Методы обработки данных
представлены двумя основными методами:
количественный (математико-статистический) анализ;
качественный анализ (дифференциация материала по группам, вариантам, описание случаев, как наиболее полно выражающих типы и варианты, так и являющихся исключением).
Задачи психологического исследования обычно предполагают те или иные сопоставления. Например:
сопоставление групп испытуемых по какому-либо признаку для выявления различий между ними но этому признаку;
сравнение выделенного показателя (например, объема произвольного запоминания) до и после экспериментального воздействия (программы формирования мимических процессов) для оценки эффективности такого воздействия;
сопоставление эмпирического распределения значений признака с теоретическим законом распределения;
сравнение двух признаков, измеренных на одной выборке испытуемых для установления степени согласованности их изменений, сопряженность, корреляцию между ними;
сопоставление индивидуальных значений, полученных при разных комбинациях каких-либо существенных условий с тем, чтобы выявить характер взаимодействия этих условий в их влиянии на индивидуальные значения признака.


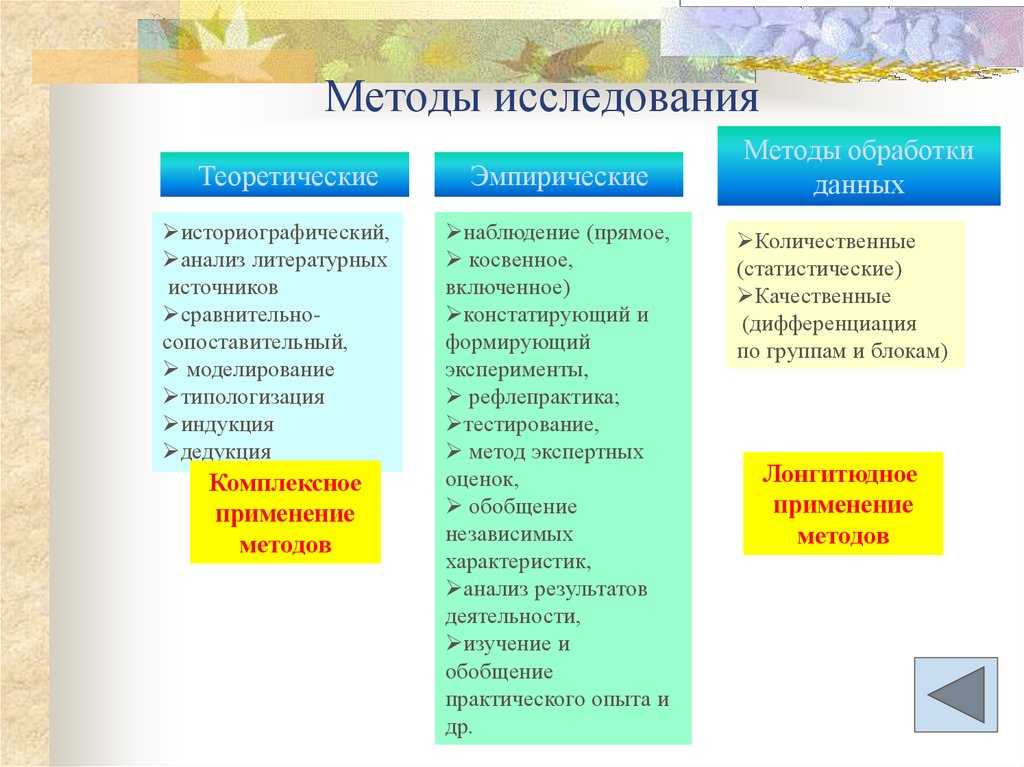
Интерпретационные методы близки по содержанию к методам качественного, содержательного анализа и представляют собой логическое и необходимое продолжение работы но анализу полученных данных. Специфика исследований в области педагогической психологии (предмет, цели, проблематика таких исследований) позволяет сделать вывод о том, что эти методы работы с полученными данными являются первостепенными по отношению к методам математической обработки.
К интерпретационным Ананьев относит генетический и структурный методы.
1. Генетический метод дает возможность интерпретировать весь отработанный материал исследования в характеристиках развития, выделяя фазы, стадии, критические моменты становления психических новообразований. Он позволяет выявить «вертикальные» генетические связи между уровнями развития.

Требования, предъявляемые к организации психологических исследований
1. Планирование:
подбор и апробация методов и методик, принимая во внимание все многообразие внешних и внутренних факторов, влияющих на протекание подлежащей исследованию психической деятельности;
составление логической и хронологической схем исследования;
выбор контингента испытуемых, определение количественных параметров выборки и необходимого числа измерений;
план обработки и интерпретации данных.
2. Место проведения исследования:
должно обеспечивать изоляцию от внешних помех (или учет влияния таких помех), комфорт и рабочую обстановку.
3. Техническое оснащение:
должно
соответствовать решаемым задачам, ходу
исследования и уровню анализа получаемых
результатов.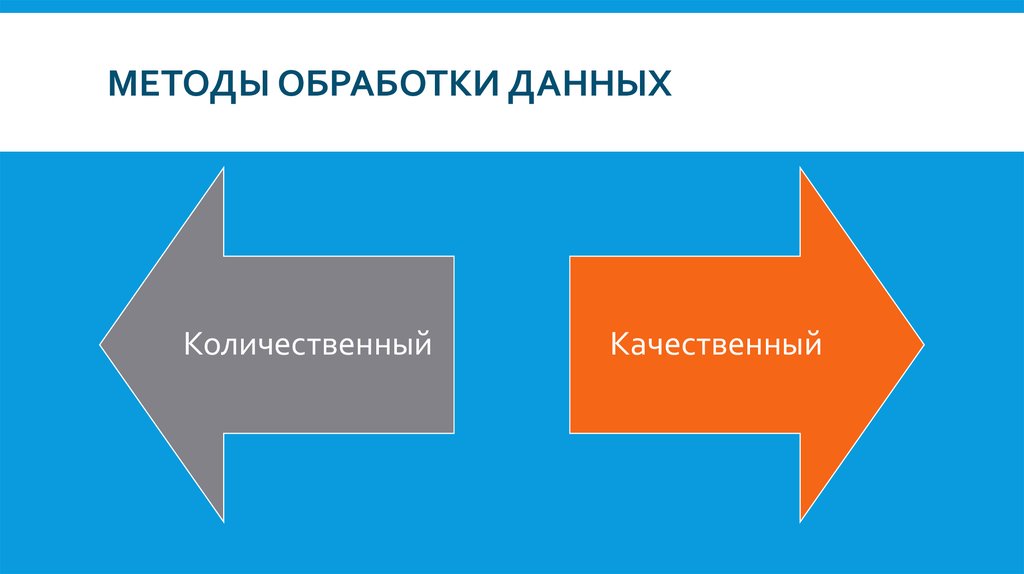
4. Подбор испытуемых:
должен обеспечить их качественную однородность.
5. Исследователь неизбежно влияет на ход исследования на всех его этапах (от планирования до формулировки выводов).
Это необходимо учитывать и стремиться к максимальной объективности. Действенными средствами ее повышения могут быть: проведение системных, многократных, повторных проб; параллель исследования общего объекта разными исследователями и сравнение полученных результатов; профессиональная рефлексия, а также использование технических средств для регистрации изученных явлений.
Инструкция составляется еще на стадии планирования работы. Она должна быть четкой, краткой, понятной, активизирующей те психологические явления, которые выбраны для изучения.
7. Протокол исследования
должен быть одновременно полным и
целенаправленным (избирательным). Это
позволяет рассматривать изучаемое
явление не изолированно, а в контексте
целостного проявления индивидуальности,
во взаимосвязях, которые определяют
специфику изучаемых компонентов.
Это
позволяет рассматривать изучаемое
явление не изолированно, а в контексте
целостного проявления индивидуальности,
во взаимосвязях, которые определяют
специфику изучаемых компонентов.
8. Обработка результатов — количественный и качественный анализ и синтез полученных данных, где качественный анализ занимает ведущее место в формулировке выводов и составлении рекомендаций.
Этапы психологического исследования
Методы обработки данных в психодиагностике
Введение
Одно из значений термина «диагноз» в переводе с греческого языка — «распознание». Диагностика понимается как распознание чего-либо (например, болезни в медицине, отклонения от нормы в дефектологии, неисправности в работе какого-либо технического средства и т. д.).
Психологическая диагностика
предназначена для того, чтобы
обеспечить сбор информации об особенностях
человеческой психики.
Психодиагностика как психологическая дисциплина служит соединительным звеном между общепсихологическими исследованиями и практикой.
Теоретические основы психодиагностики
задаются соответствующими областями
психологической науки (общая, дифференциальная,
возрастная, медицинская психология
и др.). К методическим средствам
психодиагностики относятся конкретные
приемы изучения индивидуально-психологических
особенностей, способы обработки
и интерпретации получаемых результатов.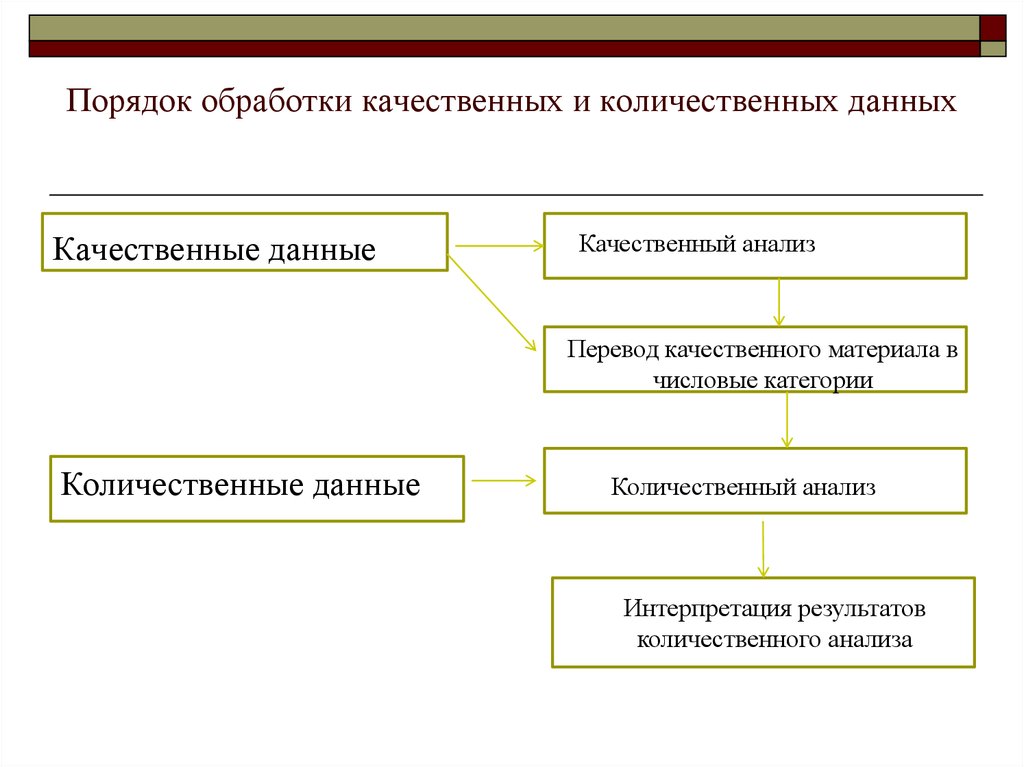 Направления теоретической и
методической работы в области психодиагностики
определяются главным образом запросами
психологической практики. В соответствии
с этими запросами формируются
специфические комплексы
Направления теоретической и
методической работы в области психодиагностики
определяются главным образом запросами
психологической практики. В соответствии
с этими запросами формируются
специфические комплексы
В компетенцию психодиагностики
входят конструирование и апробация
методик, разработка требований, которым
они должны удовлетворять, выработка
правил проведения обследования, способов
обработки и интерпретации
Психодиагностика предполагает, что полученные с ее помощью результаты будут либо соотноситься с определенной системой отсчета, либо сравниваться между собой. В связи с этим можно говорить о двух типах диагноза.
Во-первых, диагноз на основе
констатации наличия или 
Во-вторых, диагноз, позволяющий находить место испытуемого или группы испытуемых на «оси континиума» по выраженности тех или иных качеств. Для этого требуются сравнение получаемых при диагностировании данных внутри обследуемой выборки, ранжирование испытуемых по степени того, как те или иные показатели представлены, введение показателей высокого, среднего и низкого уровней развития изучаемых особенностей путем соотношения полученных данных с критерием (например, социально-психологическим нормативом). Психодиагностические методики призваны достаточно быстро и надежно обеспечивать сбор данных об испытуемом для формулирования психологического диагноза.
В зависимости от целей
диагностической работы судьба поставленного
психологом диагноза может быть различной.
Этот диагноз может быть передан
другому специалисту (например, учителю,
врачу и др.), который сам принимает
решение о его использовании в своей работе.
Поставленный диагноз может сопровождаться
рекомендациями по развитию или коррекции
изучаемых качеств и предназначаться
не только специалистам (педагогам, дефектологам,
практическим психологам и др.
Таким образом, диагностика
предполагает обязательное сопоставление
получаемых данных, на основе которого
и может быть сформулировано заключение
об отдельном испытуемом или группе
лиц, по поводу выраженности тех или
иных индивидуально-психологических
или индивидуально-
Цель работы: определить активные методы психодиагностики.
Задачи работы:
— дать характеристику Методам обработки данных в психодиагностике
— провести обработку данных одного из активных методов психодиагностики.
1. Методы обработки
данных в психодиагностике
Методы обработки
данных в психодиагностике
ПОНЯТИЕ «МЕТОД»
Прежде чем ответить на
вопрос контрольной работы «Методы
обработки результатов
В «Толковом словаре» С.И.
Ожегова под методом
1) способ теоретического
исследования или
2) способ действовать, поступать каким-либо образом;
3) прием.
Метод также может рассматриваться в разных смыслах. Метод в широком смысле – всякое понятие, регулирующие постановку и осуществление задач, всякое представление, инструмент эмпирического, теоретического изучения объекта. В узком смысле метод – регулятор сбора данных, построение выбора.
Понятие «метод» шире понятия
«методика», поэтому разберемся,
какие основные функции являются
характерными для методики, чтобы
правильно определить виды методик
и отобрать те, которые предназначены
для обработки результатов 
Методика используется в зависимости от применяемого метода, выступает конкретным способом фиксации эмпирических данных. Методики используют в том отношении, которое определяет метод. По сути, иногда методику включают в метод как один из уровней изучения.
Эксперимент выступает методом,
методики измерения подбираются
так, как это определяет сам метод
эксперимента. Метод отражает структуру
исследования, это более обширный
инструмент. Методика – операция обобщения,
способ сбора информации. Метод как
обобщенно-познавательное отношение
исследователя к изучаемому объекту
может реализоваться
Один и тот же метод
может быть применен для изучения
разных базисных процессов. Методики представляют
собой процедуры, техники сбора денных
и используются в разных исследованиях.
Основное назначение методик – проверка полученных в результате эксперимента данных, сравнение достижений изучаемого объекта за определенный период времени.[8].
Психологические исследования, направленные на изучение личности, используют большое количество методов, выбор которых зависит от целей, поставленных исследователем.
Наша задача – дать характеристику методов обработки результатов психологического исследования, используя различную литературу по психологии.
Психологическое исследование направлено на изучение личности и психических качеств, происходящих в ней. А для этого требуется инструментарий, при помощи которого необходимо измерять, как изменились свойства и качества личности. Эти измерения подвергаются специальной обработке, по результатам которых судят об изменениях в объекте исследования.
В психологии широко применяются
различные способы и приемы обработки
результатов психологических  е. факторов и выводов,
вытекающих из интерпретации переработанной
первичной информации. Для этой цели
применяются, в частности, разнообразные методы математической статистики,
без которых зачастую невозможно получить
достоверную информацию об изучаемых
явлениях, а так же методы качественного
анализа.
е. факторов и выводов,
вытекающих из интерпретации переработанной
первичной информации. Для этой цели
применяются, в частности, разнообразные методы математической статистики,
без которых зачастую невозможно получить
достоверную информацию об изучаемых
явлениях, а так же методы качественного
анализа.
Для обработки полученных
данных чаще всего используются статистические
методы (нахождение средних значений,
отклонений от среднего значения, связи
между переменными, уровня значимости,
достоверности, выявления факторов
и т. п.). Такие методы позволяют
вскрыть имеющиеся
Важную роль играют методы интерпретации,
которые позволяют придать содержательно-психологический
смысл полученным данным.[9]. Другими словами
это методы позволяют перевести полученные
в ходе диагностики и обработки данные
(числа, закономерностях) с языка математики
на язык психологии, т. е. осуществить переход
от чисел и закономерностей к психологическим
понятиям и суждениям.
Комментируя полученные обследования,
диагност не всегда четко учитывает
специфику использованного
Обычно интерпретация понимается как совокупность значений (смыслов), придаваемых определенным способом различным данным (в более общем смысле: теориям, символам, формулам, выражениям и т.п.). Другими славами, интерпретировать что-то – значит приписать (присвоить) этому содержанию смысл.
Б.Г.Ананьев выделял два метода
интерпретации данных, полученных в исследовании:
генетический, предлагающий выделение
фаз, стадий, критических моментов развития,
и структурный, определяющий структурные
связи между характеристиками личности.
Анализ взаимосвязи между
большим количеством переменных
осуществляется путем использования
многомерных методов
Многомерное шкалирование обеспечивает наглядную оценку сходства и различия между некоторыми объектами, описываемые большим количеством разнообразных переменных. Эти различия представляются в виде расстояния между оцениваемыми объектами в многомерном пространстве.
1.1Статистические методы проверки гипотезы.
Статистическая гипотеза (statistical hypothesys) — это определённое предположение о распределении вероятностей, лежащем в основе наблюдаемой выборки данных.
Проверка статистической
гипотезы (testing statistical hypotheses) — это процесс
принятия решения о том, противоречит
ли рассматриваемая статистическая гипотеза
наблюдаемой выборке данных.
Статистический тест или статистический критерий — строгое математическое правило, по которому принимается или отвергается статистическая гипотеза.
Статистическая гипотеза представляет собой некоторое предположение о законе распределения случайной величины или о параметрах этого закона, формулируемое на основе выборки [3, 5, 11]. Примерами статистических гипотез являются предположения: генеральная совокупность распределена по экспоненциальному закону; математические ожидания двух экспоненциально распределенных выборок равны друг другу. В первой из них высказано предположение о виде закона распределения, а во второй – о параметрах двух распределений. Гипотезы, в основе которых нет никаких допущений о конкретном виде закона распределения, называют непараметрическими, в противном случае – параметрическими.
Гипотезу, утверждающую, что
различие между сравниваемыми  Наряду с основной гипотезой рассматривают
и альтернативную (конкурирующую, противоречащую)
ей гипотезу Н1. И если нулевая гипотеза
будет отвергнута, то будет иметь место
альтернативная гипотеза.
Наряду с основной гипотезой рассматривают
и альтернативную (конкурирующую, противоречащую)
ей гипотезу Н1. И если нулевая гипотеза
будет отвергнута, то будет иметь место
альтернативная гипотеза.
Проверка гипотезы основывается на вычислении некоторой случайной величины – критерия, точное или приближенное распределение которого известно. Обозначим эту величину через z, ее значение является функцией от элементов выборки
z=z(x1, x2, …, xn).
Процедура проверки гипотезы
предписывает каждому значению критерия
одно из двух решений – принять
или отвергнуть гипотезу. Тем самым
все выборочное пространство и соответственно
множество значений критерия делятся
на два непересекающихся подмножества
S0 и S1. Если значение критерия z попадает
в область S0, то гипотеза принимается,
а если в область S1, – гипотеза
отклоняется. Множество S0 называется областью
принятия гипотезы или областью допустимых
значений, а множество S1 – областью
отклонения гипотезы или критической
областью. Выбор одной области
однозначно определяет и другую область.
Выбор одной области
однозначно определяет и другую область.
В зависимости от сущности проверяемой гипотезы и используемых мер расхождения оценки характеристики от ее теоретического значения применяют различные критерии. К числу наиболее часто применяемых критериев для проверки гипотез о законах распределения относят критерии хи-квадрат Пирсона, Колмогорова, Мизеса, Вилкоксона, о значениях параметров – критерии Фишера, Стьюдента.
1.2 T-критерий Стьюдента
Критерий
Стьюдента был разработан английским
химиком У.Госсетом, когда он работал на
пивоваренном заводе Гиннеса и по условиям
контракта не имел права открытой публикации
своих исследований. Поэтому публикации
своих статей по t-критерию У.Госсет сделал
в 1908г. в журнале «Биометрика» под
псевдонимом «Student», что в переводе
означает «Студент». В отечественной
же литературе принято писать «Стьюдент».
Коварная простота вычисления t-критерия
Стьюдента, а также его наличие в большинстве
статистических пакетов и программ привели
к широкому использованию этого критерия
даже в тех условиях, когда применять его
нельзя.
Особенности использования t-критерия Стьюдента. Наиболее часто t -критерий используется в двух случаях. В первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых, несвязанных выборок (так называемый двухвыборочный t-критерий). В этом случае есть контрольная группа и опытная группа, состоящая из разных пациентов, количество которых в группах может быть различно. Во втором же случае используется так называемый парный t-критерий, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних. Поэтому эти выборки называют зависимыми, связанными. Например, измеряется содержание лейкоцитов у здоровых животных, а затем у тех же самых животных после облучения определенной дозой излучения. В обоих случаях должно выполняться требование нормальности распределения исследуемого признака в каждой из сравниваемых групп.
Проведение анализа – Методы исследования в психологии – 2-е канадское издание
Глава 12: Описательная статистика
- Опишите этапы подготовки и анализа типичного набора необработанных данных.

Даже если вы понимаете, что такое статистика, анализ данных может оказаться сложным процессом. Вполне вероятно, что для каждого из нескольких участников имеются данные по нескольким различным переменным: демографические данные, такие как пол и возраст, одна или несколько независимых переменных, одна или несколько зависимых переменных и, возможно, проверка манипулирования. Более того, «сырые» (непроанализированные) данные могут принимать несколько различных форм — заполненные бумажно-карандашные вопросники, компьютерные файлы, заполненные цифрами или текстом, видео или письменные заметки, — и их, возможно, придется систематизировать, кодировать или комбинировать. каким-то образом. Могут быть даже отсутствующие, неправильные или просто «подозрительные» ответы, с которыми необходимо разобраться. В этом разделе мы рассмотрим некоторые практические советы, чтобы сделать этот процесс максимально организованным и эффективным.
Независимо от того, находятся ли ваши необработанные данные на бумаге или в компьютерном файле (или в том и другом), есть несколько вещей, которые вы должны сделать, прежде чем приступить к их анализу.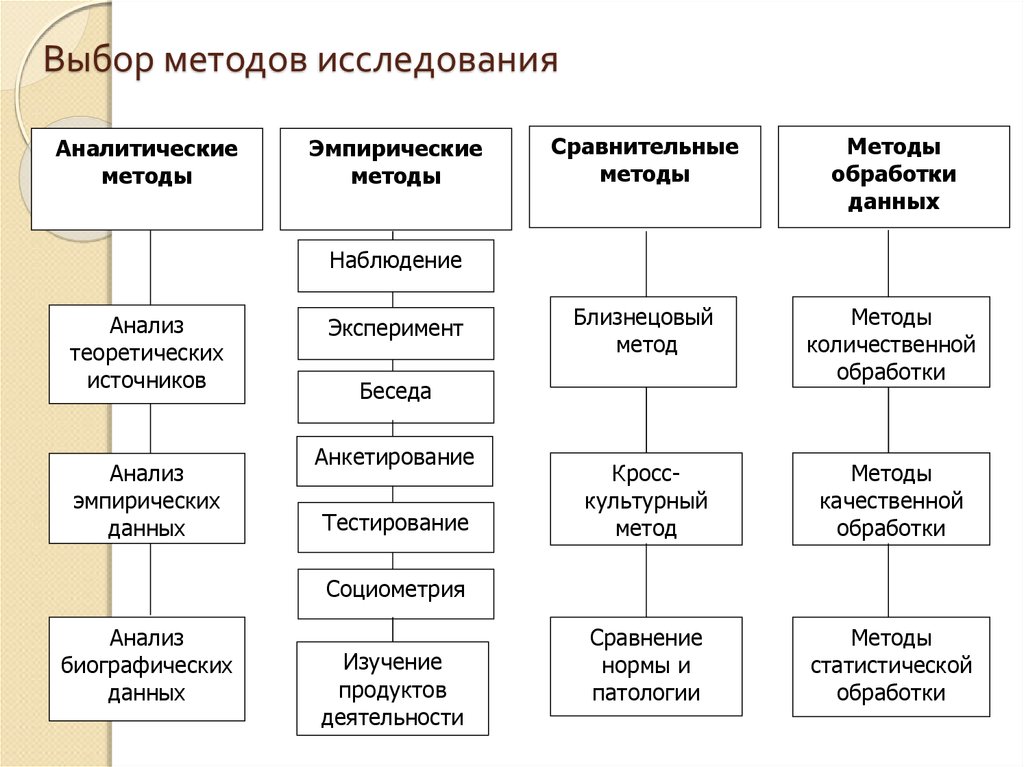 Во-первых, убедитесь, что они не содержат никакой информации, которая может идентифицировать отдельных участников, и убедитесь, что у вас есть безопасное место, где вы можете хранить данные, и отдельное безопасное место, где вы можете хранить любые формы согласия. Если данные не являются очень конфиденциальными, обычно достаточно запертой комнаты или защищенного паролем компьютера. Также рекомендуется делать фотокопии или резервные копии файлов ваших данных и хранить их в еще одном безопасном месте — по крайней мере, до завершения проекта. Профессиональные исследователи обычно хранят копии своих необработанных данных и форм согласия в течение нескольких лет на случай, если после завершения проекта возникнут вопросы о процедуре, данных или согласии участников.
Во-первых, убедитесь, что они не содержат никакой информации, которая может идентифицировать отдельных участников, и убедитесь, что у вас есть безопасное место, где вы можете хранить данные, и отдельное безопасное место, где вы можете хранить любые формы согласия. Если данные не являются очень конфиденциальными, обычно достаточно запертой комнаты или защищенного паролем компьютера. Также рекомендуется делать фотокопии или резервные копии файлов ваших данных и хранить их в еще одном безопасном месте — по крайней мере, до завершения проекта. Профессиональные исследователи обычно хранят копии своих необработанных данных и форм согласия в течение нескольких лет на случай, если после завершения проекта возникнут вопросы о процедуре, данных или согласии участников.
Затем вам следует проверить свой , чтобы убедиться, что он заполнен и правильно записан (будь то участники, вы сами или компьютерная программа, которая делала запись). На этом этапе вы можете обнаружить неразборчивые или отсутствующие ответы или явное недопонимание (например, ответ «12» по шкале от 1 до 10). Вам придется решить, достаточно ли серьезны такие проблемы, чтобы сделать данные участника непригодными для использования. Если информация об основной независимой или зависимой переменной отсутствует или если несколько ответов отсутствуют или вызывают подозрение, вам, возможно, придется исключить данные этого участника из анализа. Если вы решите исключить какие-либо данные, не выбрасывайте и не удаляйте их, потому что вы или другой исследователь можете захотеть просмотреть их позже. Вместо этого отложите их в сторону и запишите, почему вы решили их исключить, потому что вам нужно будет сообщить эту информацию.
Вам придется решить, достаточно ли серьезны такие проблемы, чтобы сделать данные участника непригодными для использования. Если информация об основной независимой или зависимой переменной отсутствует или если несколько ответов отсутствуют или вызывают подозрение, вам, возможно, придется исключить данные этого участника из анализа. Если вы решите исключить какие-либо данные, не выбрасывайте и не удаляйте их, потому что вы или другой исследователь можете захотеть просмотреть их позже. Вместо этого отложите их в сторону и запишите, почему вы решили их исключить, потому что вам нужно будет сообщить эту информацию.
Теперь вы готовы ввести свои данные в программу для работы с электронными таблицами или, если они уже есть в компьютерном файле, отформатировать их для анализа. Вы можете использовать обычную программу для работы с электронными таблицами, такую как Microsoft Excel, или программу статистического анализа, такую как SPSS, чтобы создать свой . (Файлы данных, созданные в одной программе, обычно можно преобразовать для работы с другими программами. ) Наиболее распространенный формат: каждая строка представляет участника, а каждый столбец представляет переменную (с именем переменной вверху каждого столбца). . Пример файла данных показан в таблице 12.6. Первый столбец содержит идентификационные номера участников. Затем следуют столбцы, содержащие демографическую информацию (пол и возраст), независимые переменные (настроение, четыре элемента самооценки и общее количество четырех элементов самооценки) и, наконец, зависимые переменные (намерения и установки). Категориальные переменные обычно можно вводить в виде меток категорий (например, «М» и «Ж» для мужчин и женщин) или в виде чисел (например, «0» для отрицательного настроения и «1» для положительного настроения). Хотя метки категорий часто более четкие, для некоторых анализов могут потребоваться числа. SPSS позволяет вам вводить числа, а также прикреплять к каждому числу метку категории.
) Наиболее распространенный формат: каждая строка представляет участника, а каждый столбец представляет переменную (с именем переменной вверху каждого столбца). . Пример файла данных показан в таблице 12.6. Первый столбец содержит идентификационные номера участников. Затем следуют столбцы, содержащие демографическую информацию (пол и возраст), независимые переменные (настроение, четыре элемента самооценки и общее количество четырех элементов самооценки) и, наконец, зависимые переменные (намерения и установки). Категориальные переменные обычно можно вводить в виде меток категорий (например, «М» и «Ж» для мужчин и женщин) или в виде чисел (например, «0» для отрицательного настроения и «1» для положительного настроения). Хотя метки категорий часто более четкие, для некоторых анализов могут потребоваться числа. SPSS позволяет вам вводить числа, а также прикреплять к каждому числу метку категории.
| ID | СЕКС | ВОЗРАСТ | НАСТРОЕНИЕ | СЭ1 | СЭ2 | SE3 | СЭ4 | ВСЕГО | INT | АТТ |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | М | 20 | 1 | 2 | 3 | 2 | 3 | 10 | 6 | 5 |
| 2 | Ф | 22 | 1 | 1 | 0 | 2 | 1 | 4 | 4 | 4 |
| 3 | Ф | 19 | 0 | 2 | 2 | 2 | 2 | 8 | 2 | 3 |
| 4 | Ф | 24 | 0 | 3 | 3 | 2 | 3 | 11 | 5 | 6 |
Если у вас есть показатели с несколькими ответами, такие как показатель самооценки в Таблице 12. 6, вы можете объединить элементы вручную, а затем ввести общий балл в свою электронную таблицу. Однако намного лучше вводить каждый ответ как отдельную переменную в электронную таблицу — как в случае измерения самооценки в Таблице 12.6 — и использовать программное обеспечение для их объединения (например, с помощью функции «СРЕДНЯЯ» в Excel или функции « Вычислить» в SPSS). Этот подход не только более точен, но и позволяет обнаруживать и исправлять ошибки, оценивать внутреннюю согласованность и анализировать отдельные ответы, если вы решите сделать это позже.
6, вы можете объединить элементы вручную, а затем ввести общий балл в свою электронную таблицу. Однако намного лучше вводить каждый ответ как отдельную переменную в электронную таблицу — как в случае измерения самооценки в Таблице 12.6 — и использовать программное обеспечение для их объединения (например, с помощью функции «СРЕДНЯЯ» в Excel или функции « Вычислить» в SPSS). Этот подход не только более точен, но и позволяет обнаруживать и исправлять ошибки, оценивать внутреннюю согласованность и анализировать отдельные ответы, если вы решите сделать это позже.
Прежде чем перейти к основным вопросам исследования, часто необходимо провести несколько предварительных анализов. Для мер с множественными ответами следует оценить внутреннюю согласованность меры. Статистические программы, такие как SPSS, позволят вам вычислить α Кронбаха или κ Коэна. Если это выходит за рамки вашего уровня комфорта, вы все равно можете вычислить и оценить корреляцию с разделением пополам.
Далее следует проанализировать каждую важную переменную отдельно. (Конечно, этот шаг необязателен для управляемых независимых переменных, потому что вы, как исследователь, определили, каким будет распределение.) Постройте гистограммы для каждой из них, отметьте их форму и вычислите общие показатели центральной тенденции и изменчивости. Убедитесь, что вы понимаете, что такое статистика означает с точки зрения интересующих вас переменных. Например, распределение самооценки счастья по шкале от 1 до 10 может быть унимодальным и иметь отрицательную асимметрию со средним значением 8,25 и стандартным отклонением 1.14. Но что означает этот , так это то, что большинство участников оценили себя довольно высоко по шкале счастья, а небольшое число оценило себя заметно ниже.
(Конечно, этот шаг необязателен для управляемых независимых переменных, потому что вы, как исследователь, определили, каким будет распределение.) Постройте гистограммы для каждой из них, отметьте их форму и вычислите общие показатели центральной тенденции и изменчивости. Убедитесь, что вы понимаете, что такое статистика означает с точки зрения интересующих вас переменных. Например, распределение самооценки счастья по шкале от 1 до 10 может быть унимодальным и иметь отрицательную асимметрию со средним значением 8,25 и стандартным отклонением 1.14. Но что означает этот , так это то, что большинство участников оценили себя довольно высоко по шкале счастья, а небольшое число оценило себя заметно ниже.
Настало время выявить выбросы, изучить их более внимательно и решить, что с ними делать. Вы можете обнаружить, что то, что на первый взгляд кажется выбросом, является результатом неправильного ввода ответа в файл данных, и в этом случае вам нужно только исправить файл данных и двигаться дальше.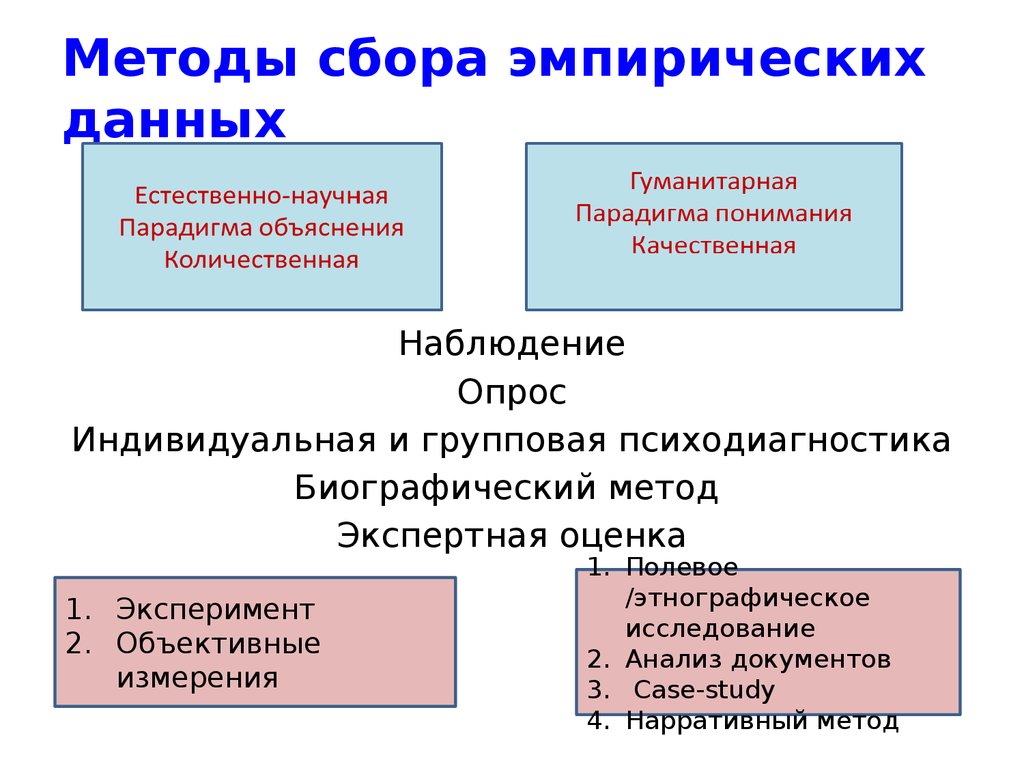 В качестве альтернативы вы можете подозревать, что выброс представляет собой какую-то другую ошибку, непонимание или отсутствие усилий со стороны участника. Например, в распределении времени реакции, в котором большинству участников потребовалось всего несколько секунд, чтобы ответить, участник, которому потребовалось 3 минуты, чтобы ответить, будет выбросом. Кажется вероятным, что этот участник не понял задание (или, по крайней мере, не обратил на него особого внимания). Кроме того, включение его или ее времени реакции окажет большое влияние на среднее значение и стандартное отклонение для выборки. В подобных ситуациях может быть оправданным исключение из анализа второстепенного ответа или участника. Однако если вы сделаете это, вам следует вести записи о том, какие ответы или участников вы исключили и почему, и последовательно применять те же критерии к каждому ответу и каждому участнику. Когда вы представляете свои результаты, вы должны указать, сколько ответов или участников вы исключили, а также конкретные критерии, которые вы использовали.
В качестве альтернативы вы можете подозревать, что выброс представляет собой какую-то другую ошибку, непонимание или отсутствие усилий со стороны участника. Например, в распределении времени реакции, в котором большинству участников потребовалось всего несколько секунд, чтобы ответить, участник, которому потребовалось 3 минуты, чтобы ответить, будет выбросом. Кажется вероятным, что этот участник не понял задание (или, по крайней мере, не обратил на него особого внимания). Кроме того, включение его или ее времени реакции окажет большое влияние на среднее значение и стандартное отклонение для выборки. В подобных ситуациях может быть оправданным исключение из анализа второстепенного ответа или участника. Однако если вы сделаете это, вам следует вести записи о том, какие ответы или участников вы исключили и почему, и последовательно применять те же критерии к каждому ответу и каждому участнику. Когда вы представляете свои результаты, вы должны указать, сколько ответов или участников вы исключили, а также конкретные критерии, которые вы использовали. И опять же, не выбрасывайте и не удаляйте данные, которые вы решили исключить. Просто отложите их, потому что вы или другой исследователь можете захотеть просмотреть их позже.
И опять же, не выбрасывайте и не удаляйте данные, которые вы решили исключить. Просто отложите их, потому что вы или другой исследователь можете захотеть просмотреть их позже.
Имейте в виду, что выбросы не обязательно представляют собой ошибку, недопонимание или недостаток усилий. Они могут представлять действительно экстремальные ответы или участников. Например, в одной большой выборке студентов университета подавляющее большинство участников сообщили, что у них было менее 15 сексуальных партнеров, но было также несколько крайних значений 60 или 70 (Brown & Sinclair, 1999) 90 161 [1] 90 162. Хотя эти оценки могут отражать ошибки, недоразумения или даже преднамеренные преувеличения, вполне вероятно, что они представляют собой честные и даже точные оценки. Одной из стратегий здесь было бы использование медианы и других статистических данных, на которые не сильно влияют выбросы. Другой вариант — проанализировать данные, включая и исключая любые выбросы. Если результаты в основном совпадают, что часто бывает, то имеет смысл оставить выбросы. Если результаты различаются в зависимости от того, включены или исключены выбросы, то можно представить оба анализа и обсудить различия между ними.
Если результаты различаются в зависимости от того, включены или исключены выбросы, то можно представить оба анализа и обсудить различия между ними.
Наконец-то вы готовы ответить на основные вопросы исследования. Если вас интересует разница между средними значениями группы или условия, вы можете вычислить соответствующие средние значения группы или условия и стандартные отклонения, построить гистограмму для отображения результатов и вычислить d Коэна. Если вас интересует корреляция между количественными переменными, вы можете построить линейный график или диаграмму рассеяния (не забудьте проверить на нелинейность и ограничение диапазона) и вычислить коэффициент Пирсона р .
На этом этапе вы также должны изучить свои данные на наличие других интересных результатов, которые могут стать основой для будущих исследований (и материалом для раздела обсуждения вашей статьи). Дэрил Бем (2003) предполагает, что вы
[e]изучите [ваши данные] со всех сторон.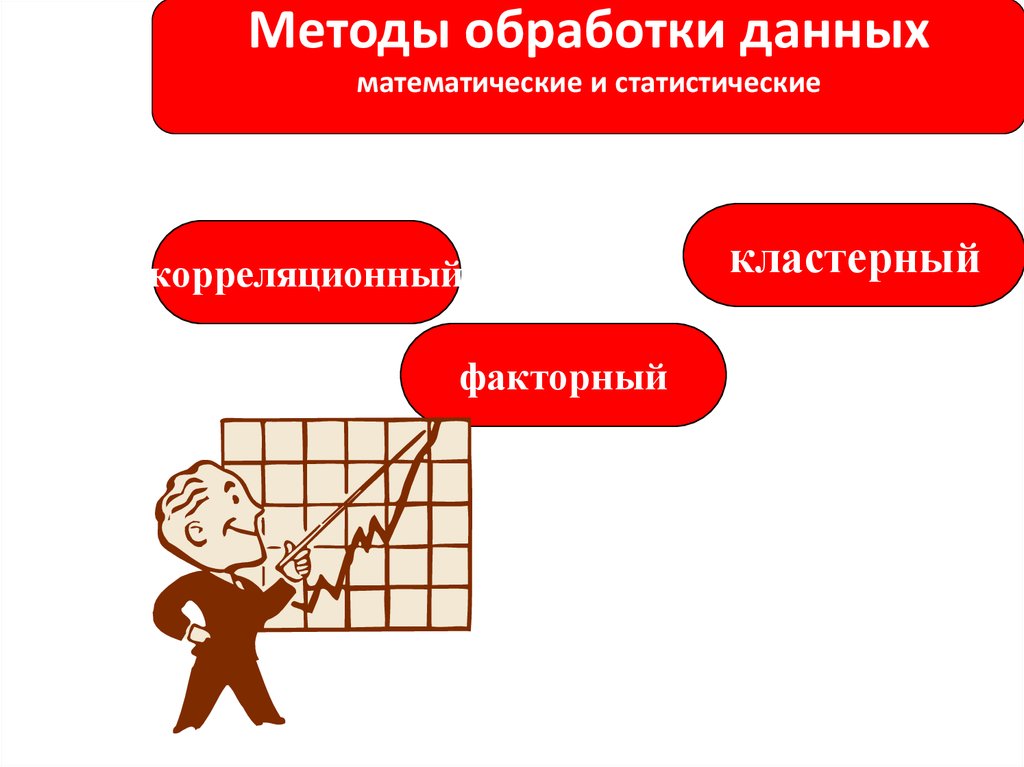 Проанализируйте пол отдельно. Составьте новые составные индексы. Если данные предполагают новую гипотезу, попытайтесь найти дополнительные доказательства в других местах данных. Если вы видите смутные следы интересных закономерностей, попробуйте реорганизовать данные, чтобы сделать их более рельефными. Если есть участники, которые вам не нравятся, или испытания, наблюдатели или интервьюеры, которые дали вам аномальные результаты, исключите их (временно). Отправляйтесь на рыбалку за чем-нибудь — чем угодно — интересным. (стр. 186–187) [2]
Проанализируйте пол отдельно. Составьте новые составные индексы. Если данные предполагают новую гипотезу, попытайтесь найти дополнительные доказательства в других местах данных. Если вы видите смутные следы интересных закономерностей, попробуйте реорганизовать данные, чтобы сделать их более рельефными. Если есть участники, которые вам не нравятся, или испытания, наблюдатели или интервьюеры, которые дали вам аномальные результаты, исключите их (временно). Отправляйтесь на рыбалку за чем-нибудь — чем угодно — интересным. (стр. 186–187) [2]
Однако важно соблюдать осторожность, поскольку сложные наборы данных могут включать «паттерны», возникшие совершенно случайно. Таким образом, результаты, обнаруженные во время «рыбалки», должны быть воспроизведены по крайней мере в одном новом исследовании, прежде чем они будут представлены как самостоятельные новые явления.
В следующей главе мы рассмотрим статистику логического вывода — набор методов, позволяющих решить, применимы ли результаты вашей выборки к генеральной совокупности. Хотя статистика выводов важна по причинам, которые мы вскоре объясним, начинающие исследователи иногда забывают, что их описательная статистика действительно говорит о том, «что произошло» в их исследовании. Например, представьте, что группа лечения из 50 участников имеет средний балл 34,32 ( SD = 10,45), контрольная группа из 50 участников имеет средний балл 21,45 ( SD = 9,22), а d Коэна – чрезвычайно сильный показатель 1,31. Несмотря на то, что проведение и представление выводной статистики (например, теста t ), безусловно, будет обязательной частью любого официального отчета об этом исследовании, из одной только описательной статистики должно быть ясно, что лечение сработало. Или представьте, что на диаграмме рассеяния видно нечеткое «облако» точек и r 9 Пирсона.0152 является тривиальным −02. Опять же, несмотря на то, что проведение и отчетность по логической статистике были бы обязательной частью любого официального отчета об этом исследовании, из одной только описательной статистики должно быть ясно, что переменные по существу не связаны между собой.
Хотя статистика выводов важна по причинам, которые мы вскоре объясним, начинающие исследователи иногда забывают, что их описательная статистика действительно говорит о том, «что произошло» в их исследовании. Например, представьте, что группа лечения из 50 участников имеет средний балл 34,32 ( SD = 10,45), контрольная группа из 50 участников имеет средний балл 21,45 ( SD = 9,22), а d Коэна – чрезвычайно сильный показатель 1,31. Несмотря на то, что проведение и представление выводной статистики (например, теста t ), безусловно, будет обязательной частью любого официального отчета об этом исследовании, из одной только описательной статистики должно быть ясно, что лечение сработало. Или представьте, что на диаграмме рассеяния видно нечеткое «облако» точек и r 9 Пирсона.0152 является тривиальным −02. Опять же, несмотря на то, что проведение и отчетность по логической статистике были бы обязательной частью любого официального отчета об этом исследовании, из одной только описательной статистики должно быть ясно, что переменные по существу не связаны между собой.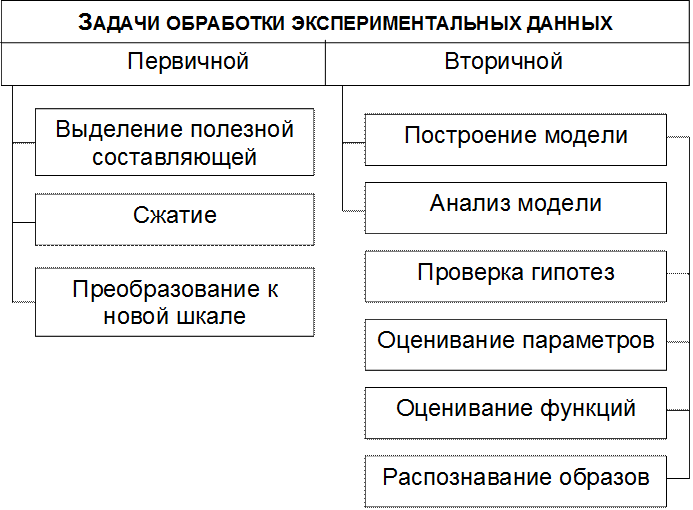 Дело в том, что вы всегда должны быть уверены, что сначала полностью понимаете свои результаты на описательном уровне, а затем переходите к выводной статистике.
Дело в том, что вы всегда должны быть уверены, что сначала полностью понимаете свои результаты на описательном уровне, а затем переходите к выводной статистике.
- Необработанные данные должны быть подготовлены для анализа путем проверки их на наличие возможных ошибок, систематизации и ввода в программу электронных таблиц.
- Предварительный анализ любого набора данных включает проверку надежности измерений, оценку эффективности любых манипуляций, изучение распределений отдельных переменных и выявление выбросов.
- Выбросы, которые кажутся результатом ошибки, непонимания или недостатка усилий, могут быть исключены из анализа. Критерии исключенных ответов или участников должны применяться одинаково ко всем данным и описываться при представлении результатов. Исключенные данные следует откладывать, а не уничтожать или удалять на случай, если они потребуются позже.
- Описательная статистика рассказывает историю того, что произошло в исследовании. Хотя выводная статистика также важна, важно сначала понять описательную статистику.
- Обсуждение. Каковы по крайней мере два разумных способа справиться с каждым из следующих выбросов на основе обсуждения в этой главе? (a) Участник, оценивающий рост обычных людей, оценивает рост одной женщины как «84 дюйма». (б) В исследовании памяти на обычные объекты один участник набрал 0 баллов из 15. (в) В ответ на вопрос о том, сколько у него «близких друзей», один участник пишет «32».
- Браун, Н. Р., и Синклер, Р. К. (1999). Оценка количества сексуальных партнеров в течение жизни: мужчины и женщины делают это по-разному. Журнал сексуальных исследований, 36 , 292–297. ↵
- Бем, Д. Дж. (2003). Написание статьи для эмпирического журнала. В JM Darley, MP Zanna и HL Roediger III (Eds.), Полный академический: руководство по карьере (2-е изд., стр. 185–219). Вашингтон, округ Колумбия: Американская психологическая ассоциация. ↵
Методы исследования в психологии: интерпретация данных
После того, как психологи разработают теорию, сформулируют гипотезу, проведут наблюдения,
и собирают данные, они получают много информации, как правило, в виде
числовые данные. Термин статистики относится к анализу и
интерпретация этих числовых данных. Психологи используют статистику для организации,
обобщать и интерпретировать полученную информацию.
Термин статистики относится к анализу и
интерпретация этих числовых данных. Психологи используют статистику для организации,
обобщать и интерпретировать полученную информацию.
Описательная статистика
Чтобы систематизировать и обобщить свои данные, исследователям нужны числа. опишите, что произошло. Эти числа называются описательный статистика . Исследователи могут использовать гистограммы или гистограммы , чтобы показать, как распределяются данные. Представление данные таким образом позволяют легко сравнивать результаты, видеть тенденции в данных и быстро оценить результаты.
Пример: Предположим, исследователь хочет узнать, сколько часов студенты учатся на трех разных курсах. В каждом курсе 100 студенты. Исследователь проводит опрос десяти студентов в каждом курсов. На опросе он просит студентов написать сократить количество часов в неделю, которые они тратят на изучение этого курс. Данные выглядят так:
| Курс A | Курс B | Курс C | |||
| Студент | Часов в неделю | Студент | Часов в неделю | Студент | Часов в неделю |
| Джо | 9 | Ханна | 5 | Мина | 6 |
| Питер | 7 | Бен | 6 | Соня | 6 |
| Зои | 8 | Игги | 6 | Ким | 7 |
| Ана | 8 | Луи | 6 | Майк | 5 |
| Хосе | 7 | Киша | 7 | Джейми | 6 |
| Ли | 9 | Лиза | 6 | Илана | 6 |
| Джошуа | 8 | Марк | 5 | Ларс | 5 |
| Рави | 9 | Ахмед | 5 | Ник | 20 |
| Кристен | 8 | Дженни | 6 | Лиз | 5 |
| Лорен | 1 | Эрин | 6 | Кевин | 6 |
Чтобы лучше понять, что означают эти данные, исследователь может построить
их на гистограмме. Гистограммы или гистограммы для трех курсов могут выглядеть
например:
Гистограммы или гистограммы для трех курсов могут выглядеть
например:
Измерение центральной тенденции
Исследователи обобщают свои данные, вычисляя показателей центральная тенденция , такая как среднее значение, медиана и мода. наиболее часто используемой мерой центральной тенденции является среднее значение , что является средним арифметическим баллов. Среднее значение рассчитывается по складываем все баллы и делим сумму на количество баллов.
Однако среднее значение не является хорошим итоговым методом для использования, когда данные
включают несколько очень высоких или очень низких оценок. Распределение с
несколько очень высоких результатов называют распределением с положительной асимметрией . Распределение с несколькими очень низкими показателями называется распределением с отрицательной асимметрией . Среднее положительное значение
асимметричное распределение будет обманчиво высоким, а среднее отрицательное
асимметричное распределение будет обманчиво низким.
