста включает в себя машинное обучение, статистику, интеллектуальный анализ данных и компьютерную лингвистику. Анализ настроений с использованием машинного обучения, НЛП и глубокого обучения В XenonStack мы обрабатываем и анализируем текстовый контент и предоставляем ценную информацию, преобразуя необработанные данные в структурированную полезную информацию. Решения XenonStack для анализа текстов предлагают маркировку частей речи (PoS), кластеризацию, классификацию, извлечение информации, анализ тональности и многое другое.Анализ настроений с использованием машинного обучения, НЛП и глубокого обучения
Анализ настроений помогает понять реакцию людей на ситуации.
