Основные идеи НЛП | НЛП для начинающих
Если хотя бы один человек умеет делать что-то, то этому могут научиться и другие
Классная идея — мы можем научиться умениям других людей. Я уже писал, что НЛП по сути — это система моделирования успешности. Вот как раз для того, чтобы выяснить как работает чужое умение и обучать этому других. И это может касаться практически чего угодно: слепой печати, хождению по углям, игре на бирже, продажам, умению знакомиться или управлять собственным состоянием.
Кстати, однажды один из студентов Джона Гриндера для сдачи зачёта по мастерскому курсу НЛП, смоделировал углехождение. После этого начал проводить семинары по обучению этому самому углехождению, которые внезапно оказались весьма популярны.
Ричард Бендлер, когда к нему попался человек с фобией, отправился — как завещал великий Милтон Эриксон — искать людей, которые сами справились со своими фобиями. Нашёл пару таких, выяснил как они это сделали и создал технику «Быстрое Лечение Фобий». Которая позволяет расправиться с фобией минут за 15 (правда-правда — мы проходим эту технику на тренинге Успешное Мышление 2 и вполне быстро разные фобии убираем).
Которая позволяет расправиться с фобией минут за 15 (правда-правда — мы проходим эту технику на тренинге Успешное Мышление 2 и вполне быстро разные фобии убираем).
Лично я, когда сертифицировался на мастера НЛП, моделировал слепую печать на компьютере. И сам научился, и других обучил. Вот прямо сейчас этой моделью пользуюсь.
Каждый человек уникален или «карта не территория»
Мужчины ошибаются думая, что все женщины разные, а женщины ошибаются думая, что все мужчины одинаковые.
Шутка.
Действительно — у каждого из нас свой личный жизненный опыт, свой взгляд на мир. И этот взгляд на мир уникален. Личный взгляд на мир человека в НЛП называют картой (в отличие от окружающего мира, который, соответственно, называют территорией). Карты бывают разные — более или менее удобные, подходящие и подробные. Единственное, какими они не бывают — правильными или неправильными, потому что это только описание, модель.
И, естественно, карта не является территорией, точно так же как очень подробное описание борща (даже с картинками) самим борщом не станет. Так вот, большинство проблем возникает когда человек пытается мир (территорию) подогнать под свою карту, вместо того, чтобы перерисовать свою карту так, чтобы она была более удачной для данной территории. И, в какой-то мере, всё то, чем занимается НЛП — это помощь человеку в нахождении таких личных карт мира, которые помогут ему стать более успешным, удачливым, счастливым и здоровым. Естественно, если он этого хочет.
Очень многие приёмы изменения в НЛП связаны с «расширением» карты — поиском более широкого взгляда на ситуацию. Ну действительно, если у нас есть проблема, то решение находится где-то вне нашей карты мира.
 И для того, чтобы проблеме разрешить, надо карту расширить так, чтобы это самое решение в неё попало.
И для того, чтобы проблеме разрешить, надо карту расширить так, чтобы это самое решение в неё попало.За каждым поведением стоит положительное намерение
Намерение – это позитивная цель, которая лежит за любым нашим поведением. Что бы мы не делали — говорили, бегали, ругались, смотрели фильм, — всё это служит определённой цели. Мы чистим зубы для здоровья, покупаем новую обувь для удобства, а новую машину для престижа, читаем статьи для знаний, занимаемся сексом для удовольствия, пьём кофе по утрам для бодрости. Даже у вроде бы «негативного действия» — истерики, депрессия, аллергии, — практически всегда есть намерение. Когда спрашивали людей, которых спасли после попытки самоубийства, «зачем они это делали», они отвечали что-то вроде: «Я хотел наконец обрести спокойствие».
Всё что мы делаем, мы делаем для реализации собственных намерений.
Либо по-другому:
Каждое поведение служит для достижения какой-то положительной цели.

При этом нужно понимать, что вполне положительное намерение для его обладателя может реализовываться очень неприятно для других людей. Маньяк с топором в тёмном переулке может хотеть получить для себя удовольствие, воодушевление или уверенность в себе, но для попавших под его удовлетворение намерения, его поведение не слишком приятно.
Структура важнее содержания
Понимание структуры (формы) позволяет нам обобщать опыт и переносить его в другие контексты. Например, если у проблем общая структура, мы можем использовать для их решения аналогичные подходы. А зная структуру техник изменения, мы можем сами конструировать эти техники.
Вербальная и невербальная коммуникация
Калибровка
Люди говорят одно, но часто чувствуют и действуют сильно иначе. В НЛП есть такое важное понятие, как  И калибровка позволяет понять, что на самом деле человек чувствует, как к кому относится, чего хочет. И намного меньше обращать внимания на то, что он говорит.Так как говорить он может для того, чтобы понравиться, что от него ждут или что он считает более правильным сказать в данный момент. Или просто потому, что не осознал свои оценки и чувства. Калибровка позволяет сделать общение намного более точным и эффективным, а поведение человека намного более понятным.
И калибровка позволяет понять, что на самом деле человек чувствует, как к кому относится, чего хочет. И намного меньше обращать внимания на то, что он говорит.Так как говорить он может для того, чтобы понравиться, что от него ждут или что он считает более правильным сказать в данный момент. Или просто потому, что не осознал свои оценки и чувства. Калибровка позволяет сделать общение намного более точным и эффективным, а поведение человека намного более понятным.
Калибровка
У нас уже есть все необходимые ресурсы для достижения наших целей
Для того, чтобы из Москвы доехать до Саратова автомобилю требуется бензин (а поезду — электричество). И автомобиль, и бензин — это необходимые ресурсы для достижения цели в виде приезда в Саратов. Так вот, в НЛП предполагается, что у нас либо уже есть нужные ресурсы для достижения цели: стать более успешным, прекратить курить, общаться лучше или наконец написать этот доклад, — либо мы их можем найти.
По крайней мере думая так вы скорее добьетесь результата, чем медитируя на тему «почему я такой несчастный» и «у меня всё-равно ничего не получится, я не создан для счастья (успеха, замужества, достатка и обладания автомобилем BMW X5)».
Ресурсы
Экологическая проверка
В НЛП есть очень важная вещь — проверка экологии изменения. Это проверка последствий действий — не станет ли хуже после достижения целей? А то стал гендиректором, но заработал язву, перестал бояться высоты, упал с балкона и сломал палец, продемонстрировал уверенность и спокойствие во время разноса начальства и был уволен. Вот чтобы новые способности, навыки и убеждения не испортили жизнь, надо проверять заранее и подкручивать результат так, чтобы всё получилось хорошо.
Модели и техники
Модель в НЛП – это такое полезное описание (карта). Например, как уточнять, о чём говорит человек («мета-модель языка»), как во время общения изменить оценку («рефрейминг») или убеждение («фокусы языка»), в какой последовательности собирать информацию («SCORE»), типизация людей («мета-программы»).
Про модели можно почитать в Энциклопедии НЛП.
Техники НЛП – это пошаговые инструкции. Чаще всего техники описывают как решить какую-то проблему («Взмах», «Шестишаговый рефрейминг», «Быстрое лечение фобий», «Изменение личностной истории»). Но есть и про то, как правильно ставить цели («Хорошо сформулированный результат») или как лучше общаться («Стратегия эффективной коммуникации»).
На самом деле техники – это тоже модели, ведь они что-то описывают, и обычно весьма полезны.
Многие техники НЛП — это результат моделирования того, как люди успешно сами решали похожие проблемы. Например, «Стратегия эффективной коммуникации» является результатом моделирования успешных коммуникаторов, «Изменение личностной истории» смоделирована с великого Милтона Эриксона, того самого, которые создал эриксоновский гипноз, а «Быстрое лечение фобий» с людей, которые сами свои фобии убрали.
Описание различных техник в Энциклопедии НЛП.
Ценности, критерии и убеждения
Ценности – важные понятия для человека, обычно выражаемые абстрактными словами, вроде: счастье, свобода, справедливость, достаток. Так как ценности достаточно абстрактны, к ценностям прилагаются критерии – способы измерения реализации ценности. Например, ценность «достаток», а критерии достатка «заработок больше 150.000 в месяц, своя квартира, машина и дача».
Убеждения – правила жизни, описывающие как с ценностью взаимодействовать. Например, для ценности «любовь» убеждения могут быть:
— Самое важное в жизни – это любовь.
— Я недостоин любви.
— Настоящая любовь бывает только раз в жизни.
Убеждения могут разрешать и запрещать достижение ценности, описывать что нужно для её достижение и каковы её критерии.
 Например, даже если «любовь» для человека вещь очень важная, убеждение «я не заслужил любви» будет «запрещать» ему эту самую любовь получить.
Например, даже если «любовь» для человека вещь очень важная, убеждение «я не заслужил любви» будет «запрещать» ему эту самую любовь получить.Убеждения управляют нашей жизнью: либо человек делает что-то ради своих убеждений, либо не делает ничего.
Одно время никому не удавалось пробежать стометровку быстрее десяти секунд. Пока в 1968 Джим Хайнс не пробежал за 9,9 секунд. После этого быстренько все начали бегать быстрее, рекорд за рекордом. Сейчас рекорд 9,69. Ну не верили бегуны до Хайнса, что можно быстрее 10 секунд, в их реальности такой возможности не существовало. Пока этот гад оригинал Хайнс подло это убеждение не разрушил.
Убеждения являются и одними из важнейших фильтров восприятия. Если женщина не верит, что существуют порядочные (по её критериям) мужчины – они ей в жизни и не попадаются. А даже если попадаются, их поведение интерпретируется так, чтобы не дай бог под критерии не попал.

Наше отношение кодируется при помощи субмодальностей
В общении оценка и отношение составляет 85%. А вот внутри об отношении – важно, нравится, правильно, законно, моё, чужое, плохо, замечательно, верно, — мы узнаём при помощи так называемых субмодальностей.
Модальностями (сенсорными) в НЛП и психологии называют слух (аудиальная модальность), зрение (визуальная модальности) и чувства (кинестетическая модальность).
Например, мы можем образ отодвинуть или приблизить (что обычно усиливает переживание), сделать ярче или темнее (ослабляет переживание), раскрасить по-другому (тут уже от подбора цветов зависит) или размыть фон (делает объект важнее). Аналогично можно менять характеристики звуков и ощущений.
 А при помощи кинестетических субмодальностей вполне успешно можно научиться контролировать разные интересные состояниями, вроде творчества, повышенного внимания, опьянения или супермотивации.
А при помощи кинестетических субмодальностей вполне успешно можно научиться контролировать разные интересные состояниями, вроде творчества, повышенного внимания, опьянения или супермотивации.Подробнее про субмодальности в презентации.
Про субмодальности в Энциклопедии НЛП
Мы можем управлять состоянием при помощи якорей
Хотелось бы вам управлять собственным состоянием? Так, чтобы нажал на кнопку — и уверен в себе. Или спокоен, весел, бодр, расслаблен, сосредоточен. А точно так же управлять другими людьми — раз, и человеку хорошо? Или спокойно, весело и так далее? Наверняка же хотелось бы такую штуку — ну хотя бы попробовать. И такая штука есть — это якоря, такие метки в сознании, которые запускают нужное состояние.
На самом деле якоря — это условные рефлексы. Но слово якорь звучит более понятно.
При помощи якорей мы можем «включать» и «выключать» своё состояние: внимание, бодрость, спокойствие, мотивированность или творчество; можем перенести состояние из того места, где оно есть в то место, где его пока не хватает: например спокойствие и уверенность есть лёжа дома на диване, а при общении с клиентами его пока нет, вот с дивана к клиентам и можно перенести; можно управлять состоянием других людей, а так же разрушать старые уже не нужные якоря.
Классный инструмент — очень простой и полезный. В НЛП используется постоянно.
Про якоря в статье «О якорях»
M.A.NLP, NLP trainer Александр Любимов
Правила и техники НЛП для начинающих
Если вы хотя бы немного интересуетесь психологией, то о нейролингвистическом программировании (НЛП), наверное, тоже слышали. В статье мы постараемся объяснить три базовых правила НЛП и приведем несколько техник, которые помогут вам проверить действие системы в жизни. Не нужно никому платить и что-либо покупать: просто прочтите статью и проверьте НЛП в действии.
Три базовых правила НЛП
Прежде, чем перейти к практическим техникам, рассмотрим три правила нейролингвистического программирования, на которых строятся все учебные материалы, курсы, техники и методики изучения. Освоив три правила, вам будет гораздо проще и понятнее в дальнейшем.
Сознание влияет на тело, и наоборот
В этом постулате НЛП схоже с духовными практиками. Вы должны понять, что ваше сознание напрямую влияет на физическое здоровье и благополучие, и наоборот. Приведем простой пример. Допустим, вы едете в тесном общественном транспорте. Вам становится не комфортно, портится настроение. Это простой пример влияния тела на сознание.
Вы должны понять, что ваше сознание напрямую влияет на физическое здоровье и благополучие, и наоборот. Приведем простой пример. Допустим, вы едете в тесном общественном транспорте. Вам становится не комфортно, портится настроение. Это простой пример влияния тела на сознание.
Когда вы смотрите хороший фильм, общаетесь с интересными и приятными людьми, танцуете под любимую музыку – у вас улучшается настроение и самочувствие, физическое состояние. Достаточно вспомнить про эффект плацебо: еще в двадцатом веке ученые обнаружили, что фокус-группа больных гриппом, которые получали сахарные пустышки вместо медикаментов, выздоравливали не хуже, чем те, которые получали обычные таблетки. Сила нашей мысли – безгранична. Нужно просто настроиться на правильную волну.
Человек, который освоил НЛП, может воздействовать не только на других, но и способен менять физическое состояние организма и напрямую влиять на свое здоровье.
Объективный мир – субъективен
Сложная формулировка, за которой скрывается очень простой постулат – все мы видим мир по-разному. Стараясь быть максимально объективными, мы все равно накладываем свой субъективный опыт на восприятие той или иной ситуации. В философии это называется взаимоотношением терминов «объективная реальность и субъективная действительность». При этом, объективную реальность можно оценить только извне, и так как мы все живем в этом мире и в социуме, то объективным опытом не владеем.
Стараясь быть максимально объективными, мы все равно накладываем свой субъективный опыт на восприятие той или иной ситуации. В философии это называется взаимоотношением терминов «объективная реальность и субъективная действительность». При этом, объективную реальность можно оценить только извне, и так как мы все живем в этом мире и в социуме, то объективным опытом не владеем.
Главная задача НЛП – научить смотреть на мир через призму субъективного другого человека. Так вы поймете намерения его действий и сможете сделать коммуникацию более эффективной. Стараться быть объективным – бессмысленно, так как это нереально.
За каждым действием скрывается позитивное намерение
Все, что мы делаем, мы делаем с каким-либо положительным намерением. Апологеты НЛП считают, что каждый человек действует из каких-либо позитивных, но эгоистичных побуждений. Даже бескорыстно помогая другим, мы хотим признания или создания репутации «хорошего человека». Мы бегаем для здоровья, а злимся – для того, чтобы удовлетворить свои желания и так далее.
Мы бегаем для здоровья, а злимся – для того, чтобы удовлетворить свои желания и так далее.
Это совершенно нормально. В рамках НЛП вы должны научиться понимать, какие позитивные намерения лежат в основе поступков окружающих вас людей.
Приемы НЛП для начинающих
Нейролингвистическое программирование – глубокая наука, осваивать которую можно практически всю жизнь. Однако, мы обещали вам несколько простых приемов, применить которые вы сможете уже сейчас. Ниже – несколько несложных упражнений, которые дадут результат с минимальными усилиями.
Техника формирования цели SMARTEF
Это даже не техника, а шаблон, модель или трафарет построения целей правильно. Знаете ли вы, что большая часть успеха задуманного зависит от правильно сформулированной цели. Возможно, вашим желаниям суждено было бы сбыться при одном простом условии – Вселенная, да и вы сами должны понимать, чего именно хотите.
Строить цель по технике SMARTEF очень просто. Для этого она должна отвечать таким требованиям:
Для этого она должна отвечать таким требованиям:
Конкретность. Цель должна быть не расплывчатой, а конкретной. Хотите новый автомобиль? Сразу представляйте его в цвете, определенной модели, комплектации и модификации. А еще лучше – сходите в автосалон и выбирайте ваш автомобиль.
Измеримость. Представьте себе момент, когда вы уже достигли цели. Когда это произойдет, сколько времени, денег или сил вы потратите на ее достижение, насколько будете довольны?
Привлекательность. Мы уже писали, что мы делаем все из позитивных побуждений. Найдите свое – то, которое питает эта цель. Реализованные желания должны принести нам пользу.
Реализм. Нет смысла мечтать о том, чтобы полететь на Плутон в ближайшие 10 лет. Цель должна быть достижимой, вы должны четко представлять все ресурсы и инструменты, которые понадобятся для ее достижения.
Временные рамки. Цели без срока никогда не реализуются.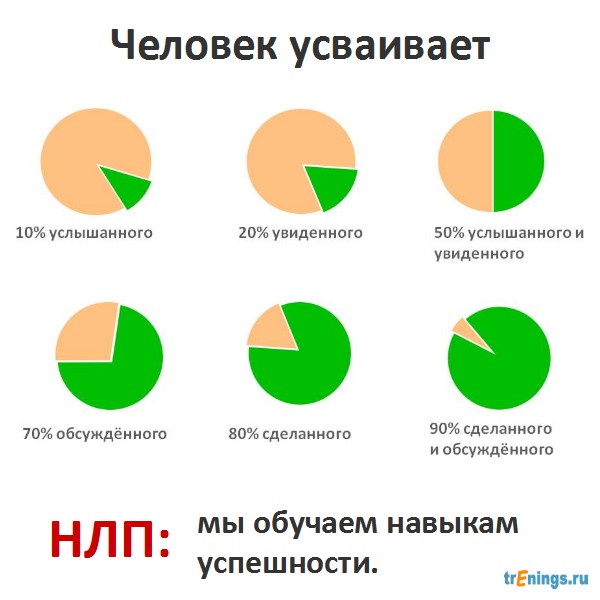 Всегда ставьте временные рамки: новая работа к маю, путешествие по Европе этой осенью и так далее.
Всегда ставьте временные рамки: новая работа к маю, путешествие по Европе этой осенью и так далее.
Экологичность. Параметр, который показывает, что вы приобретете (вторичные выгоды) после достижения цели, и что можете потерять, если не достигнете желаемого результата. Это своего рода риск-менеджмент.
Положительная формулировка в настоящем. Важно говорить и представлять цель такой, которая уже реализовалась. При этом, формулировка цели должна быть только положительной. Допустим: вместо «не хочу болеть» нужно представлять «я здоров».
Техника НЛП от Уолта Диснея
Неожиданно увидеть здесь именно одного из наиболее известных мировых мультипликаторов? Его методика творчества была взята специалистами по НЛП в качестве эффективного инструмента для достижения целей и правильной постановки задач.
Заключается она вот в чем: каждая ваша новая идея, мысль или цель должна пройти через три внутренних фильтра: мечтателя, реалиста и критика. Мечтатель отвечает за то, что он представит цель в настоящем, полностью выполненное задание или реализованную идею. Это именно та ваша составляющая, которая уже представила, как вы едете с ветерком на новом автомобиле.
Реалист сразу же начинает считать, сколько ресурсов, времени и сил понадобится вам для того, чтобы удовлетворить внутреннего мечтателя. Если фильтр реалиста не пройден, то цель нужно переработать.
Последний внутренний фильтр – критик. Он должен выявить слабые стороны в плане и идее еще до этапа его выполнения. По своему существу он противоположен мечтателю и оценивает реалиста и его предложения по достижению цели.
Работа с текущими ситуациями и воспоминаниями
В НЛП можно работать не только для улучшения будущего, но и для корректировки наших шаблонов мышления и поведения по отношению к тем ситуациям, которые уже произошли. Сейчас речь пойдет о том негативе, который мешает нам расслабиться, о негативных воспоминаниях.
Интересный факт, но в НЛП принято многие вещи трактовать буквально. Допустим, выражение «пробелы в памяти» или «белое пятно» помогло сформировать специалистам интересную технику работы с воспоминаниями. Если вы хотите что-то забыть, представьте ситуацию в своей голове и постепенно высветляйте его, буквально до «белого пятна». Просто попробуйте – негатив уйдет гораздо быстрее. А если хотите что-то быстрее вспомнить – постарайтесь в голове наполнить картинку яркими красками или «затемнить» ее.
Второй метод уменьшения негативных эмоций и воспоминаний – техника моделирования будущего. Это простое упражнение, которое называется «50 лет спустя». Суть его проста – просто представьте, насколько важна будет эта ситуация через 20, 50 лет? Как правило, все переживания по этому поводу просто уходят. Не верите – просто попробуйте!
Мы постарались собрать те упражнения и техники НЛП, которые вы можете применить уже сейчас и увидеть результат.
Курсы НЛП для начинающих в Москве: цены
Существует огромная разница между изучением каких-то вещей
и обнаружением того, чему еще можно научиться.
Ричард Бэндлер «Используйте свой мозг для изменений»
ЧТО ТАКОЕ НЛП
Что такое мир, в котором ты живешь? Это твой город, улица, дом, квартира, комната, монитор, на котором написаны эти слова. Это соседи, друзья, коллеги, однокурсники, или близкие тебе люди. Это эмоции и образы, которые возникают и исчезают при чтении этих предложений. Это твои мысли о том, как устроен этот мир и каким он должен быть. Мир – это весь твой прошлый, настоящий и будущий опыт и то, что находится за пределами этого опыта. НЛП – это язык описания этого мира, дающий возможность понять, что он из себя представляет, что происходит, кто ты в этом мире, собственные потребности и желания, то, что необходимо для реализации того, что ты хочешь и как это сделать. НЛП – это совокупность языков описания опыта, позволяющих подобрать персональный язык общения, как к каждому человеку, так и к самому себе и, следовательно, умение наладить удовлетворяющие и гармоничные взаимоотношения между ними. НЛП – это начало понимания того, что на самом деле означает понимать себя и других людей.
НЛП – это совокупность языков описания опыта, позволяющих подобрать персональный язык общения, как к каждому человеку, так и к самому себе и, следовательно, умение наладить удовлетворяющие и гармоничные взаимоотношения между ними. НЛП – это начало понимания того, что на самом деле означает понимать себя и других людей.
Люди больше времени трятят на обучение пользованию кухонной печью, чем собственными мозгами.
Так принято, что особый акцент на целенаправленном использовании вашего мышления иными способами,
чем вы уже это делаете — отсутствует.
Ричард Бэндлер «Используйте свой мозг для изменений»
ЗАЧЕМ НЛП
С самого момента своего создания НЛП использовалось, в первую очередь, для понимания тех людей, кто умеет систематически и профессионально достигать собственных целей в общении, для понимания того, как они это делают. Среди этих людей находятся как всемирно известный создатель гештальт психотерапии Фриц Перлз, основоположник семейного консультирования и семейной психотерапии Вирджиния Сатир, Милтон Эриксон, чьим именем было названо одно из самых известных и признанных направлений в гипнотерапиии – эриксоновский гипноз, а также множества других людей, общепризнанно выдающихся умением реализовывать то, что они хотят, ключевые паттерны поведения и мышления которых, известны как базовые модели НЛП, обучение которым происходит на курсе НЛП-Практик. Изучать НЛП означает учиться системно и целенаправленно мыслить и действовать, занимаясь тем, чем занимаешься, во всех контекстах собственной жизни, начиная с профессиональной деятельности и личной жизни и заканчивая общением с друзьями и планированием собственного будущего. НЛП — это способ научиться делать то, что еще не умеешь делать, но чему уже есть время начинать учиться.
Изучать НЛП означает учиться системно и целенаправленно мыслить и действовать, занимаясь тем, чем занимаешься, во всех контекстах собственной жизни, начиная с профессиональной деятельности и личной жизни и заканчивая общением с друзьями и планированием собственного будущего. НЛП — это способ научиться делать то, что еще не умеешь делать, но чему уже есть время начинать учиться.
Внутри нашего разума всего гораздо больше, чем мы подозреваем.
Снаружи всего намного больше, чем мы в состоянии заинтересоваться.
Ричард Бэндлер «Используйте свой мозг для изменений»
ЧТО ТАКОЕ КУРС НЛП-ПРАКТИК
Курс НЛП-Практик это общепринятый мировой стандарт в обучении НЛП, в который входит, как обучение мыслить в парадигме НЛП, так и интеграция в собственную жизнь базовых моделей и стратегий системного мышления, успешного общения и достижения целей, смоделированных за более чем сороколетнее существование НЛП. Любой из курсов НЛП-Практик в Институте НЛП полностью соответствуют Единому стандарту качества преподавания НЛП-Практик, принятому в Российском НЛП-Сообществе.
Базовое обучение основам НЛП
В нашем Институте существует несколько разновидностей базовых курсов НЛП-Практик.
НЛП-Практик «Манипуляция и лидерство»
НЛП-Практик Классический
ЭЛИТНЫЙ курс изучения НЛП
Лучшие техники Боевого НЛП
Рекомендуемая литература
10 лучших книг и учебников по НЛП
Наука НЛП требует серьезного подхода, но эта область знаний — интереснейшее направление в психологии. Предложенные книги будут полезны всем, интересующимся методами НЛП.
Нейро-лингвистическое программирование
НЛП – непростая наука, требующая серьёзного подхода. И тем не менее нейролингвистическое программирование остается одним из интереснейших и направлений в психологии. Книги, которые мы вам предлагаем прочитать, будут полезны всем, кто интересуется методами НЛП и настроен на понимание себя, окружающих и жизни в целом.
1. Боб Боденхамер, Майкл Холл «НЛП-практик»
Хорошо систематизированный сборник наиболее интересных материалов по нейролингвистическому программированию. В книге есть общие сведения об НЛП, описание применяемых методов, множество примеров и упражнения для усвоения материала. Книга будет интересна желающим получить представление об этой науке и тем, кто уже успел увлечься НЛП и хочет расширить свои знания. Если вы действительно хотите вникнуть в суть НЛП, без прочтения этой книги не обойтись.
2. Джозеф О’Коннор «НЛП. Практическое руководство по достижению желаемых результатов»
Информативный и весьма полезный справочник по НЛП. Из руководства вы почерпнете теоретические знания и узнаете о практике их применения. Автор предлагает эффективные практические приёмы для получения навыков самосовершенствования и внушения. Вы получите знания, позволяющие глубже понимать людей, и вникните в законы коммуникации. Информация, содержащаяся в практическом руководстве Д. О’Коннора, может быть применена в образовании, юриспруденции, менеджменте, бизнесе, спорте и т. д.
д.
3. Р. Бэндлер, Д. Гриндер «Из лягушек – в принцы»
Запись вводной лекции по НЛП, доработанная и адаптированная для прочтения. Материалы этой трехдневной лекции, прочитанной авторами в 1978 году, помогут составить общее впечатление о науке НЛП, понять базовые механизмы воздействия и научит мягко и тактично вести любого человека к цели. Методы НЛП работают даже в случаях, когда бессильны психологи. Книга рекомендована всем, кого интересуют вопросы коммуникаций между людьми: психологам, социологам, психотерапевтам и т. д.
4. Ричард Бэндлер «Рефрейминг. Ориентация личности с помощью речевых стратегий»
Работа одного из создателей нейролингвистического программирования Ричарда Бэндлера посвящена рефреймингу, его моделям и методам их использования. Рефрейминг служит инструментом переосмысления восприятия и поведения, позволяющего освободиться от деструктивных шаблонов. Лучше всего отражает суть рефрейминга рамка, окружающая рисунок – информация о содержании картины зависит от того, какой фрагмент попал внутрь рамки. Метод заключается в перемещении той же картинки в новые рамки. Р. Бэндлер предлагает познакомиться с приёмами выхода на определенные грани личности человека для блокировки нежелательных образов и выведению других на первый план.
Метод заключается в перемещении той же картинки в новые рамки. Р. Бэндлер предлагает познакомиться с приёмами выхода на определенные грани личности человека для блокировки нежелательных образов и выведению других на первый план.
5. Мэнли Холл «77 лучших техник НЛП»
В книге специалиста Майкл Холла собраны наиболее эффективные техники НЛП. Применение предложенных методов поможет в личностном развитии, умении общаться, раскрытии собственного потенциала. Знания приемов НЛП применимы к деятельности в сфере бизнеса, образовании, психологии, социологии, менеджменте. Книга рассчитана на широкий круг читателей и будет полезна каждому человеку, стремящемуся к саморазвитию.
6. Сергей Горин «НЛП. Техники россыпью»
Сборник фрагментов семинаров по НЛП, проводимых автором с 1993 по 1995 год. Примеры успешного взаимодействия психотерапевта с пациентами позволяют неспециалистам разобраться в предмете изучения. Единственное условие – владение базовыми терминами НЛП, без которых понимание текста будет осложнено. Описаны многие техники из арсенала Валерия Хмелевского – одного из авторитетов российской школы нейролингвистического программирования.
Описаны многие техники из арсенала Валерия Хмелевского – одного из авторитетов российской школы нейролингвистического программирования.
7. Грегори Бейтсон «Ангелы страшатся»
На решение некоторых вопросов миру требуются столетия – вспомните задачи Аристотеля и Декарта. Но и новые проблемы оказываются не проще старых. «Ангелы страшатся» Грегори Бейсона – попытка обозначить и охарактеризовать некоторые вновь возникшие вопросы. Автор анализирует историю развития человека, пользуясь собственной концепцией. Оригинальность доктрины состоит в описании реперных точек, проходя через которые сознание всего человечества и каждого индивидуума изменяется. Люди пересматривают свое отношение к миру, им открываются новые знания, заставляющие увидеть события по-новому.
Книга будет интересна всем, кто интересуется психологией, философией и саморазвитием.
8. Алдер «НЛП. Современные психотехнологии»
Вам будут интересны эффективные приемы, которыми пользуются разведчики, политики и топ-менеджеры.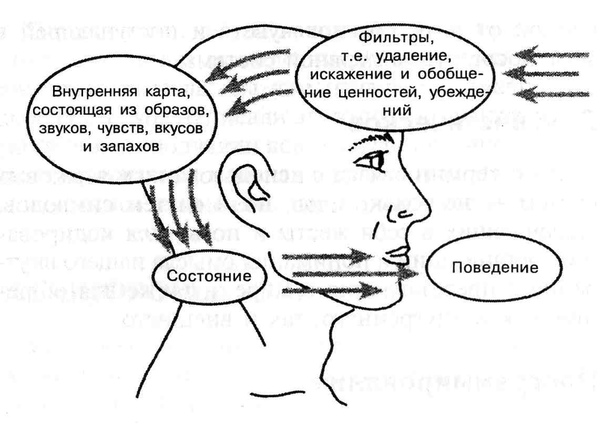 Вы можете овладеть искусством коммуникаций и попытаться применить их. Виртуозами общения рождаются немногие, у вас есть возможность научиться нюансам воздействия на собеседника и стать знатоком психологических приемов. Автор учит читателя внушать доверие, понимать сказанное и несказанное собеседником, управлять событиями и людьми.
Вы можете овладеть искусством коммуникаций и попытаться применить их. Виртуозами общения рождаются немногие, у вас есть возможность научиться нюансам воздействия на собеседника и стать знатоком психологических приемов. Автор учит читателя внушать доверие, понимать сказанное и несказанное собеседником, управлять событиями и людьми.
Книга будет полезна всем, кто хочет овладеть коммуникативными навыками и эффективно взаимодействовать с окружающими.
9. Сид Джекобсон «Состояние решённых проблем»
Сид Джекобсон хочет помочь читателям разобраться в основных идеях НЛП. По убеждению автора нейролингвистическое программирование представляет собой свободные методики, поэтому не следует ограничивать их применение устоявшимися положениями. Читателю предлагается самому определить содержание методов и приблизить их к собственной жизни. При этом в книге есть ответы на многие вопросы, а также краткий экскурс в историю НЛП и описание наиболее эффективных моделей и методов, основанных на общих законах мышления.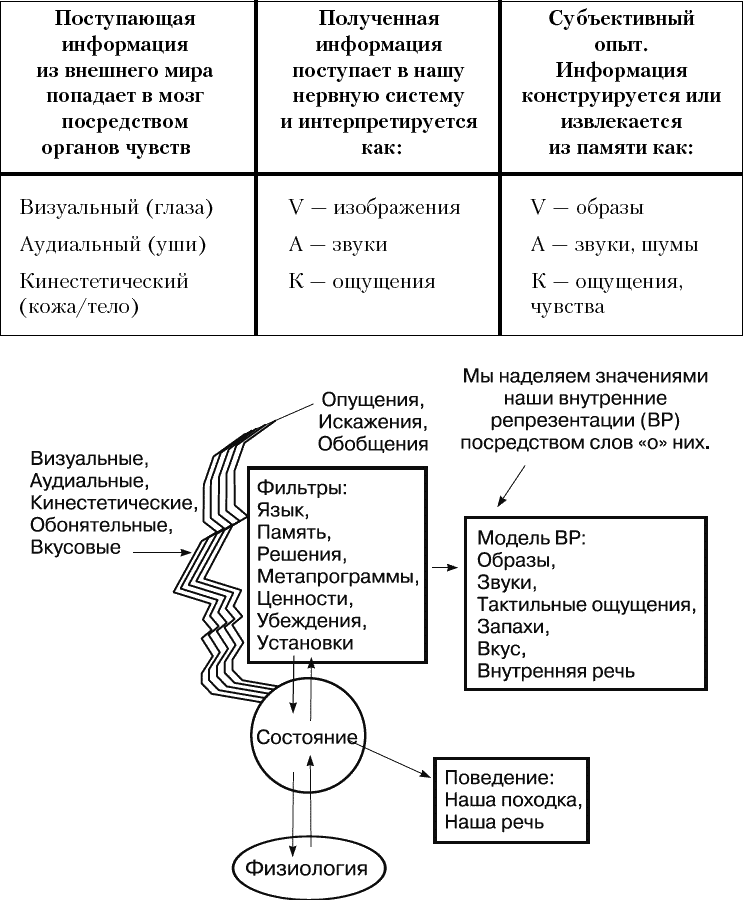 Методы Сида Джекобсона вполне применимы ко всем сферам жизни, поэтому книга может быть рекомендована самому широкому кругу читателей.
Методы Сида Джекобсона вполне применимы ко всем сферам жизни, поэтому книга может быть рекомендована самому широкому кругу читателей.
10. Стив Андреас «Шесть слепых слонов. Понимание себя и друг друга»
Стив Андреас «все помнит», удерживает «общую рамку НЛП» и стремится объединить многие области применения НЛП общими моделями. Тема книги – взаимосвязи, но рассматриваемые области настолько обширны, что за ходом авторской мысли не всегда легко уследить. Стив Андерс собрал в своем труде все: Я-концепцию, логические уровни, стратегию реальности, шизофрению, гипноз, временные рамки, рефрейминг, дабл-байнды, метапрограммы, субмодальности, критерии, позиции восприятия, «Чистый Язык», конгруэнтность и нюансы процесса терапии. Если вы не боитесь трудностей, ознакомьтесь с методологическим прорывом в НЛП.
© Старецкая Елена, BBF.RU
лучшие книги по НЛП (обзор +рекомендации)
Нейролингвистическое программирование (или же сокращенно – НЛП) является одним из ответвлений в психологии. Данная дисциплина считается очень молодой, ведь первые работы по ней начали издаваться в семидесятых годах прошлого столетия. Методы НЛП помогают многим мужчинам и женщинам бороться со своими психологичными проблемами.
Данная дисциплина считается очень молодой, ведь первые работы по ней начали издаваться в семидесятых годах прошлого столетия. Методы НЛП помогают многим мужчинам и женщинам бороться со своими психологичными проблемами.
Коме того, различные аспекты нейролингвистического программирования используют в маркетинге, продажах и в рекламе. Проверенные коммуникационные техники учат влиять на собеседников и даже менять их отношение к определенному явлению. Я собрал для вас лучшие книги по НЛП, которые помогут каждому разобраться в этом вопросе.
Зачем нужны книги по НЛП, и чем они помогут
Книги – это настоящие друзья и помощники человека. Именно при помощи печатных изданий многие люди меняют свою жизнь. На страничках хранится та информация, которую найти в других источниках практически невозможно. Литература предоставляет возможность расслабиться после сложного рабочего дня и стать более эрудированным. Сфера нейролингвистического программирования не стала исключением, качественные произведения из данной категории чтива позволяют научится ориентироваться в отрасли.
Лучшие книги по НЛП будут актуальными сразу по нескольким аспектам, они помогают людям усовершенствовать следующие качества:
- Разбираться в человеческих поступках и психологии.
- Без проблем заводить знакомства.
- Хорошо проводить семинары и лекции.
- Ставить цели и выполнять их.
- Быть внимательным к происходящему внутри себя
- Своими действиями влиять на других людей.
В произведениях собраны самые актуальные советы ученых, которые посвятили много лет науке. Таким образом, вы будете учиться на опыте настоящих практиков, сумевших достичь определенных высот.
Перечень лучших книг по НЛП
№1 «НЛП-практик». (Боб Боденхамер, Майкл Холл).
Это произведение претендует на звание лучшей книги по НЛП для начинающих. В сборнике собраны наиболее актуальные знания в сфере. Здесь читатели найдут общую информацию о нейролингвистическом программировании. Кроме того, на страничках отлично описаны все методы и приемы НЛП.
Кому стоит прочесть книгу? Данная работа отлично подходит для новичков, которые стремятся получить свои первые знания в этой сфере. Таким образом, у читателей появляется отличная возможность понять основы нейролингвистического программирования.
№2 «НЛП. Практическое руководство по достижению желаемых результатов». (Джозеф О’Коннор).
Эта книга поможет получить не только сугубо теоретические знания, но и научит применять их в жизни. Автор произведения помогает решать сложные жизненные задачи. По мнению Джозефа, умение использовать самовнушение является одним из самых важных навыков в жизни любого человека. Прочитав книгу, многие парни и девушки замечали за собой качественные изменения: у читателей получалось лучше ориентироваться в законах коммуникации.
Кому стоит прочесть книгу? Данное произведение подойдет для новичков в НЛП. Кроме того, полученные советы помогут практикующим специалистам в сферах продаж, юриспруденции и менеджмента.
№3 «Из лягушек — в принцы. Нейролингвистическое программирование». (Ричард Бендлер, Джон Гриндер).
Тандем американских авторов Бендлера и Гриндера предоставляют читателем интересное произведение. Сооснователи данной науки начали трудиться в сфере НЛП еще в семидесятых годах прошлого столетия. Именно эти ученые первыми обосновали концепцию нейролингвистического программирования и стали развивать отрасль. Информация на страничках издания поможет человеку понять свою сущность и научиться решать собственные проблемы. Хотите излечить свою старую фобию? Или же у вас есть мечта устранить ряд нежелательных привычек, которые негативно влияют на вашу жизнь и продуктивность? Тогда эта книга по НЛП подойдет лучше всего.
Кому стоит прочесть книгу? «Из лягушек — в принцы. Нейролингвистическое программирование» является одним из основных произведений в этом направлении психологии. Издание подойдет для людей, которые хотят изменить свою жизнь:
- поменять свои привычки;
- начать развиваться;
- стать на путь свой мечты.

Кроме того, книга будет интересна почитателям деятельности основателей данного учения — авторов Бендера и Гриндера.
№4 «Фокусы языка. Изменение убеждений с помощью НЛП (сборник)». (Роберт Дилтс).
Роберт Дилтс – человек разносторонний. Он является не только практикующим специалистом по нейролингвистическому программированию, но и сумел построить свою карьеру в качестве разработчика, создал ряд образовательный программ для учащихся и даже выпускал комиксы.
«Фокусы языка» помогают качественней взаимодействовать с другими людьми. Произведение учит приемам, позволяющим лучше обосновывать позицию и убеждать в своей правоте собеседников. По мнению автора, человеческий язык имеет огромную силу. Определенные речевые шаблоны могут преобразить восприятие событий. Многие любители литературы называют эту работу лучшим учебником по средствам убеждения собеседников.
Кому стоит прочесть книгу? Эта книга написана профессиональным языком, вчитываться в нее нужно очень вдумчиво. Произведение подойдет людям, мечтающим научиться влиять на жизни и действия окружающих словами.
Произведение подойдет людям, мечтающим научиться влиять на жизни и действия окружающих словами.
№5 «Рефрейминг. Ориентация личности с помощью речевых стратегий». (Ричард Бендлер).
Любой человек является личностью и состоит из множества уникальных характеристик. Согласно с мнением Ричарда Бендлера, индивидум должен понимать эту особенность, пытаясь добиться глобальных изменений в своем поведении. В книге отлично описаны практики рефрейминга (это специальный прием, что позволяет лучше взаимодействовать со своим внутренним «я»). Ричард Блендер описал большое количество ситуаций из реальной жизни, а также попытался проанализировать каждую из них.
Кому стоит прочесть книгу? Книга должна понравиться людям, которые занимаются «самокопанием». Если вам интересно изучать особенности человеческого мышления под призмой нейролингвистического программирования, тогда вы можете смело ознакомиться с этим трудом.
№6 «77 лучших техник НЛП». (М. Холл).

Майкл Холл является известным предпринимателем, сумевшим зарекомендовать себя в отрасли НЛП. Специалист из Колорадо стал известным благодаря ряду эффективных тренингов, а также из-за опубликования уникальных произведений. Название книги их списка говорит само за себя – в ней собраны лучшие техники, помогающие добиваться поставленных целей. В данном произведении собраны различные методы, что выведут читателя на новый уровень в образовании, переговорах, отношениях с людьми и в ведении бизнеса.
Кому стоит прочесть книгу? Произведение подойдет всем людям, которые пытаются усовершенствовать свои познания во многих отраслях человеческой деятельности.
№7 «НЛП для родителей». (Диана Балыко).
В список книг разряда «нлп для чайников» однозначно попадает это произведение, где указаны самые полезные советы по применению нейролингвистического программирования в практике с детьми. Русскоязычная писательница из Белоруссии сумела качественно описать особенности эмоционального развития подростков. Именно законы НЛП помогут родителям понять свое чадо, а также быть с ним на одной волне. Таким образом, любящие мамы и папы смогут проще справляться с детскими страхами и комплексами.
Именно законы НЛП помогут родителям понять свое чадо, а также быть с ним на одной волне. Таким образом, любящие мамы и папы смогут проще справляться с детскими страхами и комплексами.
Кому стоит прочесть книгу? Это произведение подойдет любому родителю, который ранее не изучал вопросы нейролингвистики. Книга предоставит шанс лучше разобраться в психологии ребенка и научиться быть с ним на одной волне. Важно использовать указанные советы на практике, чтобы знания не были получены напрасно.
№8 «Состояние решённых проблем». (С. Джекобсон).
Сид Джекобсон в своем произведении постарался при помощи лучших технологий нейролингвистического программирования решать проблемы, связанные с любыми сферами жизнедеятельности человека. Книга будет актуальной для каждого, потому что описанные законы используются практически везде. Автор качественно отразил на страничках книги свой богатый опыт в НЛП.
Кому стоит прочесть книгу? Данное произведение актуально не только для новичков в нейролингвистике, но и для более опытных читателей.
№9 «НЛП. Техники россыпью». (С. Горин).
Нейролингвистическим программированием в российских реалиях занимается ряд ученых. Среди самых популярных работ многие эксперты выделяют «НЛП. Техники россыпью» Сергея Горина. Житель Красноярского края написал книгу, которая базируется на его учебных семинарах. Ученый на страничках отобразил уникальную методику развития личности и предлагает каждому следовать его советам.
Кому стоит прочесть книгу? Произведение рассчитано на широкий круг читателей. Также работа интересна мужчинам и женщинам, которые хотят увидеть российский взгляд на современную когнитивистику.
№10 «НЛП в продажах. Убеди любого купить все». (Йохен Зоммер).
Европейский специалист нейролингвистического программирования на страницах книги сумел рассказать об основных техниках НЛП. Особое внимание он уделил особенностям работы с клиентами любого уровня. Здесь хорошо описаны универсальные фразы, помогающие завязать общение. Вы научитесь правильно реагировать на отказы и качественно подавать свою позицию. Приятным бонусом станет лаконичность произведения, ознакомиться с главными мыслями работы реально за пару десятков минут.
Вы научитесь правильно реагировать на отказы и качественно подавать свою позицию. Приятным бонусом станет лаконичность произведения, ознакомиться с главными мыслями работы реально за пару десятков минут.
Кому стоит прочесть книгу? Всем менеджерам по продажам, специалистам по маркетингу и обычным людям, мечтающим уметь лучше и убедительней доносить свою позицию. Кроме того, чтиво подойдет для почитателей литературы, у которых есть не очень много свободного времени на чтение.
Заключение
Нейролингвистическое программирование – это серьезная наука, на изучение которой люди тратят множество лет. Научиться понимать основы данного учения возможно быстрее при помощи специализированной литературы. Лучшие книги по НЛП помогут понять особенности работы человеческого мышления, предоставят шанс лучше понимать себя и окружающих, а также позволят достигать в своей жизни большего.
Полезные произведения по нейролингвистическому программированию можно читать в свое свободное время: в дороге на работу, после пробуждения или же перед сном. Уже через небольшой промежуток времени читатели обязательно заметят определенные изменения в своем поведении и смогут задействовать указанные практики в реальной жизни.
Уже через небольшой промежуток времени читатели обязательно заметят определенные изменения в своем поведении и смогут задействовать указанные практики в реальной жизни.
На этом у меня все. Если данная подборка книг оказалась для вас полезной — сохраните ее к себе. Ну, а если вам есть что добавить или остались вопросы — смело пишите в комментарии.
НЛП для начинающих | Фокусы разума
Человеческий мозг – это могущественный орган, который может гораздо больше, чем те задачи, с которыми сталкивается ежедневно. Это факт, который был подтвержден неоднократными медицинскими исследованиями и наукой не отрицается. Но даже зная эту информацию, думали ли вы когда-либо о том, чтобы «прокачать» свой мозг? Как раз этим и занимается НЛП – нейролингвистическое программирование, техники которого не потребуют от вас ничего, кроме ваших же мыслей.
Что такое техника НЛП
С биологической точки зрения у каждого человека мозг практически одинаков за исключением некоторых анатомических индивидуальных особенностей. Если все мысли исходят из этого «условно одинакового» для всех органа, то почему мы все настолько разные? Как получается, что одни легко заводят новых друзей, поднимаются вверх по карьерной лестнице, собирают вокруг себя полезные знакомства, а другие – неуверенны в себе и погрязли в собственных страхах? Ответ прост – просто некоторые научились пользоваться силой своего мозга и его инструментами, а другие нет
Если все мысли исходят из этого «условно одинакового» для всех органа, то почему мы все настолько разные? Как получается, что одни легко заводят новых друзей, поднимаются вверх по карьерной лестнице, собирают вокруг себя полезные знакомства, а другие – неуверенны в себе и погрязли в собственных страхах? Ответ прост – просто некоторые научились пользоваться силой своего мозга и его инструментами, а другие нет
Говоря о технике НЛП, человеческий мозг корректно называть сложным инструментом. Бесспорно, он потенциально очень могущественный и сильный, но в неумелых руках он бесполезен. Самым лучшим методом использования мозга является обучение. И как ни странно, все мы его используем. Только по-разному.
Каждый день мы чему-то учимся. Только делать это можно по-разному, и результат, соответственно, тоже будет отличаться. Иногда обучение нам, мягко говоря, не идет на пользу. В течение жизни мы можем научиться грустить по пустякам, обрести целый ряд фобий (это ведь тоже следствие тех или иных ситуаций и является обучением), стать неуверенными в себе, получить вредные привычки, в конце-концов.
Но можно учиться и по-другому. Можно стать уверенным в себе, можно поверить в свои силы. И совсем не страшно просить у начальника повышения зарплаты или пригласить симпатичную знакомую в кафе – если знать, как это делать правильно, используя свой мозг. Звучит банально, но все не так просто как кажется. Нейролингвистическое программирование призвано избавить от устоявшихся в нашем мозге программ, которые мешают нам развиваться и становиться лучше.
НЛП предусматривает использование сразу трех элементов: мысленный («нейро»), языковой («лингво») и программный (создание определенной матрицы поведения, нового шаблона). Простыми словами, это техника, которая поможет вам видоизменять свой мозг, совершенствовать его и использовать потенциал самого сильного органа человека себе во благо.
Кому нужно знать технику НЛП
Мы слукавим, если скажем, что НЛП – это наука или методика для избранных. Таковой ее можно назвать только потому, что далеко не каждый к ней приходит. Приемы, которые используют специалисты в НЛП, доступны каждому из нас: не нужно никаких особых навыков или сверхъестественных способностей, чтобы научиться управлять своим мозгом.
Приемы, которые используют специалисты в НЛП, доступны каждому из нас: не нужно никаких особых навыков или сверхъестественных способностей, чтобы научиться управлять своим мозгом.
Чем поможет использование таких приемов в реальной жизни:
- Вы избавляетесь от фобий и страхов, приобретенных в течение жизни.
- Вы отбрасываете устаревшие шаблоны и модели поведения, которые мешали развиваться и расти.
- Вы становитесь увереннее в себе и своих силах.
- Учитесь воздействовать на других людей и доносить до них свои мысли правильно, так, как они хотят это услышать.
Подобная техника уже давно используется в управлении и продажах. Но вопреки общепринятому мнению, главная задача НЛП – не управление другими людьми или манипулирование, а возможность изменять себя и свои пагубные привычки.
Изначально создатели самой науки (Дж. Гриндлер, Р. Бендлер) утверждали, что НЛП поможет избавиться от фобий и страхов, с которыми не справляется традиционная психология. Ученые уверены, что правильное использование техники поможет избавиться даже от аллергии, затяжной депрессии или даже ОРВИ. Представляете, насколько сильно вы недооценивали ваш мозг?
Бендлер) утверждали, что НЛП поможет избавиться от фобий и страхов, с которыми не справляется традиционная психология. Ученые уверены, что правильное использование техники поможет избавиться даже от аллергии, затяжной депрессии или даже ОРВИ. Представляете, насколько сильно вы недооценивали ваш мозг?
Мифы про НЛП среди начинающих
Но не стоит забывать о том, что техника НЛП воспринимается незнающими несколько искаженно. Сразу скажем, что кардинально изменить свою жизнь сразу после освоения тех или иных приемов не выйдет. Также, если вы не понимаете, чего конкретно хотите добиться (не глобально), то НЛП не поможет. К примеру, ответа на вопрос «почему все так плохо» или «почему не клеится в карьере» вы не получите. С этими вопросами поможет справиться хороший экстрасенс, или в крайнем случае – психолог. Они есть в нашем центре.
Когда НЛП не поможет:
- У вас нет четкой положительной цели.
 Например, «научиться общаться с людьми», «перестать бояться ответственности». Такие четкие задачи решаются методикой НЛП.
Например, «научиться общаться с людьми», «перестать бояться ответственности». Такие четкие задачи решаются методикой НЛП. - Управлять другими людьми. Каким бы экспертом в НЛП вы бы ни были, пределы воздействия на другого человека ограничиваются его сознанием. Да, вы сможете немного больше, чем без использования приемов, но переоценивать их значение не нужно.
- Вы не хотите учиться. Освоив только простые правила НЛП для начинающих, трудно добиться успеха и увидеть результат. Только постоянная практика и теоретическое обучение могут помочь.
Как лучше всего начать изучать НЛП начинающему? Идеально – получить консультацию у специалиста-практика. Он, исходя из своего опыта, сможет не только подсказать правильное направление для обучения, но и избавит от некоторых фобий и вредных привычек за несколько сеансов, это всегда вызывает интерес и доверие к силе НЛП.
В нашем центре Вы можете получать консультацию психолога-профессионала в области НЛП даже online. Записывайтесь к эксперту уже сейчас – используйте свои возможности по максимуму!
Записывайтесь к эксперту уже сейчас – используйте свои возможности по максимуму!
список лучших книг для начинающих и продвинутых
Нейролингвистическое программирование или НЛП представляет собой направление в психологии, фундаментом для которого служит копирование вербального и невербального поведения человека. НЛП создано в 60–70-х годах ХХ века, применяется на психологических тренингах.
Официальная психология НЛП не признаёт: иногда направление называют лженаукой. Это объясняется тем, что большая часть используемых им методик научно не обоснованы и неэффективны, хотя имеют место результаты исследований, доказывающие обратное.
Что такое НЛП
Нейролингвистическое программирование исследует опыт психотерапевтов и психоаналитиков, лингвистов, гипнотизёров чтобы сделать используемые ими методики общедоступными. НЛП – это:
- Владение навыком чёткой постановки цели. Умение видеть препятствия на пути к цели и устранять их.

- Внимательность и чувствительность к происходящему внутри себя и в окружающем внешнем мире. Навык нужен для контролирования собственной деятельности в процессе осуществления задуманного.
- Гибкость в действиях на пути к достижению цели, способность изменять действия до тех пор, пока не появится результат.
Часть названия «Нейро» указывает на то, что для отображения человеческого опыта нужно быть компетентным в сфере деятельности мозга, отвечающей за переработку, сохранение и распространение информации.
Важность языка при отображении устройства поведения, мышления, взаимодействия между людьми демонстрирует слово «Лингвистическое».
«Программирование» – предполагает точную последовательность этапов при продвижении цели. Это системность умозаключений и поведения.
Нейролингвистическое программирование – это сочетание умений, которые помогают быстро менять мышление человека (манипулировать), чтобы влиять на него. Подобное действие на психику не осознаётся объектом и производится с целью освобождения от проблем, развития или как лечебное средство.

Фундамент НЛП – взаимодействие с человеческим сознанием. В процессе работы с людьми применяется блокировка сознательного с целью высвободить бессознательное.
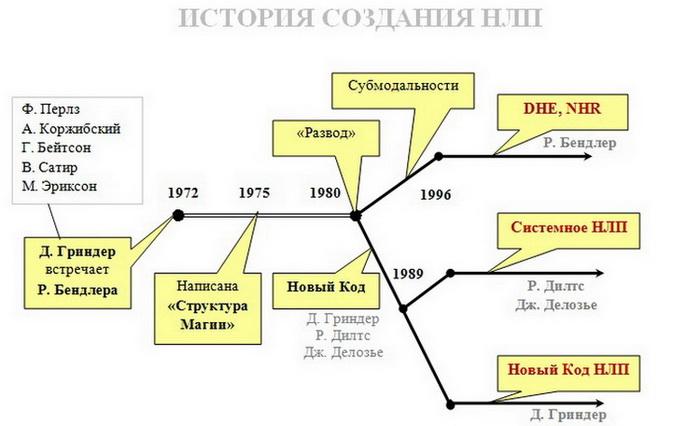
История возникновения нейролингвистического программирования
Разработка нейролингвистического программирования началась в конце 60-х годов прошлого века в университете Калифорнии учёными во главе с антропологом Грегори Бейтсоном. Исследование призвано было выявить закономерности результативного общения некоторых психотерапевтов с пациентами.
Ричард Бендлер и Джон Гриндер изучали методики, приёмы, техники, способы взаимодействия, анализировали их, наблюдая за работой психотерапевтов с подопечными. Мониторингу подверглись методики, применяемые Вирджинией Сатир, Милтоном Эриксоном, Фрицем Пёрзлом.
Позднее исследованные методы были организованы как виды и показаны в форме моделей воздействия людей друг на друга. Выводы проведённого исследования изложены в трудах «Структура магии. Том 1» (1975), «Структура магии. Том 2» (1976). Совместно с Вирджинией Сатир в 1976 году написана книга «Изменения в семье».
Том 1» (1975), «Структура магии. Том 2» (1976). Совместно с Вирджинией Сатир в 1976 году написана книга «Изменения в семье».
Итогом исследований стала метамодель, которая послужила основой для продолжения изучения. Так возникла практическая психология, точнее отдельное направление, именуемое «нейролингвистическое программирование».
В начале 80-х годов ХХ века каждый из создателей НЛП стал следовать отдельным путём, что обусловило появление к концу 80-х годов нескольких объединений с единственными в своём роде подходами. В это же время НЛП попало в Россию. Первые русские учёные из Новосибирска, обучал их сам Джон Гриндер. Он преподавал почти у всех российских тренеров, дважды проводил семинары в России: в 1997 и 2004 году.
Использование НЛП
Нейролингвистическое программирование учит понимать себя и людей рядом, наблюдательности и влиянию коммуникативными и психотерапевтическими методами. НЛП применяется людьми в таких сферах жизни:
- Ораторское искусство.

- Психотерапия.
- Журналистика.
- Менеджмент.
- Учёба.
- Коммерческая деятельность.
- Актёрское мастерство.
- Закон и право, юриспруденция.
- Организация времени и его эффективное использование.
Освоение НЛП-практик помогает совершенствовать мастерство коммуникации, обуславливает личностный рост, лечить от страхов и фобий, поддерживать здоровье психики и работоспособность на нормальном уровне.
Как этому научиться
Техники НЛП доступны для любого человека. Овладеть ими не составит труда. Об этом свидетельствуют основные положения учения.
Выделяются три основных ступени обучения:
- Стандартный курс «НЛП-Практик» предпочтительнее, если интересует исключительно умения в сфере общения и консультирование. Также «НЛП-Практик» рекомендуется для начинающих. Продолжительность подобного курса составляет 21 день. Выпускники получают квалификацию НЛП-практик, что свидетельствует о владении методикой и умении применять её при проведении практик для начинающих.
 «НЛП-Практик» – базовый образовательный курс, обучение в котором построено по принципу от простого к сложному.
«НЛП-Практик» – базовый образовательный курс, обучение в котором построено по принципу от простого к сложному. - Если появится желание углубить познания, поработать с убеждением и моделированием – поможет курс «НЛП-Мастер».
- «НЛП-Тренер» научит работать с аудиторией, ознакомит с особенностями обучения нейролингвистическому программированию.
Тренинги и очные курсы длятся месяцами, а за обучение приходится выложить кругленькую сумму. Но не всё так печально. Большинство техник можно освоить самостоятельно.
Для этого нужно читать специальные книги, посвящённые НЛП, прилежно применять усвоенные техники в практической деятельности. Усовершенствовать умения по нейролингвистическиму программированию позволит непрерывное использование приобретённых познаний и навыков в жизни.
Разработчики НЛП во время моделирования техник знаменитых психотерапевтов применяли несколько законов, которые использовали эти профессионалы. Все законы связаны в систему пресуппозиций – аксиом-инструментов, делающих применяемые техники результативными.
Книги по НЛП
По нейролингвистическому программированию написана не одна книга: их великое множество. Зачастую подобные книги содержат не так много полезной информации, как хотелось бы и читать их, ожидая впечатляющего результата бессмысленно. Лучшие в этой области, наиболее известны и полезны следующие книги:
А «НЛП-практик». Авторами книги являются Боб Боденхамер и Майкл Холл. Книга вобрала в себя самые интересные материалы. Включает общие сведения, описание методик, техник, упражнений, примеров. «НЛП-практик» одинаково высоко оценена людьми, которые впервые заинтересовались учением, а также теми, кто уже имел какие-то познания в этой сфере и захотел их усовершенствовать.
Б Книга «Из лягушек – в принцы» Ричарда Бэндлера и Джона Гриндера предназначена для специалистов сферы психология (психотерапевты, социологи, психологи), а также всем, кому интересна психология взаимодействия между людьми. Ознакомиться с содержанием книги будет полезно для начинающих обучение НЛП.
В «Состояние решённых проблем» – книга С. Джекобсона, в которой описывается универсальная модель. Она может использоваться людьми для решения проблем в любой области жизнедеятельности. Фундаментом для модели послужили законы мышления, жизни и деятельности.
Г «Рефрейминг. Ориентация личности с помощью речевых стратегий» – авторство принадлежит Ричарду Бэндлеру. В книге рассматривается психология рефрейминга, то есть изменения мышления и восприятия с целью избавления от неблагоприятных психических шаблонов. Читать произведение с интересом будет не только действующий практик или специалист, изложенные модели и методики применения могут с успехом использоваться обычными людьми.
Манипуляция и НЛП
Любое активное взаимодействие между людьми – манипуляция. Общаясь между собой, люди на бессознательном уровне хотят получить реакцию собеседника. Если есть цели, достичь которых в одиночку невозможно манипуляция при общении наблюдается в 100% случаев.
Манипулировать другими людьми можно явно или скрыто, отличие в том, что в первом случае человек озвучивает свою цель или то, какую реакцию он желает увидеть. Ежедневно с самого рождения между людьми происходит взаимодействие, которое сопровождает манипуляция.
Ежедневно с самого рождения между людьми происходит взаимодействие, которое сопровождает манипуляция.
Психология определила, что манипулировать человеческим сознанием можно с помощью специальных методов:
- Гипноз и транс.
Гипноз известен человечеству с древнейших времён, в настоящее время подобный метод применяется как средство лечения зависимостей, недугов и фобий. Каждый человек впадает в состояние транса естественным образом: точка концентрации внимания сдвигается, происходит погружение в собственные мысли. Всё чем овладели люди, произошло, когда мозг переключился на другой режим работы, находился в состоянии транса (состоянии изменённого сознания). Глубокий транс (гипноз) считается наиболее уязвимым состоянием чтобы манипулировать сознанием: человек воспринимает информацию через органы чувств, логика отключается, критичность отсутствует.
Психология разработала техники, как добиваться поставленных целей. НЛП представляет собой грамотную систематизацию всего самого лучшего. Здесь объединились методики когнитивной психологии, гештальт психотерапии, бихевиоризма и другие. Приёмы, которые собрала психология в НЛП легко превратить в пособие по манипулированию человеческим сознанием. Причём обнаружить подобные действия может тот, кто сам владеет такими методиками.
Здесь объединились методики когнитивной психологии, гештальт психотерапии, бихевиоризма и другие. Приёмы, которые собрала психология в НЛП легко превратить в пособие по манипулированию человеческим сознанием. Причём обнаружить подобные действия может тот, кто сам владеет такими методиками.
- Психотронное оружие.
В открытых источниках найти информацию о таком оружии невозможно. Нет даже неопровержимых доказательств того, что оно существует на самом деле, так как информация засекречена. Психотронное оружие представляет собой волны направленного действия, посредством которых производится манипуляция поведением человека или толпы (колебания волн заставляют людей паниковать, бежать или остановиться). Фундаментом для создания оружия послужило то, что изучила психология как наука.
Институты и курсы НЛП – неформальные, так как психология, психотерапия и психиатрия официально не признают нейролингвистическое программирование. Объясняется это тем, что методика теоретически не обоснована и не имеет научного подтверждения эффективности.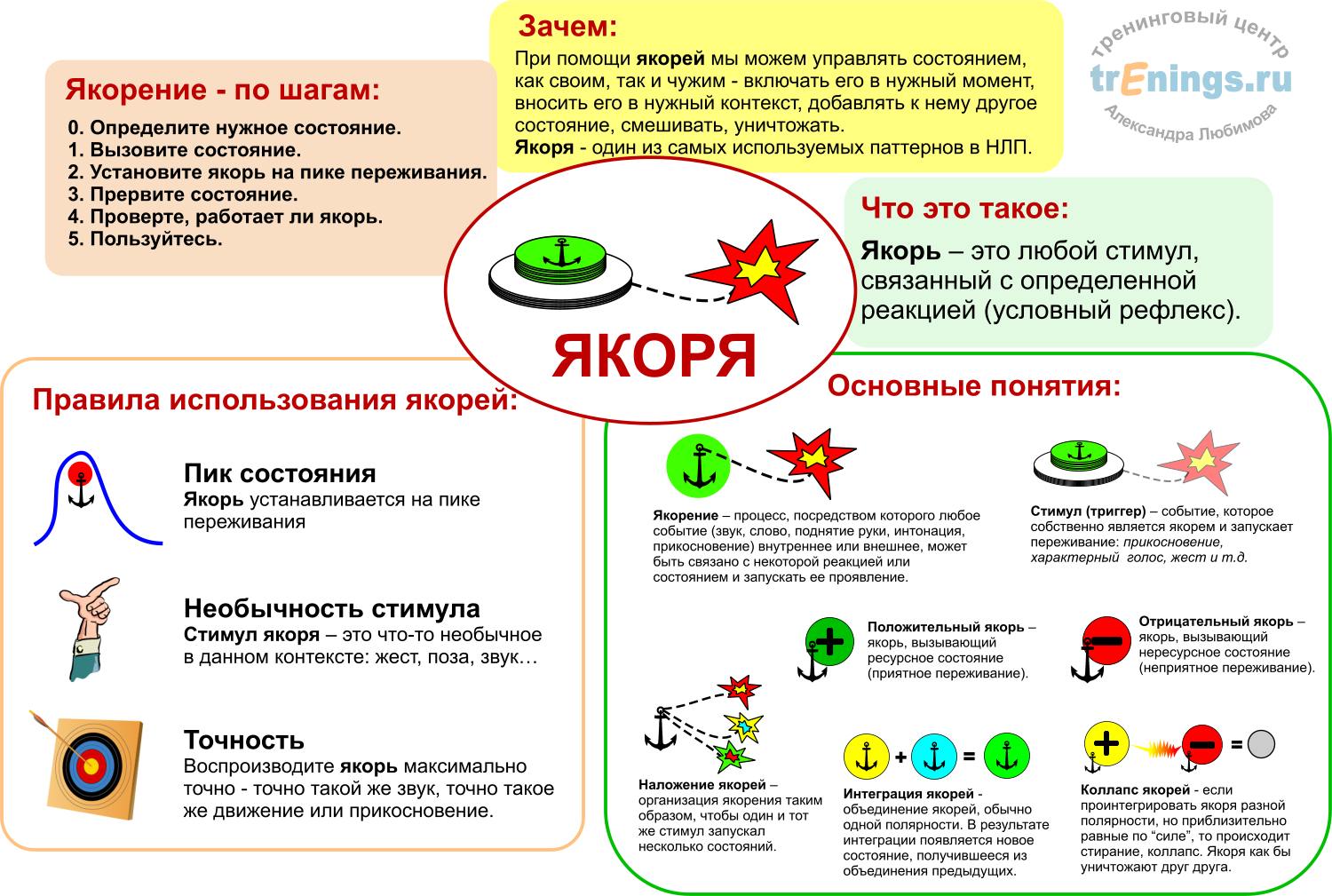 Однако все используемые приёмы воздействия на сознание и мышление человека базируются на подтверждённых и доказанных наукой законах, положениях, правилах, разработках психологии, психотерапии.
Однако все используемые приёмы воздействия на сознание и мышление человека базируются на подтверждённых и доказанных наукой законах, положениях, правилах, разработках психологии, психотерапии.
Руководство по обработке естественного языка для начинающих | Томас Плапингер
источникКогда я начал свой путь в области науки о данных, одним из самых увлекательных является то, что пытается понять значение и влияние слов, обработка естественного языка (НЛП).
Один из величайших аспектов НЛП — это то, что оно охватывает множество областей вычислительных исследований, от искусственного интеллекта до компьютерной лингвистики, и все они изучают взаимодействие между компьютерами и языком людей.В первую очередь он связан с программированием компьютеров для точной и быстрой обработки большого количества корпусов естественного языка.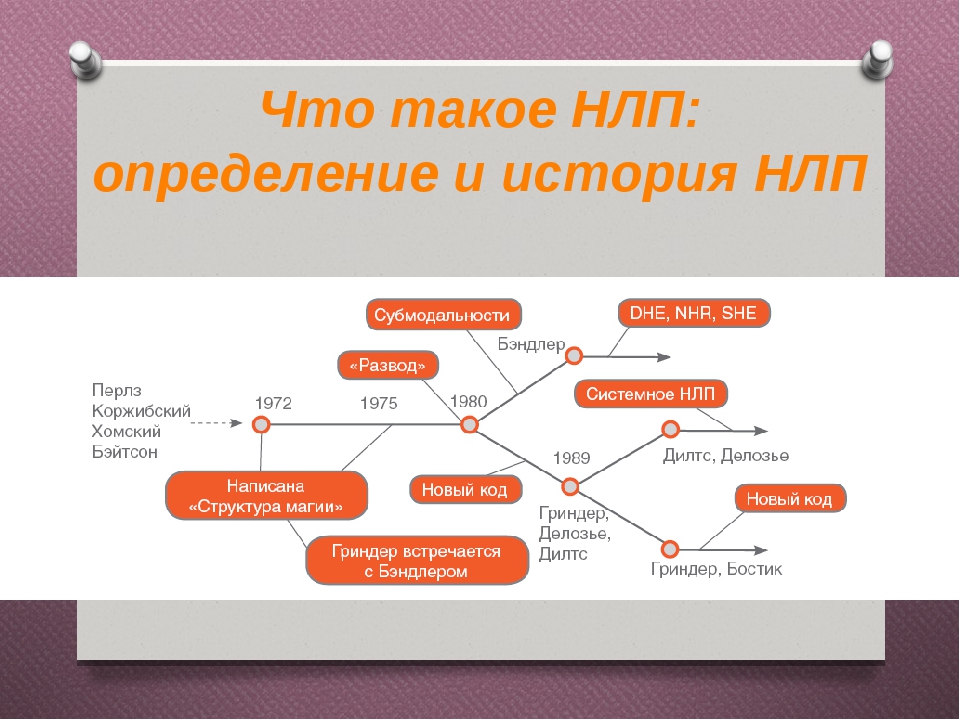 Что такое корпуса естественного языка? Это изучение языка, выраженного реальными языками. Это комплексный подход к пониманию набора абстрактных правил из текста и отношений, которые язык имеет с другим.
Что такое корпуса естественного языка? Это изучение языка, выраженного реальными языками. Это комплексный подход к пониманию набора абстрактных правил из текста и отношений, которые язык имеет с другим.
В то время как НЛП стало еще более актуальным с компьютерной промышленной революцией в современную эпоху, на самом деле оно было детищем удивительного Алана Тьюринга, который, помимо помощи во взломе немецкой машины кодирования Enigma, также написал статью под названием «Вычислительная техника и интеллект. », Который предложил первое серьезное использование связи человеческого языка с компьютерами.Благодаря тому, что технологии постоянно присутствуют в нашей повседневной жизни, мы стали свидетелями того, насколько влиятельным может быть НЛП для нашей повседневной жизни с помощью революционных инструментов, таких как Google Translate, IBM Watson, распознавание речи, генерация и анализ настроений.
Однако, как и все остальное, у НЛП есть несколько проблемных областей и недостатков. Он изо всех сил пытается создать язык, который естественным образом тек бы, когда человек говорит, подобно тому, как вы читаете плохой сценарий фильма, и это звучит как компьютерный разговор.Хотя есть методы, чтобы попытаться понять изменения в тоне, НЛП продолжает бороться с пониманием таких вещей, как сарказм, и обнаружением таких вещей, как юмор. Однако это область большого количества исследований, и я с нетерпением жду того дня, когда произойдет «прорыв сарказма». Если ничего другого, то лучше понимать случайные текстовые или мгновенные сообщения от друга.
Он изо всех сил пытается создать язык, который естественным образом тек бы, когда человек говорит, подобно тому, как вы читаете плохой сценарий фильма, и это звучит как компьютерный разговор.Хотя есть методы, чтобы попытаться понять изменения в тоне, НЛП продолжает бороться с пониманием таких вещей, как сарказм, и обнаружением таких вещей, как юмор. Однако это область большого количества исследований, и я с нетерпением жду того дня, когда произойдет «прорыв сарказма». Если ничего другого, то лучше понимать случайные текстовые или мгновенные сообщения от друга.
Некоторые из наиболее полезных инструментов для компьютерной науки и обработки данных, доступных в настоящее время:
CountVectorization, Hash Vectorization, Term Frequency-Inverse Document Frequency (TF-IDF), Lemmatization, Stemming, Parsing и Sentiment Analysis.
CounterVectorization — это инструмент библиотеки SciKitLearn, который принимает любую массу текста и возвращает каждое уникальное слово как функцию с подсчетом количества раз, когда это слово встречается. Хотя это может генерировать множество функций, которые являются некоторыми чрезвычайно полезными параметрами, которые помогают избежать этого, включая stop_words, n_grams и max_features. Стоп-слова создают список слов, которые не будут включены в качестве функции. Основное использование этого словаря — «английский», где он избавляется от незначительных слов, таких как «is, the, a, it, as», которые могут появляться довольно часто, но практически не влияют на нашу конечную цель.Ngram_range выбирает, как вы можете группировать слова вместе. Вместо того, чтобы НЛП возвращало каждое слово отдельно, вы можете получить такие результаты, как «Привет снова», если оно равно 2, или «Увидимся позже», если оно равно 3. Max_features — это количество функций, которые вы выбираете для создания. Если вы выберете для него значение «Нет», это означает, что вы получите все слова как функции, но если вы установите его равным 50, вы получите только 50 наиболее часто используемых слов.
Хотя это может генерировать множество функций, которые являются некоторыми чрезвычайно полезными параметрами, которые помогают избежать этого, включая stop_words, n_grams и max_features. Стоп-слова создают список слов, которые не будут включены в качестве функции. Основное использование этого словаря — «английский», где он избавляется от незначительных слов, таких как «is, the, a, it, as», которые могут появляться довольно часто, но практически не влияют на нашу конечную цель.Ngram_range выбирает, как вы можете группировать слова вместе. Вместо того, чтобы НЛП возвращало каждое слово отдельно, вы можете получить такие результаты, как «Привет снова», если оно равно 2, или «Увидимся позже», если оно равно 3. Max_features — это количество функций, которые вы выбираете для создания. Если вы выберете для него значение «Нет», это означает, что вы получите все слова как функции, но если вы установите его равным 50, вы получите только 50 наиболее часто используемых слов.
Хеширующий векторизатор преобразует текст в матрицу вхождений, используя «трюк хеширования».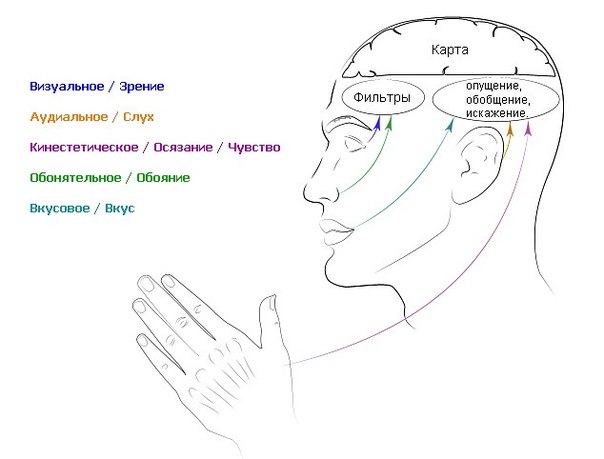 Каждое слово сопоставляется с характеристикой, а с помощью хеш-функции оно преобразуется в хеш-код.Если слово снова встречается в теле текста, оно преобразуется в тот же признак, что позволяет нам считать его в том же признаке, не сохраняя словарь в памяти.
Каждое слово сопоставляется с характеристикой, а с помощью хеш-функции оно преобразуется в хеш-код.Если слово снова встречается в теле текста, оно преобразуется в тот же признак, что позволяет нам считать его в том же признаке, не сохраняя словарь в памяти.
TF-IDF показывает, какие слова наиболее различают различные части текста. Это особенно полезно, если вы пытаетесь увидеть разницу между словами, которые часто встречаются в одном документе, но не появляются в других, что позволяет вам интерпретировать что-то особенное в этом документе. Это зависит от частоты использования термина, частоты появления слова и частоты обратного преобразования документа, независимо от того, является ли оно уникальным или общим для всех документов.
Лемматизация — это процесс, с помощью которого изменяемые формы слов группируются вместе для анализа как единого аспекта. Это способ использования предполагаемого значения слова для определения «леммы». Это во многом зависит от правильного нахождения «предполагаемых частей речи» и истинного значения слова в предложении, абзаце или более крупных документах. Примерами лемматизации являются то, что «бег» является базовой формой для таких слов, как «бег» или «бег», или что слова «лучше» и «хорошо» находятся в одной лемме, поэтому они считаются одинаковыми.
Примерами лемматизации являются то, что «бег» является базовой формой для таких слов, как «бег» или «бег», или что слова «лучше» и «хорошо» находятся в одной лемме, поэтому они считаются одинаковыми.
Стемминг очень похож на лемматизацию в том, что он группирует слова вместе, но в отличие от лемматизации, он берет слово и отсылает его обратно к его основной или корневой форме. На самом деле, на лучших примерах, которые я нашел, чтобы описать это, нужно возвращать Стемминг к его базовой форме. «Стебли», «Стебель», «Стебель», «Стемтизация» — все они основаны на одном слове «стержень».
Синтаксический анализ обычно используется для анализа строки слов для формирования в соответствии с правилами грамматики. Для НЛП это анализ строки слов, в результате чего получается дерево синтаксического анализа, раскрывающее синтаксические отношения между словами, которые могут содержать семантику.Однако недостатком синтаксического анализа является то, что когда и что анализируется, полностью зависит от пользователя, поскольку любой абзац может быть проанализирован любым способом, от отдельных символов до целых предложений и т. Д.
Д.
Анализ настроений в его простейшем определении — это извлечение интерпретации или субъективного значения слова из документа или набора документов для определения «отношения» к определенному слову или набору слов. Одно из самых больших его применений — это социальные сети в таких местах, как Facebook, Twitter и другие, для определения тенденций общественного мнения, частоты появления слова в определенном тональном контексте и интерпретации тона групп слов.
Перед тем, как проводить любой анализ, я настоятельно рекомендую вам отфильтровать и очистить любой документ, с которым вы имеете дело. Одна из лучших функций, с которыми я слишком легко сталкивался, была создана одним из моих учителей, Марком Маммертом. Хотя он ориентирован на очистку html-файла с помощью Use of Beautiful soup, его можно легко адаптировать для других очисток НЛП.
def review_to_words (raw_review):
#Remove html
review_text = BeautifulSoup (raw_review) .get_text ()
#Remove non-letter - Utilized Regex Library
letter_only = re.a-zA-Z] "," ", review_text)
# Преобразовать в нижний регистр и разбить на отдельные слова
words = letter_only.lower (). split ()
# Преобразовать стоп-слова в набор и удалить их
стоп = set (stopwords.words ("english"))
meanful_words = [w для w в слове , если не w в остановках]
# Соедините слова обратно в одну строку, разделенную пробелом и вернуть результат
return ("" .join (meanful_words))
Мир НЛП большой и сложный и продолжает оставаться областью большого количества исследований.Существует множество полезных инструментов, каждый из которых имеет чрезвычайно полезное применение при интерпретации и использовании мира слов.
Я считаю, что для пользователей Python наиболее полезными источниками НЛП будут библиотека Sci-Kit Learn и библиотека NLTK.
8 бесплатных ресурсов для начинающих по изучению естественного языка
NLP можно назвать одной из самых популярных областей машинного обучения. Сила этой технологии изменила то, как мы привыкли взаимодействовать с миром.В этой статье мы перечисляем 8 бесплатных онлайн-ресурсов для изучения обработки естественного языка.
Сила этой технологии изменила то, как мы привыкли взаимодействовать с миром.В этой статье мы перечисляем 8 бесплатных онлайн-ресурсов для изучения обработки естественного языка.
(Список в произвольном порядке)
1 | Обработка естественного языка
About: Этот онлайн-курс охватывает от базового до продвинутого НЛП и является частью специализации «Продвинутое машинное обучение» от Coursera. Вы можете записаться на этот курс бесплатно, где вы узнаете об анализе настроений, резюмировании, отслеживании состояния диалога и т. Д.Темы, которые вы изучите, такие как введение в классификацию текста, языковое моделирование и маркировку последовательностей, модели семантики в векторном пространстве, задачи от последовательности к последовательности и т. Д. По завершении вы сможете создать своего собственного диалогового чат-бота, который поможет с поиск на сайте StackOverflow.
Формат: Курс
Нажмите здесь, чтобы узнать
2 | Обработка естественного языка в Microsoft
О себе: Это курс для самостоятельного обучения, который даст вам полное представление о передовых технологиях, применяемых в НЛП. Продолжительность этого курса составляет 6 недель, на нем вы получите подробный обзор обработки естественного языка и того, как использовать классические методы машинного обучения. Вы узнаете о статистическом машинном переводе, методах глубокого обучения с подкреплением, применяемых в NLP, многомодальном языке Vision-Language, а также о моделях глубокого семантического сходства (DSSM) и их приложениях.
Продолжительность этого курса составляет 6 недель, на нем вы получите подробный обзор обработки естественного языка и того, как использовать классические методы машинного обучения. Вы узнаете о статистическом машинном переводе, методах глубокого обучения с подкреплением, применяемых в NLP, многомодальном языке Vision-Language, а также о моделях глубокого семантического сходства (DSSM) и их приложениях.
Вы также узнаете, как применять модели глубокого обучения для решения проблем машинного перевода и разговора, глубоко структурированные семантические модели для поиска информации и приложений естественного языка, модели глубокого обучения с подкреплением в приложениях на естественном языке и модели глубокого обучения для субтитров изображений и визуальных ответов на вопросы. .
Формат: Курс
Нажмите здесь, чтобы узнать
3 | Обработка естественного языка с помощью глубокого обучения
About: Это серия лекций по НЛП, проводимая Стэнфордским университетом, где вы познакомитесь с передовыми исследованиями в области глубокого обучения, применимыми к НЛП. Минимальная продолжительность серии составляет 1 час, и в нее включены темы: НЛП с глубоким обучением, векторные представления слов, глобальные векторы для представления слов, классификация окон слов и нейронные сети, обратное распространение, анализ зависимостей, введение в TensorFlow и другие подобные темы.
Минимальная продолжительность серии составляет 1 час, и в нее включены темы: НЛП с глубоким обучением, векторные представления слов, глобальные векторы для представления слов, классификация окон слов и нейронные сети, обратное распространение, анализ зависимостей, введение в TensorFlow и другие подобные темы.
Формат: Видео
Нажмите здесь, чтобы посмотреть
4 | Обработка естественного языка, Университет Карнеги-Меллона,
О нас: Этот курс предоставляется Университетом Карнеги-Меллона, который охватывает различные способы представления человеческих языков (например, английский и китайский) в качестве вычислительных систем и различные способы использования этих представлений для написания программ, которые делают аккуратные вещи с текстом и речью. данные, такие как перевод, обобщение, извлечение информации, естественные интерфейсы к базам данных, диалоговые агенты и т. д.Курс включает в себя некоторые идеи, имеющие ключевое значение для машинного обучения и лингвистики.
Формат: PDF и видео
Нажмите здесь, чтобы узнать
5 | Глубокая обработка естественного языка
Информация: Это репозиторий GitHub, который содержит курс по глубокому НЛП Оксфордского университета в виде слайдов лекций и видео. Этот курс сосредоточен на последних достижениях в области анализа и генерации речи и текста с использованием рекуррентных нейронных сетей.Вы познакомитесь с математическими определениями соответствующих моделей машинного обучения и получите связанные с ними алгоритмы оптимизации. Курс охватывает ряд приложений нейронных сетей в НЛП, включая анализ скрытых измерений в тексте, преобразование речи в текст, перевод между языками и ответы на вопросы.
Формат: Видео и слайды
Нажмите здесь, чтобы узнать
Смотрите также6 | Обработка естественного языка с помощью Python
Информация: Это электронная версия книги «Обработка естественного языка с помощью Python» Стивена Берда, Юана Кляйна и Эдварда Лопера. Эта книга представляет собой скорее практический подход, в котором используется Python версии 3, и вы изучите различные темы, такие как языковая обработка, доступ к текстовым корпусам и лексическим ресурсам, обработка необработанного текста, написание структурированных программ, классификация текста, анализ структуры предложения и многое другое.
Эта книга представляет собой скорее практический подход, в котором используется Python версии 3, и вы изучите различные темы, такие как языковая обработка, доступ к текстовым корпусам и лексическим ресурсам, обработка необработанного текста, написание структурированных программ, классификация текста, анализ структуры предложения и многое другое.
Формат: Электронная книга
Щелкните здесь, чтобы прочитать
7 | НЛП для начинающих, использующих NLTK
О : это серия видео, в которых вы узнаете об основах НЛП через НЛТК.Видео в основном концентрируется на очень полезной функции в НЛП, называемой распределением частот. Вы научитесь рассчитывать, табулировать и строить графики частотного распределения слов.
Формат: Видео
Нажмите здесь, чтобы узнать
8 | Обработка речи и языка
About: Это электронная книга авторов Дэна Джурафски и Джеймса Х. Мартина, в которой вы узнаете от основ до совершенствования языковой обработки. Сюда входят следующие темы: нормализация текста, расстояние редактирования, регулярные выражения, языковое моделирование, логистическая регрессия, векторная семантика, нейронные сети, нейронные языковые модели и другие подобные связанные темы.
Сюда входят следующие темы: нормализация текста, расстояние редактирования, регулярные выражения, языковое моделирование, логистическая регрессия, векторная семантика, нейронные сети, нейронные языковые модели и другие подобные связанные темы.
Формат: Электронная книга
Нажмите здесь, чтобы узнать
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и соответствующие предложения, поделившись своей электронной почтой.Присоединяйтесь к нашей группе Telegram. Станьте частью интересного онлайн-сообщества. Присоединиться здесь. Амбика Чоудхури
Технический журналист, который любит писать о машинном обучении и искусственном интеллекте. Любитель музыки, сочинения и обучения чему-то нестандартному. Контакт: [адрес электронной почты]
Начало работы с обработкой естественного языка NLP для начинающих | от Uniqtech | Data Science Bootcamp
Обработка естественного языка (NLP) не должна быть простой! Но давайте попробуем упростить для новичков. Подпишитесь на нас, чтобы увидеть больше подобных статей для начинающих. Обновлено в августе 2020 г.
Подпишитесь на нас, чтобы увидеть больше подобных статей для начинающих. Обновлено в августе 2020 г.
Обработка естественного языка или НЛП — это подмножество области искусственного интеллекта. Это область, которая анализирует наш человеческий язык и принимает тексты в качестве входных данных. Весь текстовый набор данных, входные данные называются корпусом . Например, мы подсчитываем, сколько раз слово появляется в корпусе . Это количество называется частотой термина .
«Привет! Рад видеть тебя.Я просто хотел поздороваться ». # Предложение — это корпус. Частота термина «привет» равна 2, потому что оно встречается дважды в корпусе, если в нашем анализе регистр не учитывается («привет» равно «привет»). Если он чувствителен к регистру, то частота термина «Hi» равна единице, и TF слова «hi» также равна единице.
О периодичности сроков мы поговорим позже.
Практический совет: иногда важно учитывать регистр. Например, Trump может относиться к Дональду Трампу, Trump — это глагол, часто используемый в карточных играх, описывающий одну карту выше другой.Когда регистры не имеют значения, обычная предварительная обработка , очистка данных заключается в замене всего текста корпуса на нижний регистр. Понижение
Например, Trump может относиться к Дональду Трампу, Trump — это глагол, часто используемый в карточных играх, описывающий одну карту выше другой.Когда регистры не имеют значения, обычная предварительная обработка , очистка данных заключается в замене всего текста корпуса на нижний регистр. Понижение lower_case_corpus = corpus.lower () Функция .lower () является методом строки Python. Например, «Привет!» станет «привет!». Часто предположение, что верхний и нижний регистр эквивалентны, упрощает поиск, обработку и приводит к уменьшению более надежного корпуса
Общие задачи обработки естественного языка | общие задачи НЛП : сегментация предложений, токенизация, удаление стоп-слов, тегирование части речи, распознавание сущности имени.
Codecademy.com объясняет модель мешка слов: «Модель мешка слов суммирует частоты каждого слова в документе, при этом каждое уникальное слово является его собственной характеристикой , а его частота — значением .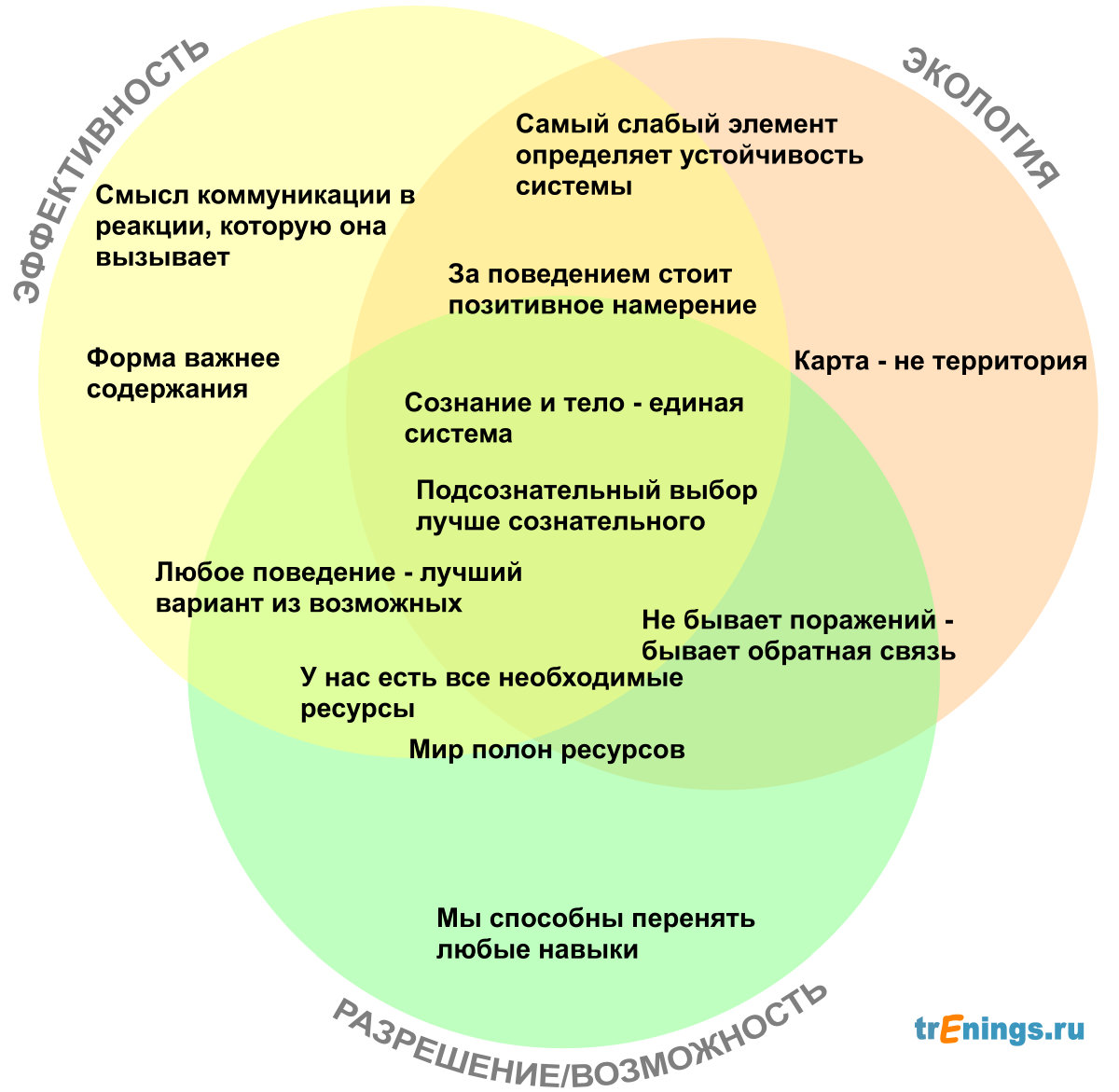 ”
”
Совет от профессионала: BoW или bow означает «мешок слов» в контексте НЛП.
Если вы не изучали машинное обучение, слово функция не имеет смысла. Есть уловки, которые могут помочь вам понять. Мы можем представить вывод пакета модели слова в виде словаря / хэш-карты Python пар ключ-значение или в виде листа Excel.Функции — это ключи в словаре или заголовки столбцов на листе Excel. Функции — это содержательные представления данных. Машинное обучение изучает функции и прогнозирует результаты, называемые метками .
Например, полезные функции данных о людях — информация, которая описывает людей — может включать в себя: рост, пол, имя, государственный идентификационный номер и т. Д.
Pro Подсказка: что такое размерность функции ? Какой размер или количество элементов? Он равен размеру словарного запаса в корпусе.
corpus = ["Вы читаете руководство Uniqtech. Мы говорим об обработке естественного языка, также известной как NLP.Хотите узнать больше? Узнайте больше о машинном обучении сегодня!"]
# if use corpus = "... "
# ошибка приема
# ValueError: ожидается итерация по необработанным текстовым документам, получен строковый объект. из sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer ()
bow = count_vect.fit_transform (corpus)
bow.shape # (1,22) count_vect.get_feature_names ()
# [u'about ', u'aka', u'are ', u'by', u'language ', u'learn', u'learning ', u'like ', u'machine', u'more ', u'natural', u'nlp ', u'processing', u'reading ', u'talking', u'to ', u'today', u'tutorial ', u'uniqtech', u'we ', u'would', u'you '] bow.toarray ()
#array ([[2, 1, 2, 1, 1, 2, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2]])
Совет от профессионалов: что делает CountVectorizer в соответствии с документацией Sklearn? «Преобразование коллекции текстовых документов в матрицу счетчиков токенов» и возвращает разреженную матрицу scipy. sparse.csr_matrix Просто к вашему сведению. Не думай об этом сейчас.
sparse.csr_matrix Просто к вашему сведению. Не думай об этом сейчас.
Имена функций возвращаются функцией count_vect.get_feature_names () и bow.toarray () дает нам частоту соответствующих функций. Например, первое слово «about» встречается в корпусе дважды, поэтому частота его равна 2. Последнее слово «you» также встречается дважды.
Чем это полезно? Эта распространенная модель на удивление мощна. В Интернете есть некоторая критика автора книги 50 оттенков серого : утверждается, что она не является искушенным автором, потому что в ее книгах используется только ограниченный английский словарный запас.Очевидно, люди обнаружили, что она слишком часто использует простые не описательные слова, такие как любовь и вздох . Ниже представлен мем, который высмеивает 50 оттенков серого .
Как люди узнали, что автор часто использует вздох ? Количество слов, частота слов, конечно же!
Если мы прочитаем этот частотный анализ слов трилогии «50 оттенков серого», нам действительно придется прокрутить довольно далеко вниз, чтобы увидеть сложное слово, которое также часто используется, например, бормотание .
Некоторые спорят, однако именно потому, что автор использует легко читаемый разговорный стиль, серия приобрела широкую читательскую аудиторию и популярность.
Удивительно, но эта простая модель довольно информативна и уже вызывает интересную дискуссию.
Подробнее о пакете слов
Удаление стоп-слова… не: Не все слова в корпусе считаются достаточно важными, чтобы быть функциями . Некоторые из них, например a, the и , называются стоп-словами , которые иногда удаляются из набора классов функций для улучшения результатов модели машинного обучения. Число встречается в книге почти 5000 раз, но это не означает ничего особенного, поэтому его можно удалить из нашего набора данных.
В модели «мешок слов» ни грамматика, ни порядок слов не имеют такого значения.
Pro Совет: экземпляр модели «мешок слов» часто хранится в переменной с именем bow , что может сбивать с толку, потому что вы можете думать о луке и стрелах, но это акроним от «мешок слов»!
Пакет слов позволяет построить гистограмму (распределение вероятностей) каждого слова с учетом метки класса. Затем можно использовать байесовскую модель для вычисления апостериорных вероятностей метки класса, например, равной 0 или 1, если видно слово (слова).
Затем можно использовать байесовскую модель для вычисления апостериорных вероятностей метки класса, например, равной 0 или 1, если видно слово (слова).
Пример рабочего процесса обработки естественного языка и конвейера NLP:
Конвейер очистки данных для текстовых данных
- очистка (регулярные выражения)
- разделение предложений
- изменение на нижний регистр
- удаление стоп-слов (наиболее часто встречающиеся слова на языке)
- stemming — demo porter stemmer
- POS tagging (часть речи) — demo
- существительное chunking
- NER (распознавание сущности имени) — demo opencalais
- deep parsing — попробуйте «понять» текст.
Обратите внимание на тонкую, но важную разницу между стеммингом и лемматизацией.
Мы можем думать о некоторых из этих задач как о выборе функций, задачах разработки функций: включая определение языковых функций, таких как существительные, глаголы и сущности.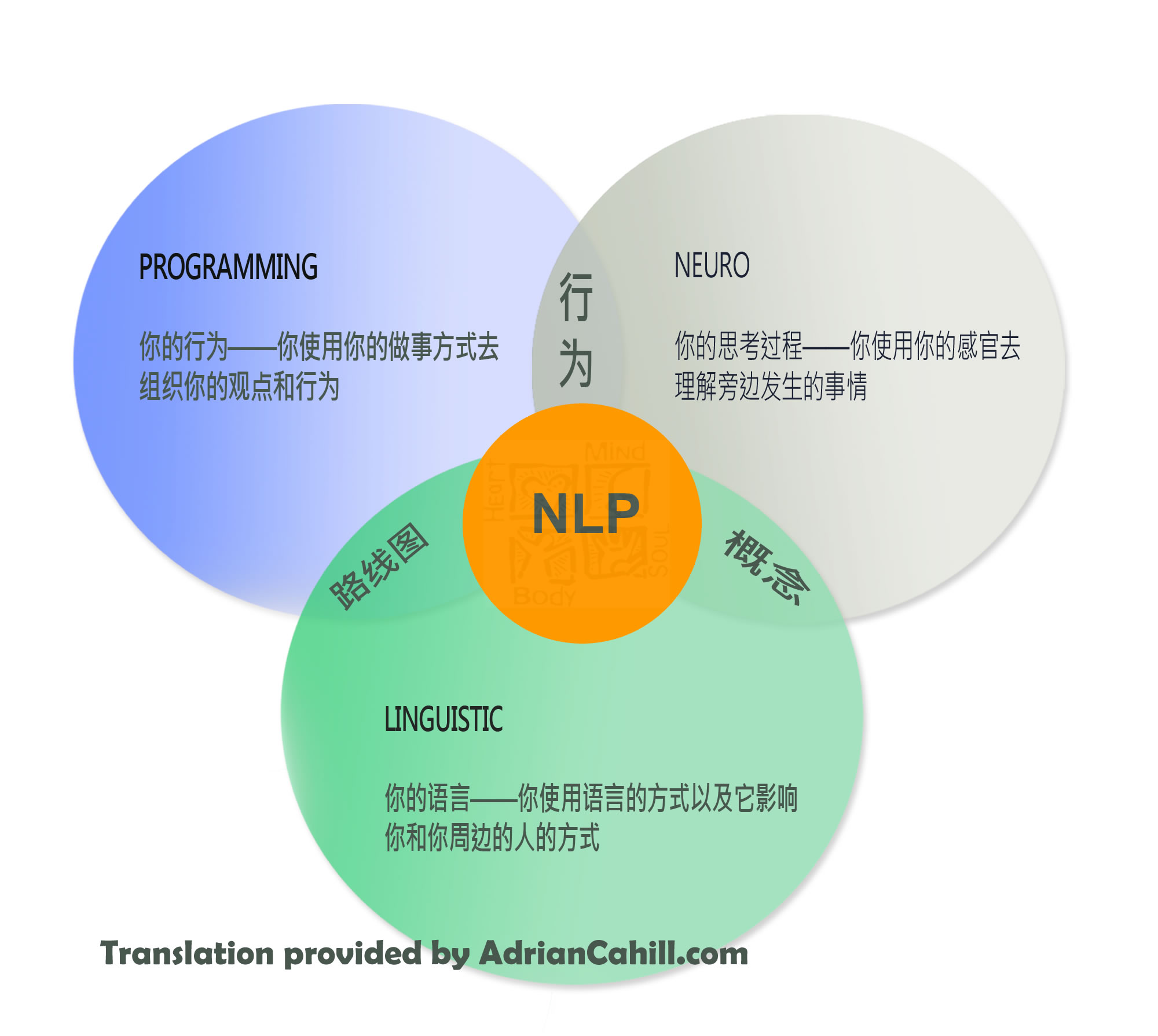
Стоп-слова — это слова, которые могут не содержать ценной информации.
В некоторых случаях важны стоп-слова. Например, исследователи обнаружили, что стоп-слова полезны для выявления негативных отзывов или рекомендаций.Люди используют такие предложения, как «Это не то, что я хочу». «Это может быть не лучший матч». Люди могут чаще использовать стоп-слова в отрицательных отзывах. Исследователи выяснили это, сохранив стоп-слова и добившись лучших результатов прогнозирования.
Хотя обычно удаляют стоп-слова и возвращают только чистый текст, удаление стоп-слов не всегда дает лучшие результаты прогнозирования. Например, , а не рассматривается в некоторых библиотеках NLP, но , а не , является очень важным словом в негативных обзорах или рекомендациях при анализе настроений.Например, если покупатель заявляет «, я не буду покупать этот продукт снова и не приму возмещение. На самом деле, совсем не подходящее совпадение », слово« не »является сильным сигналом того, что этот обзор отрицательный. Положительный отзыв может показаться, ну, положительным! «Продукт мне очень нравится! Мне это очень понравилось. Совсем не то, чего я ожидал ». В этом случае отрицательные отзывы используют слово «не» в 3 раза больше.
Удаление знаков препинания также может дать лучшие результаты в некоторых ситуациях.
Удаление стоп-слова также может уменьшить размер входного набора данных, что упрощает и ускоряет обработку и вычисление набора данных.
Удаление стоп-слов помогает сократить корпус, облегчить вычисление набора данных
Пунктуация не всегда полезна для предсказания смысла текстов. Часто они удаляются вместе со стоп-словами. Что означает удаление знаков препинания? Это означает сохранение только буквенно-цифровых символов. Уроки программирования с регулярными выражениями могут заполнить книги! Просто используйте эту изящную функцию ниже для коротких текстов. Для более длинных текстов, требующих большей вычислительной мощности, используйте повторяющиеся генераторы для итерации по каждой строке текста и сохраняйте только буквенно-цифровые символы.a-zA-Z0-9 \ s] + «,» «, corpus)
corpus
#returns ‘Вы читаете учебник от Uniqtech Мы говорим об обработке естественного языка, также известной как NLP. Хотите узнать больше? Узнайте больше о Machine Learning today ‘
Продолжайте, просто используйте описанный выше метод и не изобретайте колесо.
Pro Совет: в python также встроена функция буквенно-цифровой проверки ialnum () . Есть еще один .isalpha () только возвращает истину для алфавитов, число не будет истинным.
Хакеры всегда придумывают причудливый код регулярных выражений! Это становится все красивее.
из nltk.tokenize import RegexpTokenizer a regex tokenization
RegexpTokenizer (r '\ w +') # токенизировать любое слово длиной> 1,
# эффективно удалять все знаки препинания
Tokenization: разбивать текст на токены. Пример: разбиение предложений на слова и многое другое сгруппируйте слова на основе сценариев. Существуют также -граммовая модель и -граммовая модель .
Базовая токенизация - 1 грамм , n грамм или мультиграмм полезны, когда фраза дает лучший результат, чем одно слово, например «Я не люблю банан». один грамм - это я _space_ делаю _space_, а не _space_, как _space_ банан. Это может дать лучший результат с 3-граммовой моделью: не люблю, не люблю, не люблю банан, люблю банан _space_, банан _space.
ngram : n - это количество слов, которое мы хотим в каждом токене. Часто n = 1
Знаете ли вы, что Google оцифровал многие книги, а также создал и проанализировал литературу на основе n-граммовой модели? Отличная работа, Google!
Лемматизация: преобразование слов в его корни.Пример: экономика, микроэкономика, макроэкономисты, экономисты, экономист, экономика, экономический, экономический форум - все могут быть преобразованы обратно в его корневую экономику, что может означать, что этот текст или статья в основном посвящены экономике, финансам или экономическим вопросам. Полезно в таких ситуациях, как обозначение тем. Общие библиотеки: WordNetLemmatizer, Porter-Stemmer. Следует обратить внимание на два ключевых термина: префикс и суффикс.
Пометка предложений подобна той части речевых упражнений, которую учитель грамматики заставлял вас выполнять в старшей школе.Вот иллюстрация этого:
Чтобы получать уведомления, зарегистрируйтесь здесь: [email protected]
- Основы поиска информации: Частота термина, обратная Частота документа TFIDF
Бесстыдная самоподключаемая ниже вилка, пожалуйста, поддержите нас :)
Нравится то, что вы прочитали? Присоединяйтесь к нашему членству за 5 долларов в месяц, чтобы получить подробную информацию о вакансиях в Кремниевой долине, учебные курсы для начинающих, учебные курсы для технической карьеры в Кремниевой долине. [email protected]
В нашем блоге, предназначенном только для участников, есть доступный для поиска подробный анализ объявлений о вакансиях в Кремниевой долине, таких как менеджер по продукту, инженер по машинному обучению.Информация о технических собеседованиях, технических собеседованиях для выпускников буткемпов. Советы и рекомендации по прохождению телефонных собеседований. Наши обучающие программы стремятся быть быстрыми и удобными для новичков. Ознакомьтесь с нашей статьей на Medium и видео на Youtube о Softmax - функции, часто используемой в глубоком обучении, искусственном интеллекте и машинном обучении.
Ранее был наиболее популярным с категориальным кодированием данных.
Выходным измерением одного горячего кодировщика является номер строки - количество выборок данных, номер столбца - количество уникальных значений.При обработке естественного языка (NLP) пакетом слов может быть количество уникальных слов, часто называемых словарным запасом.
Одно горячее кодирование предполагает, что каждая метка независима друг от друга. Например, образец не может быть одновременно кошкой и собакой. Знакомый пример - монета - это либо голова, либо хвост (ни в одном мире квантовых вычислений). Это должна быть кошка или собака. Перекрытия категорий нет. Это приводит к разреженной матрице, каждая строка должна иметь все записи как 0, за исключением одной соответствующей правильной метки столбца как 1.Например, если cat - это нулевая позиция [1,0,0, 0… ..], существует столько нулей, сколько уникальных значений для кодирования. В примере с кошкой, собакой, птицей, лошадью кодировка для кошки - [1,0,0,0], для собаки - [0,1,0,0]. Скалярное произведение двух строк с разными этикетками всегда будет равно нулю. Скалярное произведение двух строк одной и той же метки всегда будет 1.
«одно горячее кодирование в каждой строке должно иметь только 1 метку, а остальные - 0»
Кодирование данных с использованием одного горячего кодирования может превратить исходный один столбец во множество новых столбцов, поэтому может занимать пространство, время, стоимость и увеличивать пространство поиска, время вычислений, требуя большего количества обучающих данных.
См. Блог только для платных подписчиков, где описано One Hot Encoding в Pandas, и пример CountVectorizer, который является связанной концепцией обработки естественного языка (NLP). Ссылка здесь. Обратите внимание, что вы должны принять приглашение блоггера, чтобы получить доступ к частному блогу.
См. Раздел встраивания, чтобы понять, насколько большой может стать одна матрица горячего кодирования.
В настоящее время наиболее популярно категориальное кодирование данных, особенно в области обработки естественного языка (NLP).
Встраивание слов: «слова или фразы из словаря отображаются в векторы действительных чисел» (википедия), например [23, 55, 72]
«Методы создания этого сопоставления включают нейронные сети, уменьшение размерности слова матрица совместной встречаемости, вероятностные модели, метод объяснимой базы знаний [6] и явное представление в терминах контекста, в котором появляются слова.
Чтобы понять, как встраивание слов экономит место, особенно когда словарь НЛП большой, подумайте об одном сценарии горячего кодирования, приведенном выше, каждая строка имеет все нули, кроме одной записи столбца, что приводит к большим разреженным матрицам.
Представьте, что у нас есть словарь из 3 единиц [«Рыжий кот», «Русский голубой кот», «Черный кот»]. Представить в одном горячем кодировании
[[1, 0,0],
[0,1,0],
[0,0,1]]
Затем представить это, используя встраивание слов [1], [ 2], [3] на самом деле каждый векторный элемент при встраивании слов может учитывать от 2 до 10, 16 или более значений в зависимости от используемой системы счисления.Например, в двоичном формате каждый слот может быть либо 0, либо 1, поэтому он составляет 2 числа. Если десятичный, каждый слот может быть числом от 0 до 9, поэтому он вмещает 10 чисел.
Если у нас есть два слота [__, __] в двоичном формате, это может составлять 2x2 = 4 чисел. Если в десятичной системе счисления, это может составлять 10x10 = 100 чисел !!
Напротив, одна матрица с горячим кодированием всегда имеет столько столбцов, сколько размер словаря. Каждый уникальный токен занимает одну колонку.Строк столько, сколько образцов данных. Большинство элементов будут нулевыми.
- Анализ тональности твитов, обзоров Amazon. Определение того, является ли короткий текст положительным или отрицательным.
- Анализ стиля письма: выбор любимой лексики авторов, стиль лирики певцов. Например, анализ стиля идентифицировал Дж. К. Роулинг как автора книги, несмотря на то, что она использовала мужской псевдоним после того, как увлеченные читатели проанализировали и обнаружили параллели и сходство в стилях текста.
- Теги сущностей: поиск организаций или имен людей в статьях
- Резюме текста: резюмируйте основные моменты новостных статей
Для анализа текстов можно использовать библиотеку Python nltk . Это популярная и мощная библиотека. Он включает списки стоп-слов на нескольких языках.
из nltk.corpus import stopwords
clean_tokens = [токен для токена в токенах, если токен не в stop_words] #important шаблон для итеративного удаления стоп-слов # source: Towards Data Science Emma Grimaldi Как машины понимают наш язык
Sklearn удобно имеет сборку -в текстовом наборе данных, с которым можно поэкспериментировать! Эти новостные статьи можно разделить на разные темы.Sklearn предоставляет очищенные данные обучения для этой задачи классификации.
Ссылка здесь
- SOS начало предложения
- EOS конец предложения
- заполнение обычно 0
- word2index
- index2word
- word2count
- текстовое облако библиотеки Python Дополнительная литература
- ссылка на документацию Sklearn для полезной функции CountVectorizer для вычисления частоты термина Grimaldi How Machines понимает наш язык: введение в обработку естественного языка
- Книга - Обработка естественного языка с помощью PyTorch: создание интеллектуальных языковых приложений с использованием глубокого обучения
- Модель Word, буквенная модель
- Использование NLP для выявления спойлеров и удаления спойлеров.Учебник по моделям нейронных сетей для обработки естественного языка - официальный документ по НЛП, автор: Я. Голдберг
- Учебник глубокого обучения Иана Гудфеллоу
- Удивительный учебник HTML по НЛП, Стэнфорд
Руководство для начинающих по обработке естественного языка - IBM Developer
В 1954 году IBM продемонстрировала способность переводить русские предложения на английский с помощью машинного перевода на мэйнфрейме IBM 701. Несмотря на простоту по сегодняшним меркам, демонстрация выявила огромные преимущества языкового перевода.В этой статье мы рассмотрим обработку естественного языка (НЛП) и то, как она может помочь нам более естественно общаться с компьютером.
NLP - одна из важнейших областей машинного обучения по разным причинам. Естественный язык - это наиболее естественный интерфейс между пользователем и машиной. В идеальном случае это включает в себя распознавание речи и генерацию голоса. Даже Алан Тьюринг признал это в своей статье «Интеллект», в которой он определил «тест Тьюринга» как способ проверить способность машины проявлять разумное поведение посредством разговора на естественном языке.
НЛП - это не отдельная сущность, а целый спектр областей исследований. На рисунке 1 показан голосовой помощник, который сегодня является обычным продуктом НЛП. Области изучения НЛП показаны в контексте основных блоков приложения голосового помощника.
Помимо технологии голосового помощника, одним из ключевых преимуществ НЛП является огромное количество неструктурированных текстовых данных, которые существуют в мире и действуют как движущая сила для обработки и понимания естественного языка. Чтобы машина могла обрабатывать, организовывать и понимать этот текст (который был создан в первую очередь для потребления человеком), мы могли бы разблокировать большое количество полезных приложений для будущих приложений машинного обучения и огромный объем знаний, которые можно было бы применить на практике.Википедия, как один из примеров, включает в себя большой объем знаний, которые связаны разными способами, чтобы проиллюстрировать взаимосвязь тем. Сама Википедия была бы бесценным источником неструктурированных данных, к которым можно было бы применить НЛП.
Давайте теперь исследуем историю и методы НЛП.
История
НЛП, как и ИИ, имеет историю взлетов и падений. Ранняя работа IBM в 1954 году для демонстрации в Джорджтауне подчеркивала огромные преимущества машинного перевода (перевод более 60 русских предложений на английский).Этот ранний подход использовал шесть грамматических правил для словаря из 250 слов и привел к крупным инвестициям в машинный перевод, но подходы, основанные на правилах, не могли масштабироваться в производственные системы.
SHRDLUMIT (названный на основе частотного порядка букв в английском языке) был разработан в конце 1960-х в LISP и использовал естественный язык, чтобы позволить пользователю манипулировать и запрашивать состояние мира блоков. Мир блоков, виртуальный мир, заполненный различными блоками, может управляться пользователем с помощью таких команд, как «Поднять большой красный блок.«Объекты можно складывать друг в друга и запрашивать, чтобы понять состояние мира (« есть ли что-нибудь справа от красной пирамиды? »). В то время эта демонстрация считалась очень успешной, но не могла масштабироваться для более сложных и неоднозначных сред.
В 1970-х и начале 1980-х годов было разработано множество приложений в стиле чат-ботов, которые могли общаться на ограниченные темы. Это были предшественники того, что сейчас называется разговорным ИИ, широко и успешно применяемого во многих областях.В других приложениях, таких как Plot Units Ленерта, реализовано повествовательное обобщение. Это позволяло резюмировать простой рассказ с помощью «сюжетных единиц», таких как мотивация, успех, смешанное благословение и другие составляющие повествования.
В конце 1980-х гг. Исследования систем НЛП перешли от основанных на правилах подходов к статистическим моделям. С появлением Интернета НЛП стало еще более важным, поскольку поток текстовой информации стал доступным для машин.
Ранние работы в NLP
В 1960-х годах началась работа по применению значения к последовательностям слов.В процессе, называемом тегированием, предложения можно разбить на части речи, чтобы понять их взаимосвязь в предложении. Эти тегеры полагались на созданные человеком алгоритмы, основанные на правилах, для «тегирования» слов с их контекстом в предложении (например, существительное, глагол, прилагательное и т. Д.). Но в этой разметке была значительная сложность, так как в английском языке может быть до 150 различных типов речевых меток.
Используя Python's Natural Language Toolkit (NLTK), вы можете увидеть результат тегирования частей речи.В этом примере последний набор кортежей представляет токенизированные слова вместе с их тегами (с использованием набора тегов UPenn). Этот набор тегов состоит из 36 тегов, таких как VBG (глагол, герундий или причастие настоящего), NN (существительное в единственном числе), PRP (личное местоимение) и т. Д.
>>> quote = "Познание себя - начало всякой мудрости."
>>> tokens = nltk.word_tokenize (цитата)
>>> tags = nltk.pos_tag (токены)
>>> теги
[('Знание', 'VBG'), ('себя', 'PRP'), ('есть', 'VBZ'),
('the', 'DT'), ('начало', 'NN'), ('из', 'IN'), ('все', 'DT'),
('мудрость', 'NN'), ('.','. ')]
>>>
Показать ещеПоказать еще значокПометка слов может показаться несложной, но поскольку слова могут означать разные вещи в зависимости от того, где они используются, процесс может быть сложным. Маркировка частей речи используется как предпосылка для решения других задач и применяется к множеству задач НЛП.
Строгие подходы к маркировке, основанные на правилах, уступили место статистическим методам, где существует неоднозначность. Имея основную часть текста (или корпус), можно вычислить вероятность слова, следующего за другим словом.В одних случаях вероятности довольно высоки, в других - равны нулю. Огромный график слов и вероятностей их переходов - это результат обучения машины тому, чтобы определять, какие слова с большей вероятностью будут следовать за другими, и могут использоваться по-разному. Например, в приложении для распознавания речи этот граф слов может использоваться для идентификации слова, искаженного шумом (на основе вероятностей последовательности слов, которая ему предшествовала). Это также можно использовать в приложении с автокоррекцией (чтобы порекомендовать слово для слова с ошибкой).Этот метод обычно решается с помощью скрытой марковской модели (HMM).
HMM полезен тем, что человеку не нужно строить этот график; машина может построить его из корпуса действительного текста. Кроме того, он может быть построен на основе кортежей слов (вероятность того, что слово следует за другим словом, называемым биграммой) или на основе n-граммы (где n = 3, вероятность того, что слово следует за двумя другими словами в последовательности). HMM применяются не только в НЛП, но и во множестве других областей (таких как секвенирование белков или ДНК).
Следующий пример иллюстрирует построение биграмм из простого предложения в NLTK:
>>> предложение = "человек, которого мы видели, видел пилу"
>>> tokens = nltk.word_tokenize (предложение)
>>> список (nltk.bigrams (токены))
[('тот', 'человек'), ('человек', 'мы'), ('мы', 'видел'), ('видел', 'видел'),
('пила', 'а'), ('а', 'пила')]
>>>
Показать ещеПоказать еще значокДавайте рассмотрим некоторые современные подходы к задачам НЛП.
Современные подходы
Современные подходы к NLP в первую очередь сосредоточены на архитектурах нейронных сетей.Поскольку архитектуры нейронных сетей полагаются на числовую обработку, для обработки слов требуется кодирование. Два общих метода - это горячие кодировки и векторы слов.
Кодировки слов
Быстрое кодирование переводит слова в уникальные векторы, которые затем могут быть численно обработаны нейронной сетью. Рассмотрим слова из нашего последнего примера с биграммой. Мы создаем наш горячий вектор размерности количества слов для представления и назначаем один бит в этом векторе для представления каждого слова.Это создает уникальное отображение, которое можно использовать в качестве входных данных для нейронной сети (каждый бит вектора в качестве входных данных для нейрона) (см. Рисунок 2). Такое кодирование выгодно для простого кодирования слов в виде чисел (кодирование меток), поскольку сети могут более эффективно обучаться с одним горячими векторами.
Другая кодировка - это векторы слов, которые представляют слова как векторы большой размерности, где единицы вектора являются действительными значениями. Но вместо того, чтобы присваивать каждой единице слово (как в one-hot), каждая единица представляет категории для слова (например, единственное число vs.множественное число или существительное против глагола) и может иметь ширину от 100 до 1000 единиц (размерность). Что делает эту кодировку интересной, так это то, что слова теперь численно связаны, и кодирование открывает применение математических операций к векторам слов (например, сложение, вычитание или отрицание).
Рекуррентные нейронные сети
Разработанные в 1980-х годах рекуррентные нейронные сети (RNN) заняли уникальное место в NLP. Как следует из названия, RNN - по сравнению с типичными нейронными сетями с прямой связью - работают во временной области.RNN разворачиваются во времени и работают поэтапно, где предыдущие выходы питают входы последующих этапов (см. Рисунок 3 для примера развернутой сети). Этот тип архитектуры хорошо применим к NLP, поскольку сеть учитывает не только слова (или их кодировки), но и контекст, в котором эти слова появляются (то, что следует, то, что было раньше). В этом примере надуманной сети входные нейроны снабжаются кодировками слов, а выходы передаются через сеть к выходным узлам (с целью кодирования выходного слова для языкового перевода).На практике каждое слово кодируется по одному и распространяется. На следующем временном шаге выполняется кодировка следующего слова (при этом вывод происходит только после подачи последнего слова).
Традиционные RNN обучаются с помощью варианта обратного распространения, называемого обратным распространением во времени (BPTT). Популярной разновидностью RNN являются блоки долгосрочной краткосрочной памяти (LSTM), которые имеют уникальную архитектуру и способность забывать информацию.
Обучение с подкреплением
Обучение с подкреплением фокусируется на выборе действий в среде для максимизации некоторой совокупной награды (вознаграждение, которое не сразу понимается, но усваивается за многие действия).Действия выбираются на основе политики, которая определяет, должно ли данное действие исследовать новые состояния (неизвестная территория, на которой может происходить обучение) или старые состояния (на основе прошлого опыта).
В контексте НЛП и машинного перевода наблюдения - это последовательности слов, которые представлены. Состояние представляет собой частичный перевод, а действие - определение того, может ли быть предоставлен перевод или требуется дополнительная информация (дополнительные наблюдения или слова). По мере предоставления дополнительных наблюдений государство может определить, что имеется достаточная информация и представлен перевод.Ключом к этому подходу является то, что перевод выполняется поэтапно с обучением с подкреплением, определяющим, когда выполнять перевод, а когда ждать дополнительной информации (полезно для языков, где основной глагол стоит в конце предложения).
Обучение с подкреплением также применялось в качестве алгоритма обучения для RNN, которые реализуют текстовое реферирование.
Глубокое обучение
Глубокое обучение / глубокие нейронные сети успешно применяются для решения множества задач.Вы найдете глубокое обучение в основе систем вопросов и ответов, обобщения документов, создания подписей к изображениям, классификации и моделирования текста и многого другого. Обратите внимание, что эти случаи представляют понимание естественного языка и генерацию естественного языка.
Глубокое обучение относится к нейронным сетям со многими уровнями (глубинная часть), которые принимают функции в качестве входных данных и извлекают из этих данных функции более высокого уровня. Сети глубокого обучения могут изучать иерархию представлений и различные уровни абстракции своих входных данных.Сети глубокого обучения могут использовать обучение с учителем или обучение без учителя и могут быть сформированы как гибриды других подходов (например, объединение повторяющейся нейронной сети с сетью глубокого обучения).
Наиболее распространенным подходом к сетям глубокого обучения является сверточная нейронная сеть (CNN), которая преимущественно используется в приложениях для обработки изображений (например, для классификации содержимого изображения). На рисунке 5 показана простая CNN для анализа настроений. Он состоит из входного слоя кодировок слов (из токенизированных входных данных), который затем питает сверточные слои.Сверточные слои сегментируют входные данные на множество «окон» входных данных для создания карт функций. Эти карты функций объединены с операцией max, которая уменьшает размерность вывода и обеспечивает окончательное представление ввода. Это передается в окончательную нейронную сеть, которая обеспечивает классификацию (например, положительная, нейтральная, отрицательная).
Хотя CNN доказали свою эффективность в области изображений и языка, можно использовать и другие типы сетей. Долговременная кратковременная память - это новый вид РНС.Клетки LSTM более сложны, чем типичные нейроны, поскольку они включают состояние и ряд внутренних вентилей, которые можно использовать для приема входных, выходных данных или забывания информации о внутреннем состоянии. LSTM обычно используются в приложениях на естественном языке. Одно из наиболее интересных применений LSTM было согласовано с CNN, где CNN предоставляла возможность обрабатывать изображение, а LSTM была обучена генерировать текстовое предложение содержимого входного изображения.
Идем дальше
Важность НЛП демонстрируется постоянно растущим списком приложений, которые его используют.НЛП обеспечивает наиболее естественный интерфейс для компьютеров и множества неструктурированных данных, доступных в Интернете. В 2011 году IBM продемонстрировала Watson ™, который соревновался с двумя величайшими чемпионами Jeopardy и победил их, используя интерфейс на естественном языке. Watson также использовал версию Википедии 2011 года в качестве источника знаний - важную веху на пути к обработке и пониманию языка и показатель того, что нас ждет впереди. Вы также можете перейти сюда, чтобы узнать больше о НЛП.
Если вы готовы начать изучать и использовать обработку естественного языка, см. Серию статей «Начало работы с обработкой естественного языка».Или взгляните на статью «Начать работу с ИИ», чтобы начать свой путь к ИИ.
Обработка естественного языка (NLP) с Python - Учебное пособие | by Towards AI Team
Компьютеры и машины отлично подходят для работы с табличными данными или электронными таблицами. Однако люди обычно общаются словами и предложениями, а не в виде таблиц. Большая часть информации, которую люди говорят или пишут, неструктурирована. Таким образом, компьютерам не очень понятно, как это интерпретировать. В обработке естественного языка (НЛП) цель состоит в том, чтобы заставить компьютеры понимать неструктурированный текст и извлекать из него значимые фрагменты информации.Обработка естественного языка (NLP) - это подполе искусственного интеллекта , глубина которого включает взаимодействие между компьютерами и людьми.
- Машинный перевод.
- Распознавание речи.
- Анализ настроений .
- Вопрос-ответ.
- Обобщение текста.
- Чат-бот.
- Интеллектуальные системы.
- Текстовые классификации.
- Распознавание символов.
- Проверка орфографии.
- Обнаружение спама.
- Автозаполнение.
- Распознавание именованных сущностей.
- Интеллектуальный ввод.
Мы, люди, довольно хорошо выполняем обработку естественного языка (НЛП), но даже в этом случае мы не идеальны. Мы часто неправильно понимаем одно за другое и часто интерпретируем одни и те же предложения или слова по-разному.
Например, рассмотрим следующее предложение, мы попытаемся понять его интерпретацию по-разному:
Пример 1:
Рисунок 2: Пример предложения НЛП с текстом: «Я видел человека на холме с телескоп.Вот некоторые интерпретации приведенного выше предложения.
- На холме сидит человек, и я наблюдал за ним в свой телескоп.
- На холме сидит человек с телескопом.
- Я на холме и увидел человека в телескоп.
- Я на холме и увидел человека с телескопом.
- На холме сидит человек, и я что-то видел в его телескоп.
Пример 2:
Рисунок 3: Пример предложения НЛП с текстом: «Можете ли вы помочь мне с банкой?»В предложении выше мы видим, что есть два слова «может», но оба имеют разные значения.Здесь первое слово «может» используется для формирования вопроса. Второе слово «банка» в конце предложения используется для обозначения емкости, в которой хранится еда или жидкость.
Следовательно, из приведенных выше примеров мы можем видеть, что языковая обработка не является «детерминированной» (один и тот же язык имеет одинаковые интерпретации), и что-то подходящее для одного человека может не подходить для другого. Следовательно, обработка естественного языка (NLP) имеет недетерминированный подход. Другими словами, обработка естественного языка может использоваться для создания новой интеллектуальной системы, которая может понять, как люди понимают и интерпретируют язык в различных ситуациях.
📚 Ознакомьтесь с нашим руководством по дистрибутиву Бернулли с примерами кода на Python. 📚
Обработка естественного языка разделена на два разных подхода:
Обработка естественного языка на основе правил:Для задач обработки используется здравый смысл. Например, низкая температура может привести к смерти, или горячий кофе может обжечь кожу человека, наряду с другими задачами, связанными с здравым смыслом. Однако этот процесс может занять много времени и требует ручных усилий.
Статистическая обработка естественного языка:Он использует большие объемы данных и пытается сделать из них выводы. Статистическое НЛП использует алгоритмы машинного обучения для обучения моделей НЛП. После успешного обучения на больших объемах данных обученная модель будет иметь положительные результаты с дедукцией.
Сравнение:
Рисунок 4: НЛП на основе правил и статистическое НЛП. Рисунок 5: Компоненты обработки естественного языка (НЛП). а. Лексический анализ:С помощью лексического анализа мы разделяем весь текст на абзацы, предложения и слова.Он включает в себя определение и анализ структуры слов.
б. Синтаксический анализ:Синтаксический анализ включает анализ слов в предложении на предмет грамматики и упорядочение слов таким образом, чтобы показать взаимосвязь между словами. Например, предложение «Магазин идет в дом» не проходит.
с. Семантический анализ:Семантический анализ определяет точное значение слов и анализирует значимость текста.Такие приговоры, как «горячее мороженое», не проходят.
г. Раскрытие интеграции:Раскрытие интеграции учитывает контекст текста. Он учитывает значение предложения до того, как оно закончится. Например: «Он работает в Google». В этом предложении слово «он» должно быть упомянуто в предложении перед ним.
e. Прагматический анализ:Прагматический анализ имеет дело с общим общением и интерпретацией языка. Он имеет дело с осмысленным использованием языка в различных ситуациях.
📚 Ознакомьтесь с обзором алгоритмов машинного обучения для начинающих с примерами кода на Python. 📚
- Разбиение предложений на токены.
- Добавление тегов к частям речи (POS).
- Создание подходящего словарного запаса.
- Связывание компонентов созданного словаря.
- Понимание контекста.
- Извлечение семантического значения.
- Распознавание именованных сущностей (NER).
- Преобразование неструктурированных данных в структурированные.
- Двусмысленность речи.
Фреймворк NLTK Python обычно используется в качестве образовательного и исследовательского инструмента. Обычно он не используется в производственных приложениях. Однако его можно использовать для создания интересных программ из-за простоты использования.
Функции:
- Токенизация.
- Тегирование части речи (POS).
- Распознавание именованных сущностей (NER).
- Классификация.
- Анализ тональности .
- Пакеты чат-ботов.
Сценарии использования:
- Системы рекомендаций.
- Анализ настроений.
- Создание чат-ботов.
spaCy - это библиотека Python с открытым исходным кодом для обработки естественного языка, разработанная для быстрой и готовой к работе. spaCy специализируется на предоставлении программного обеспечения для производственного использования.
Функции:
- Токенизация.
- Тегирование части речи (POS).
- Распознавание именованных сущностей (NER).
- Классификация.
- Анализ тональности .
- Анализ зависимостей.
- Словесные векторы.
Сценарии использования:
- Автозаполнение и автокоррекция.
- Анализируем обзоры.
- Обобщение.
Gensim - это фреймворк NLP Python, обычно используемый для тематического моделирования и обнаружения сходства. Это не универсальная библиотека НЛП, но она очень хорошо справляется с поставленными перед ней задачами.
Характеристики:
- Скрытый семантический анализ.
- Факторизация неотрицательной матрицы.
- TF-IDF.
Примеры использования:
- Преобразование документов в векторы.
- Обнаружение сходства текста.
- Обобщение текста.
Pattern - это фреймворк NLP Python с простым синтаксисом. Это мощный инструмент для решения научных и ненаучных задач.Это очень ценно для студентов.
Функции:
- Токенизация.
- Часть тегов речи.
- Признание именной организации.
- Разбор.
- Анализ настроений.
Сценарии использования:
- Исправление орфографии.
- Поисковая оптимизация.
- Анализ настроений.
TextBlob - это библиотека Python, предназначенная для обработки текстовых данных.
Функции:
- Тегирование части речи.
- Извлечение именных фраз.
- Анализ настроений.
- Классификация.
- Языковой перевод.
- Разбор.
- Интеграция Wordnet.
Сценарии использования:
- Анализ тональности.
- Исправление орфографии.
- Перевод и определение языка.
В этом руководстве мы сосредоточимся больше на библиотеке NLTK. Давайте углубимся в обработку естественного языка, приведя несколько примеров.
а. Откройте текстовый файл для обработки:Сначала мы собираемся открыть и прочитать файл, который мы хотим проанализировать.
Рисунок 11: Небольшой фрагмент кода для открытия и чтения текстового файла и его анализа. Рисунок 12: Текстовый строковый файл.Затем обратите внимание, что тип данных читаемого текстового файла - String . Количество символов в нашем текстовом файле - 675 .
б. Импортируйте необходимые библиотеки:Для различных случаев обработки данных в NLP нам необходимо импортировать некоторые библиотеки. В этом случае мы собираемся использовать NLTK для обработки естественного языка. Мы будем использовать его для выполнения различных операций с текстом.
Рисунок 13: Импорт необходимых библиотек. г. Разметка предложений: Разметка текста с помощью функции sent_tokenize () позволяет получить текст в виде предложений.
В приведенном выше примере мы видим, что весь текст наших данных представлен в виде предложений, а также замечаем, что общее количество предложений здесь составляет 9 .
г. Разметка слов: Разметка текста с помощью функции word_tokenize () позволяет получить текст в виде слов.
Затем мы видим, что весь текст наших данных представлен в виде слов, а также замечаем, что общее количество слов здесь составляет 144 .
e. Найдите частотное распределение:Давайте выясним, как часто встречаются слова в нашем тексте.
Рисунок 18: Использование FreqDist () для определения частоты встречаемости слов в нашем примере текста. Рисунок 19: Печать десяти наиболее распространенных слов из образца текста.Обратите внимание, что наиболее часто используемые слова - это знаки препинания и стоп-слова. Нам придется удалить такие слова, чтобы проанализировать реальный текст.
ф. Постройте график частот:Давайте построим график, чтобы визуализировать распределение слов в нашем тексте.
Рисунок 20. Построение графика для визуализации распределения текста.Обратите внимание на точку "." На графике выше. используется в нашем тексте девять раз. С аналитической точки зрения, знаки препинания не так важны для обработки естественного языка. Поэтому на следующем шаге мы удалим такие знаки препинания.
г. Удаление знаков препинания: Далее мы собираемся удалить знаки препинания, поскольку они не очень полезны для нас. Мы собираемся использовать метод isalpha () , чтобы отделить знаки препинания от фактического текста.Кроме того, мы собираемся создать новый список под названием words_no_punc , который будет хранить слова в нижнем регистре, но исключать знаки препинания.
Как показано выше, все знаки препинания из нашего текста исключены. Они также могут сверяться с количеством слов.
ч.Построение графика без знаков препинания: Рисунок 23: Печать десяти наиболее употребительных слов из образца текста. Рисунок 24: Построение графика без знаков препинания.Обратите внимание, что у нас все еще есть много слов, которые не очень полезны при анализе нашего образца текстового файла, таких как «и», «но», «так» и другие. Далее нам нужно удалить координирующие союзы.
i. Список игнорируемых слов: Рисунок 25: Импорт списка стоп-слов. Рисунок 26: Пример данных текста. Дж. Удаление игнорируемых слов: Рисунок 27: Очистка данных образца текста. Рисунок 28: Очищенные данные. к. Окончательное частотное распределение: Рисунок 29: Отображение окончательного частотного распределения наиболее часто встречающихся слов. Рисунок 30: Визуализация наиболее распространенных слов, найденных в группе.Как показано выше, окончательный график содержит много полезных слов, которые помогают нам понять, о чем наши образцы данных, показывая, насколько важно выполнять очистку данных в NLP.
Далее мы рассмотрим различные темы НЛП с примерами кодирования.
Облако слов - это метод визуализации данных. Какие слова из заданного текста отображаются на основной диаграмме. В этом методе более частые или важные слова отображаются более крупным и жирным шрифтом, а менее частые или важные слова отображаются меньшим или более тонким шрифтом. Это полезный метод в НЛП, который дает нам представление о том, какой текст следует анализировать.
Свойства:
- font_path : указывает путь для шрифтов, которые мы хотим использовать.
- ширина : определяет ширину холста.
- высота : определяет высоту холста.
- min_font_size : определяет наименьший размер шрифта для использования.
- max_font_size: Определяет наибольший размер шрифта для использования.
- font_step : определяет размер шага для шрифта.
- max_words : определяет максимальное количество слов в облаке слов.
- стоп-слов : Наша программа удалит эти слова.
- background_color: Определяет цвет фона для холста.
- normalize_plurals : Удаляет завершающие «s» из слов.
Прочтите полную документацию по WordCloud .
Облако слов Реализация Python:
Рисунок 31: Реализация облака слов в коде Python Рисунок 32: Пример облака слов.Как показано на графике выше, наиболее часто используемые слова отображаются более крупным шрифтом.Облако слов может отображаться в любой форме или изображении.
Например: в этом случае мы собираемся использовать следующее изображение круга, но мы можем использовать любую форму или любое изображение.
Рис. 33: Форма изображения круга для нашего облака слов.Облако слов Реализация Python:
Рисунок 34: Реализация облака слов в коде Python Рисунок 35: Облако слов в форме круга.Как показано выше, облако слов имеет форму круга. Как мы упоминали ранее, мы можем использовать любую форму или изображение, чтобы сформировать облако слов.
Облако словПреимущества:- Они быстрые.
- Они занимаются.
- Они просты для понимания.
- Они непринужденные и визуально привлекательные.
- Они не идеальны для нечистых данных.
- У них отсутствует контекст слов.
Мы используем Stemming для нормализации слов. В английском и многих других языках одно слово может принимать разные формы в зависимости от используемого контекста.Например, глагол «изучать» может принимать разные формы, такие как «изучать», «изучать», «изучать» и другие, в зависимости от контекста. Когда мы токенизируем слова, интерпретатор рассматривает эти входные слова как разные слова, даже если их основное значение одинаково. Более того, поскольку мы знаем, что НЛП - это анализ значения контента, для решения этой проблемы мы используем стемминг.
Стебель нормализует слово путем усечения слова до его основного слова. Например, слова «изучает», «изучал», «изучает» будут сокращены до «studi», так что все эти словоформы будут относиться только к одному токену.Обратите внимание, что определение корней может не дать нам словаря, грамматического слова для определенного набора слов.
Рассмотрим пример:
a. Пример стеммера Портера 1:В приведенном ниже фрагменте кода мы показываем, что все слова усекаются до своих основных слов. Однако обратите внимание, что слово с корнем не является словарным.
Рисунок 36: Фрагмент кода, показывающий пример стемминга. г. Пример стеммера Портера 2:В приведенном ниже фрагменте кода многие слова после выделения корня не попали в узнаваемое словарное слово.
Рисунок 37: Фрагмент кода, показывающий пример стемминга. г. SnowballStemmer:SnowballStemmer генерирует тот же вывод, что и стеммер портера, но поддерживает гораздо больше языков.
Рисунок 38: Фрагмент кода, показывающий пример стемминга НЛП. г. Языки, поддерживаемые стеммингом снежного кома: Рисунок 39: Фрагмент кода, показывающий пример стемминга НЛП. а. Стеммер Портера: Рис. 40: Алгоритм НЛП Стеммера Портера, плюсы и минусы. г. Lovin’s Stemmer: Рис. 41: Алгоритм Lovin’s Stemmer НЛП, плюсы и минусы. г. Стеммер Доусона: Рис. 42: Алгоритм НЛП Стеммера Доусона, плюсы и минусы. г. Krovetz Stemmer: Рисунок 43: Алгоритм Krovetz Stemmer НЛП, плюсы и минусы. e. Xerox Stemmer: Рис. 44: Алгоритм НЛП Xerox Stemmer, плюсы и минусы. ф. Snowball Stemmer: Рисунок 45: Алгоритм НЛП Snowball Stemmer, плюсы и минусы.📚 Ознакомьтесь с нашим учебником по нейронным сетям с нуля с кодом Python и математикой в деталях.
Лемматизация пытается достичь аналогичной базовой «основы» для слова. Однако его отличает то, что он находит словарное слово, а не усекает исходное слово. Stemming не учитывает контекст слова. Поэтому он дает результаты быстрее, но менее точен, чем лемматизация.
Если точность не является конечной целью проекта, то подходящим подходом является остановка.Если более высокая точность имеет решающее значение и проект не уложился в сжатые сроки, то лучшим вариантом является амортизация (лемматизация имеет более низкую скорость обработки, чем стемминг).
Лемматизация учитывает значения части речи (POS). Кроме того, лемматизация может генерировать разные выходные данные для разных значений POS. Обычно у нас есть четыре варианта для POS:
Рисунок 46: Значения части речи (POS) в лемматизации.Разница между Stemmer и Lemmatizer:
a.Stemming:
Обратите внимание на то, как при создании слов слово «study» обрезается до «studi».
Рисунок 47: Использование стемминга с фреймворком NLTK Python.г. Лемматизация:
Во время лемматизации слово «изучает» отображает словарное слово «изучать».
Рисунок 48: Использование лемматизации с фреймворком NLTK Python.Реализация Python:
a. Базовый пример, демонстрирующий, как работает лемматизатор
В следующем примере мы принимаем тег PoS как «глагол», и когда мы применяем правила лемматизации, он дает нам словарные слова вместо усечения исходного слова:
Рисунок 49 : Простой пример лемматизации с фреймворком NLTK.г. Лемматизатор со значением PoS по умолчанию
Значение PoS по умолчанию в лемматизации - существительное (n). В следующем примере мы видим, что он генерирует слова из словаря:
Рисунок 50: Использование лемматизации для генерации значений по умолчанию.г. Другой пример, демонстрирующий силу лемматизатора.
Рис. 51: Лемматизация слов: «am», «are», «is», «was», «were»d. Лемматизатор с разными значениями POS
Рисунок 52: Лемматизация с разными значениями части речи.Зачем нам нужна часть речи (POS)?
Рисунок 53: Пример предложения: «Вы можете мне помочь с банкой?»Маркировка частей речи (PoS) имеет решающее значение для синтаксического и семантического анализа. Следовательно, для чего-то подобного приведенному выше предложению слово «может» имеет несколько семантических значений. Первая «банка» используется для формирования вопроса. Вторая «банка» в конце предложения используется для обозначения контейнера. Первое «может» - это глагол, а второе «может» - существительное. Придание слову конкретное значение позволяет программе правильно обрабатывать его как в семантическом, так и в синтаксическом анализе.
Ниже приведен список тегов части речи (PoS) с соответствующими примерами:
1. CC: Координационное соединение
Рис. 54: Пример координационного соединения.2. CD: Кардинальная цифра
Рисунок 55: Пример кардинальной цифры.3. DT: Determiner
Рисунок 56: Пример определителя.4. EX: Экзистенциальное там
Рис. 57: Пример экзистенциального «там».5. FW: иностранное слово
Рисунок 58: Пример иностранного слова.6. IN: Предлог / Подчинительный союз
Рис. 59: Предлог / Подчинительный союз.7. JJ: Прилагательное
Рисунок 60: Пример прилагательного.8. JJR: Прилагательное, сравнительный
Рисунок 61: Прилагательное, сравнительный пример.9. JJS: прилагательное, превосходная степень
Рисунок 62:10. LS: маркер списка
Рисунок 63: Пример маркера списка.11. MD: Modal
Рисунок 64:12.NN: Существительное, единственное число
Рисунок 65: Существительное, пример единственного числа.13. NNS: Существительное, множественное число
Рис. 66: Существительное, пример множественного числа.14. NNP: Имя собственное, единственное число
Рисунок 67: Существительное собственное, пример единственного числа.15. NNPS: Имя собственное, множественное число
Рис. 68: Существительное собственное, пример множественного числа.16. PDT: предопределитель
Рисунок 69: Пример предопределителя.17. POS: Притяжательные окончания
Рисунок 70: Пример притяжательных окончаний.18. PRP: личное местоимение
Рисунок 71: Пример личного местоимения.19. PRP $: Притяжательное местоимение
Рис. 72: Пример притяжательного местоимения.20. RB: Наречие
Рисунок 73: Пример наречия.21. RBR: Наречие, сравнительный
Рисунок 74: Наречие, сравнительный пример.22. RBS: Наречие, превосходная степень
Рисунок 75: Наречие, превосходная степень.23. RP: Частица
Рис. 76: Пример частицы.24. Кому: Кому
Рисунок 77: К примеру.25. UH: Междометия
Рис. 78: Пример междометия.26. VB: Глагол, основная форма
Рис. 79: Глагол, пример базовой формы.27. VBD: Глагол, прошедшее время
Рисунок 80: Глагол, пример прошедшего времени.28. VBG: Глагол, причастие в настоящем времени
Рисунок 81: Глагол, пример причастия в настоящем времени.29. VBN: Глагол, причастие прошедшего времени
Рисунок 82: Глагол, причастие прошедшего времени.30. VBP: Глагол, настоящее время, не третье лицо единственного числа
Рис. 83: Глагол, настоящее время, а не третье лицо единственного числа.31. VBZ: Глагол, настоящее время, третье лицо единственного числа
Рисунок 84: Глагол, настоящее время, третье лицо единственного числа.32. WDT: Wh - Determiner
Рисунок 85: Пример определителя.33. WP: Wh - Местоимение
Рисунок 86: Пример местоимения.34. WP $: Possessive Wh - Местоимение
Рисунок 87: Пример притяжательного местоимения.35. WRB: Wh - наречие
Рисунок 88: Пример наречия.Реализация Python:
a. Простой пример, демонстрирующий теги PoS.
Рисунок 89: Пример тегов PoS.г. Полный пример, демонстрирующий использование тегов PoS.
Рисунок 90: Полный пример Python, демонстрирующий теги PoS.Разделение на части означает извлечение значимых фраз из неструктурированного текста. Обозначая книгу словами, иногда трудно вывести значимую информацию.Он работает поверх тегов Part of Speech (PoS). Разделение на части принимает теги PoS в качестве входных данных и предоставляет фрагменты в качестве выходных данных. Разделение на части буквально означает группу слов, которая разбивает простой текст на фразы, которые более значимы, чем отдельные слова.
Рисунок 91: Процесс разбиения на фрагменты в НЛП.Прежде чем работать с примером, нам нужно знать, что это за фразы? Значимые группы слов называются фразами. Есть пять значимых категорий фраз.
- Фразы существительных (NP).
- Глагольные фразы (VP).
- Прилагательные фразы (ADJP).
- Наречия (ADVP).
- Предложные фразы (PP).
Правила структуры фраз:
- S (Предложение) → NP VP.
- NP → {Определитель, Существительное, Местоимение, Имя собственное}.
- ВП → В (НП) (ПП) (Наречие).
- PP → Местоимение (NP).
- AP → Прилагательное (PP).
Пример:
Рисунок 92: Пример фрагментации в НЛП. РеализацияPython:
В следующем примере мы извлечем из текста именную фразу.Перед его извлечением нам нужно определить, какую именную фразу мы ищем, или, другими словами, мы должны установить грамматику для именной фразы. В этом случае мы определяем именную фразу с помощью необязательного определителя, за которым следуют прилагательные и существительные. Затем мы можем определить другие правила для извлечения некоторых других фраз. Затем мы собираемся использовать RegexpParser () для анализа грамматики. Обратите внимание, что мы также можем визуализировать текст с помощью функции .draw () .
В этом примере мы видим, что мы успешно извлекли именную фразу из текста.
Рисунок 94: Успешное извлечение именной фразы из введенного текста. Chinking исключает часть из нашего чанка. Есть определенные ситуации, когда нам нужно исключить часть текста из всего текста или фрагмента. При сложных извлечениях возможно, что разбиение на фрагменты может привести к появлению ненужных данных. В таких сценариях мы можем использовать chinking, чтобы исключить некоторые части из этого фрагментированного текста.
В следующем примере мы собираемся взять всю строку как кусок, а затем мы собираемся исключить из него прилагательные, используя chinking.Обычно мы используем chinking, когда у нас есть много бесполезных данных даже после фрагментации. Следовательно, используя этот метод, мы можем легко выделить это, а также для написания грамматики трещин, мы должны использовать перевернутые фигурные скобки, то есть:
} написать здесь грамматику трещин {
Реализация Python:
Рисунок 95 : Исправление реализации с Python.Из приведенного выше примера мы видим, что прилагательные отделены от остального текста.
Рис. 96: В этом примере прилагательные исключаются с помощью чинки.Распознавание именованных сущностей может автоматически сканировать целые статьи и извлекать некоторые фундаментальные сущности, такие как люди, организации, места, дата, время, деньги и обсуждаемые в них GPE.
Примеры использования:- Классификация контента для новостных каналов.
- Подведение итогов.
- Оптимизация алгоритмов поисковых систем.
- Рекомендательные системы.
- Служба поддержки клиентов.
Реализация Python:
Есть два варианта:
1. binary = True
Когда двоичное значение равно True, тогда будет показано только то, названа ли конкретная сущность сущностью или нет. Никаких дополнительных подробностей он не покажет.
Рисунок 98: Реализация Python, когда двоичное значение истинно.Наш график не показывает, какой это тип именованной сущности. Он только показывает, названо ли конкретное слово сущностью или нет.
Рисунок 99: Пример графика, когда двоичное значение истинно.2. binary = False
Когда двоичное значение равно False, оно подробно показывает тип именованных объектов.
Рисунок 100: Реализация Python при двоичном значении False.Теперь наш график показывает, какой это тип именованной сущности.
Рисунок 101: График, показывающий тип именованных объектов, когда двоичное значение равно false.Wordnet - это лексическая база данных для английского языка. Wordnet является частью корпуса NLTK. Мы можем использовать Wordnet для поиска значений слов, синонимов, антонимов и многих других слов.
а. Мы можем проверить, сколько различных определений слова доступно в Wordnet. Рисунок 102: Проверка определений слов с помощью Wordnet с использованием инфраструктуры NLTK. г. Мы также можем проверить значение этих разных определений. Рисунок 103: Сбор значений различных определений с помощью Wordnet. г. Все подробности за слово. Рис. 104: Поиск всех деталей для определенного слова. г. Все подробности для всех значений слова. Рис. 105: Поиск всех подробностей для всех значений определенного слова. e. Гиперонимы: Гиперонимы дают нам более абстрактный термин для слова. Рисунок 106: Использование Wordnet для поиска гиперонима. ф. Гипонимы: Гипонимы дают нам более конкретный термин для слова. Рисунок 107: Использование Wordnet для поиска гипонима. г. Получите только имя. Рисунок 108: Поиск только имени с помощью Wordnet. ч. Синонимы. Рисунок 109: Поиск синонимов с помощью Wordnet. и. Антонимы. Рисунок 110: Поиск антонимов с помощью Wordnet. Дж. Синонимы и антонимы. Рисунок 111: Поиск синонимов и фрагментов кода антонимов с помощью Wordnet. к. Обнаружение сходства между словами. Рисунок 112: Определение коэффициента сходства между словами с помощью Wordnet. Рисунок 113: Определение коэффициента сходства между словами с помощью Wordnet. Рисунок 114: Представление набора слов.Что такое метод «мешка слов»?
Это метод извлечения важных функций из текста строки, чтобы мы могли использовать его для моделей машинного обучения.Мы называем это «Мешок» слов, потому что мы отбрасываем порядок появления слов. Модель мешка слов преобразует исходный текст в слова, а также подсчитывает частоту появления слов в тексте. Таким образом, набор слов - это набор слов, которые представляют предложение вместе с количеством слов, порядок появления которых не имеет значения.
Рисунок 115: Структура пакета слов.- Необработанный текст: Это исходный текст, на котором мы хотим провести анализ.
- Чистый текст: Поскольку наш необработанный текст содержит некоторые ненужные данные, такие как знаки препинания и стоп-слова, нам нужно очистить наш текст. Чистый текст - это текст после удаления таких слов.
- Токенизация: Токенизация представляет предложение как группу токенов или слов.
- Building Vocab: Содержит общее количество слов, использованных в тексте после удаления ненужных данных.
- Создать словарь: Он содержит слова вместе с их частотами в предложениях.
Например:
Предложения:
- Джим и Пэм ехали на автобусе.
- Поезд опоздал.
- Полет был полным. Путешествовать самолетом дорого.
а. Создание базовой структуры:
Рисунок 116: Пример базовой структуры для набора слов.г. Слова с частотами:
Рисунок 117: Пример базовой структуры для слов с частотами.г. Объединение всех слов:
Рисунок 118: Комбинация всех введенных слов.г. Окончательная модель:
Рис. 119: Последняя модель нашего мешка слов.Реализация Python:
Рисунок 120: Фрагмент кода реализации Python нашего мешка слов. Рисунок 121: Выходные данные нашего мешка слов. Рисунок 122: Выходные данные нашего мешка слов.Приложения:
- Обработка естественного языка.
- Поиск информации из документов.
- Классификации документов.
Ограничения:
- Семантическое значение : семантическое значение слова не учитывается.Он игнорирует контекст, в котором используется это слово.
- Размер вектора : для больших документов размер вектора увеличивается, что может привести к увеличению времени вычислений.
- Предварительная обработка : При предварительной обработке нам необходимо выполнить очистку данных перед их использованием.
TF-IDF означает «Частота термина - обратная частота документа» , которая является оценочной мерой, обычно используемой при поиске информации (IR) и обобщении. Оценка TF-IDF показывает, насколько важен или актуален термин в данном документе.
Интуиция, лежащая в основе TF и IDF:
Если определенное слово встречается в документе несколько раз, то оно может иметь большее значение, чем другие слова, которые встречаются реже (TF). В то же время, если определенное слово много раз встречается в документе, но также много раз присутствует в некоторых других документах, то, возможно, это слово встречается часто, поэтому мы не можем придавать ему большого значения. (IDF). Например, у нас есть база данных с тысячами описаний собак, и пользователь хочет найти «милая собака» в нашей базе данных.Задача нашей поисковой системы - отображать наиболее близкий ответ на запрос пользователя. Как это сделает поисковая машина? Поисковая система, возможно, будет использовать TF-IDF для вычисления оценки для всех наших описаний, и результат с более высокой оценкой будет отображаться в качестве ответа пользователю. Теперь это тот случай, когда нет точного соответствия запросу пользователя. Если есть точное соответствие запросу пользователя, то этот результат будет показан первым. Затем предположим, что в нашей базе данных есть четыре описания.
- Пушистый пес.
- Милый песик.
- Большая собака.
- Милый песик.
Обратите внимание, что первое описание содержит 2 из 3 слов из нашего пользовательского запроса, а второе описание содержит 1 слово из запроса. Третье описание также содержит 1 слово, а четвертое описание не содержит слов из пользовательского запроса. Поскольку мы можем почувствовать, что ближайшим ответом на наш запрос будет описание номер два, поскольку оно содержит ключевое слово « cute » из запроса пользователя, TF-IDF вычисляет значение именно так.
Обратите внимание, что значения частоты термина одинаковы для всех предложений, поскольку ни одно из слов в предложениях не повторяется в одном предложении. Таким образом, в этом случае стоимость TF не будет иметь значения. Далее мы собираемся использовать значения IDF, чтобы получить наиболее близкий ответ на запрос. Обратите внимание, что слово собака или собака может встречаться во многих документах. Следовательно, значение IDF будет очень низким. Со временем значение TF-IDF также будет ниже. Однако, если мы отметим слово «милый» в описании собак, то оно будет встречаться относительно реже, поэтому увеличивает значение TF-IDF.Таким образом, слово «милый» обладает большей силой различения, чем «собака» или «собачка». Затем наша поисковая система найдет описания, в которых есть слово «милый», и, в конце концов, это именно то, что искал пользователь.
Проще говоря, чем выше оценка TF * IDF, тем реже, уникальнее или ценнее термин, и наоборот.
Теперь рассмотрим простой пример и разберемся с TF-IDF более подробно.
Пример:
Предложение 1 : Это первый документ.
Предложение 2 : Этот документ является вторым документом.
TF: Частота термина
Рисунок 123: Вычисление частоты термина на TF-IDF.а. Изобразите слова предложений в таблице.
Рисунок 124: Табличное представление предложений.г. Отображение частоты слов.
Рисунок 125: Таблица, показывающая частоту слов.г. Расчет TF по формуле.
Рисунок 126: Расчет TF.Рисунок 127: Результирующий TF.IDF: обратная частота документа
Рисунок 128: Расчет IDF.г. Расчет значений IDF по формуле.
Рисунок 129: Расчет значений IDF по формуле.e. Расчет TF-IDF.
TF-IDF - это произведение TF * IDF.
Рисунок 130: Результирующее умножение TF-IDF.В этом случае обратите внимание, что импортируемые слова, которые различают оба предложения, являются «первым» в предложении-1 и «вторым» в предложении-2, как мы видим, эти слова имеют относительно более высокое значение, чем другие слова.
Однако существует множество вариантов сглаживания значений для больших документов. Наиболее распространенный вариант - использовать значение журнала для TF-IDF. Давайте снова вычислим значение TF-IDF, используя новое значение IDF.
Рисунок 131: Использование значения журнала для TF-IDF с использованием нового значения IDF.ф. Расчет значения IDF с использованием журнала.
Рисунок 132: Расчет значения IDF с использованием журнала.г. Расчет TF-IDF.
Рисунок 133: Расчет TF-IDF с использованием журнала.Как видно выше, «первое» и «второе» значения - важные слова, которые помогают нам различать эти два предложения.
Теперь, когда мы познакомились с основами TF-IDF. Далее мы собираемся использовать библиотеку sklearn для реализации TF-IDF в Python. Фактический результат нашей программы рассчитывается по другой формуле. Сначала мы увидим обзор наших расчетов и формул, а затем реализуем их на Python.
Фактические расчеты:
a. Частота термина (TF):
Рисунок 134: Фактический расчет TF.г. Обратная частота документа (IDF):
Рисунок 135: Формула для IDF. Рисунок 136: Применение журнала к значениям IDF.г. Расчет окончательных значений TF-IDF:
Рисунок 137: Расчет окончательных значений IDF Рисунок 138: Окончательные значения TF-IDF.Реализация Python:
Рисунок 139: Реализация Python фрагмента кода TF-IDF Рисунок 140: Окончательный результат.Это некоторые из основ захватывающей области обработки естественного языка (НЛП). Надеемся, вам понравилось читать эту статью и вы узнали что-то новое.Любые предложения или отзывы имеют решающее значение для дальнейшего улучшения. Пожалуйста, дайте нам знать в комментариях, если они у вас есть.
Руководство, руководство и алгоритмы обработки естественного языка (NLP)
Вы когда-нибудь ругали чат-бота, если он вас не понимает? Вы когда-нибудь задумывались о том, чтобы узнать причину этого?
Ну, если да, то ответ прост. Все это связано с отсутствием или отсутствием обработки естественного языка, широко известной как NLP.
Что такое Обработка естественного языка ? Почему мы это используем? Где мы его используем?
Позвольте нам объяснить вам НЛП простым языком и объяснить весь процесс в учебнике по обработке естественного языка.Информация включена во все, что мы выражаем. Это может быть написано на каком-то языке или передано кому-то устно.
Слова, тон, тема и т. Д. Представляют собой тип данных, которые можно использовать для интерпретации и извлечения из них некоторого значения. Эта информация дает нам представление о человеческом поведении, через которое мы можем понять других.
Тем не менее, это может вызвать одну проблему, из-за которой людям сложно отслеживать все и вся, т.е.е., много информации. Не запутайтесь, давайте объясним.
Один человек может составить тысячи предложений и слов объявления, включая сложность каждой фразы. В ручном режиме мы не способны управлять этими данными и анализировать их из-за миллионов деклараций.
Это неструктурированные данные, которые компании обычно собирают из деклараций, разговоров, статуса, активности в социальных сетях и т. Д. Эти данные трудно разместить в реляционной базе данных, которая представляет мир.
Это делает его рукой манипулировать и беспорядочно понимать. В результате произошла одна из самых больших революций в области обработки естественного языка.
Теперь людям не нужно прилагать усилия, чтобы понять речь или текст, представленные в данных, вручную. Когнитивные способы облегчили пользователям понимание значения данных, распознавание речи и т. Д.
Тем не менее, он во многом зависит от искусственного интеллекта , машинного обучения и глубокого обучения , которые помогают всему процессу НЛП.
Подробнее - Руководство по машинному обучению для начинающих
Это всего лишь введение в обработку естественного языка, есть гораздо больше, о чем мы должны знать. Теперь давайте разберемся с этим техническим способом в учебнике по обработке естественного языка.
Что такое обработка естественного языка ?NLP - это подкатегория искусственного интеллекта, информационной инженерии, информатики и лингвистики, которая помогает машинам понимать человеческий язык.Это помогает анализировать данные, которые люди воздерживаются от использования, но могут иметь большой потенциал.
Проще говоря, НЛП помогает понять множество данных и проанализировать их, чтобы компьютеры могли легко общаться с людьми с помощью машинного обучения НЛП, глубокого обучения и технологий искусственного интеллекта.
Позвольте вкратце рассказать вам об истории НЛП. В 1950-х годах первая теория о НЛП возникла в статье « Computing Machinery and Intelligence » Алана Тьюринга , которая демонстрирует критерий интеллекта на основе теста Тьюринга .
Однако в 1954 году автоматический перевод был выполнен как эксперимент Джорджтаун , который переводил предложения с русского на английский. С этим НЛП стало популярным, и постепенно к нему добавлялись новые исследования, в том числе статистических машинных транзакций, в 1980-х годах и так далее.
Вот краткая временная шкала обработки естественного языка, о которой нужно знать.
В настоящее время NLP развивается быстрыми темпами с увеличением вычислительной мощности и расширением доступа к данным.Это позволяет практикам достигать желаемых результатов в таких секторах, как человеческие ресурсы, финансы, СМИ, здравоохранение и т. Д.
Почему НЛП важно?Мы живем в то время, когда компании стремятся улучшить взаимодействие с пользователем на каждом этапе. Они не оставляют ни единого камня на камне, чтобы улучшить опыт клиентов, чтобы быть на шаг впереди своих конкурентов.
Бренды хорошо развиты для работы с каналами AI-помощника, вычислительной лингвистикой, получением данных с веб-сайтов или документов и т. Д.Клиенты и компании теперь используют НЛП и облачные вычисления, чтобы быть более точными, автоматизировать услуги, выполнять поиск по часто задаваемым вопросам и даже общаться с клиентами с помощью чат-бота.
Клиенты могут получать мгновенные ответы на свои запросы, в то время как компании могут сосредоточиться на более ценных данных без помощи вручную. Агентская сторона для компаний легко покрывается NLP, которые работают как виртуальные помощники (в основном), которые используют данные для эффективного взаимодействия с пользователями.
Анализ данных с помощью НЛП имеет большой потенциал для роста, который ранее был скрыт в текстовых хранилищах, которые используют алгоритмы машинного обучения НЛП для анализа.Кратко объяснив принцип работы, давайте рассмотрим плюсы и минусы НЛП в соответствии с его подходами - машинное обучение и инженерия грамматики (мы кратко поговорим о них позже в блоге).
Сказав это, давайте погрузимся в глубину мира НЛП с его работой и другими важными аспектами, о которых нужно знать.
Как работает обработка естественного языка ?Подробнее - AI-as-a-Service
Natural Processing Language или правила NLP должны быть известны машинам для работы, включая фонологию , семантику , синтаксис , морфологию и прагматику , прежде всего - двусмысленность .Но перед этим давайте разберемся, как выглядит рабочий процесс.
Стандартный рабочий процесс НЛПNLP работает над основной моделью рабочего процесса, которая представляет собой пошаговый процесс для достижения желаемого результата. Весь процесс описан на изображении ниже в виде обработки текста, предварительной обработки, синтаксического анализа и результата. Они подробно описаны ниже в разделе «Работа и методы».
С учетом сказанного, давайте начнем с его основной работы, в которой вышеуказанные условия будут прояснены более практичным образом.
# 1 Слова в предложенииПрирода слов - это первое и главное, что необходимо охватить, включая прилагательные и словосочетания. Глагол, время, форма инфинитива, число, лицо и т. Д. - все это часть PoS ( Часть речевого тегирования ), которая позже преобразуется в документе с помощью обработки естественного языка и интеллектуального анализа текста.
Например, в предложении вся необходимая информация объясняется в части речи, флексионных формах, глаголах, существительных и т. Д., Которые используются для вычисления вывода.Речь идет о простых предложениях, которые даже люди предсказывают, но как насчет предложений, которые немного сложны.
Для их решения NLP использует два основных подхода: статистический и символический . При статистическом подходе явления обучения изучаются машиной с использованием алгоритмов обработки естественного языка, благодаря которым анализ выполняется идеально. В символьном подходе есть ряд правил, которые автоматически усваиваются моделью.
Это относится к PoS Tagger на основе правил или Brill Tagger , что помогает получить правильный результат. Маркировка PoS, используемая в статистических подходах, считается проблемой маркировки последовательностей. При этом последовательность слов делится на соответствующие теги, которые затем используются для определения следующего слова.
Например, предложение «Макс планирует» уже доступно, тогда теги PoS используются для создания следующего предложения, которое будет иметь смысл.Однако они не работают сами по себе, а зависят от условных случайных полей ( CRF ) и скрытых марковских моделей ( HMM ). который обучается с использованием данных с тегами PoS.
# 2 слова к предложениюМы видели, что НЛП может легко обходить слова и понимать примеры. А как насчет синтаксиса? Где НЛП собирается его использовать? Иногда бывает сложно понять синтаксис. Слова сгруппированы вместе, но в соответствующем формате в единицах кусков.
NLP использует Parsing для анализа предложений в соответствии с грамматикой NLP. Дерево построено для понимания контекста предложения в соответствии с грамматикой. Это известно как дерево синтаксического анализатора, которое аннотирует фактическое значение НЛП.
# 3 Значение словЗначение слов иногда может сбивать с толку. Слово «раз» можно использовать в двух контекстах, которые легко понять на английском языке, но для компьютера это может сбивать с толку.
Это приводит к двум основным проблемам, с которыми сталкивается НЛП.
- Синонимия - Слова с похожими значениями
- Многозначность - Слова с несколькими значениями
Гипернимия , гипонимия и антонимия также используются различные типы семантических отношений. Композиционная семантика помогает комбинировать слова вместе для образования значения, тогда как лексическая семантика помогает придавать значение словам.
В дополнение к этому, WSD - Устранение неоднозначности слов используется в предложении для определения многозначного смысла слов.
Например,
Он сделал мир рекордом .
У нас есть запись разговора.
Синтаксис и теги PoS в приведенных выше предложениях схожи, что может затруднить понимание НЛП.В этом типе фраз используется глубокий подход, основанный на знании мира. Эти знания помогают устранить двусмысленность и придать словам правильное значение.
# 4 Прагматика Контекст предложения - это следующее, что необходимо для извлечения действительного значения. Это шутка? Саркастический комментарий? Серьезный комментарий? Эти вещи имеют большое значение, когда дело доходит до анализа данных.
Например,
Уилл - Это был глупый ход.
Джеймс - Что ж, спасибо, это так мило с вашей стороны.
Почему тупой относится к сладкому? Что это было - сарказм, шутка или ирония? Они подпадают под сложный механизм НЛП, который работает с намерением слов. Классификатор можно обучить определять, о чем идет речь в твите или статусе.
Он может включать частоту слов или даже добавленные прилагательные, такие как преувеличение или неожиданность. Тем не менее, всегда есть возможности для улучшения, и со временем система НЛП также может принять намерения.
# 5 Синтаксис и структураКогда дело доходит до языков программирования, вам необходимо знать, что синтаксис и структурирование всегда идут рука об руку. В НЛП это включает соглашения, правила, принципы слов, фраз, предложений и так далее.
Их можно использовать разными способами, включая анализ , аннотацию и обработку текста . Однако, чтобы понять это, вам нужно знать, что он имеет большое значение для основного синтаксиса текста или большей части грамматики в НЛП.
- POS (части речи) Tagging - POS - это категория слов, которая демонстрирует ее роль и помогает НЛП в работе. Он включает в себя такие категории, как существительных , глаголов , прилагательных и наречий .
- Анализ избирательного округа - В этом случае грамматика используется для проверки предложения и анализа его в иерархическом порядке.
- Chunking or Shallow Parsing - здесь фразы используются для обозначения смысла.Он разделен на пять основных категорий, таких как глагольная фраза (VP) , существительная фраза (NP) , наречие (ADVP) , прилагательная фраза (ADJP) и предложная фраза (PP) ( как указано выше в таблице синтаксического анализа).
- Анализ зависимостей - В этом предложении анализируется грамматическая зависимость, чтобы понять взаимосвязь между токенами.
Однако остались набор инструментов для обработки естественного языка и библиотеки , которые также являются основной частью языка программирования NLP.НЛП работает с различными библиотеками обработки, такими как:
Из этих библиотек NLTK - самая известная, широко используемая разработчиками. NLTK написан на Python, который предлагает отличную поддержку своему сообществу, а также является простым языком, который легко выучить.
Это основные части, которые добавляются системой для анализа данных. Требуется обработка сегментированного текста на слова, которая обрабатывается в виде токенизации .Затем есть вопросы и ответы, которые выполняют семантический, синтаксический и морфологический анализ.
Каковы основные методы обработки естественного языка (НЛП)?Несмотря на то, что в нашем распоряжении так много информации, есть разработчики, не занимающиеся НЛП, которые мало о ней осведомлены. В противном случае было бы чрезвычайно трудно управлять всем процессом манипулирования и понимания сложных данных.
R и Python-подобные языки программирования NLP используются для написания строк кода, но позвольте нам кратко изложить вам весь словарь NLP, прежде чем погрузиться в него.Итак, давайте погрузимся в методы обработки естественного языка (НЛП), чтобы лучше понять всю концепцию, или, можно сказать, учебник по обработке естественного языка для начинающих.
# 1 Наборы словМы уже упоминали тип грамматики и ее работу выше, так что будет легко охватить мешки слов, которые работают как слова в части предложения или текста. Матрица вхождений создается для документа и предложения, которые затем помещают слово или грамматику в правильном порядке.
Встречи и частоты затем компилируются вместе в форме классификатора, который обучен для анализа. Однако у каждого аспекта есть свои плюсы и минусы, включая отсутствие семантического контекста и смысла использования техник НЛП в ИИ.
А как насчет стоп-слов (а и)? Анализ шума? Для работы над этими общими проблемами используется (TFIDF ) - Term Frequency - Inverse Document Frequency . Это работает с алгоритмами для рассмотрения текста и улучшения набора слов.
# 2 ТокенизацияПредложения и слова сегментируются вместе в процессе токенизации. В этом случае предложение разделено на различные сегменты, известные как токены, и далее разделено на символы, включая текст и знаки препинания, как показано ниже.
Английский язык и язык НЛП работают по-разному, поэтому для облегчения понимания машины формируются токены. Сегментированные языки передают значение каждого блока, помогая машине определить фактическое значение слов.
Чтобы избежать осложнений, при необходимости токенизация может удалить знаки препинания. В противном случае пунктуации назначается отдельный знак.
# 3 Удаление стоп-словаУпомянутые выше стоп-слова - это предлоги, местоимения и артикли в английском языке. Дело в том, что стоп-слова очень часто встречаются в предложениях, но не имеют значения для алгоритмов обработки естественного языка. В результате объекты отфильтровываются и удаляются часто встречающиеся термины, не содержащие информации по тексту.
Предварительно определенный список ключевых слов используется для удаления остановок работ, которые также освобождают место в базе данных. Однако для стоп-слов нет универсального списка . Они построены или предварительно выбраны в соответствии с требованиями программного обеспечения.
# 4 Стемминг и лемматизацияЭто еще один аспект НЛП, о котором нужно знать. Добавление слова к корню в основном называется корнем. В общих словах добавление префиксов и суффиксов в начало или конец слова обычно называют корнем.
Однако существуют общие проблемы, возникающие при расширении или создании нового слова, которое называется флективными аффиксами и производными аффиксами соответственно. Из-за этого языки программирования NLP, такие как R и Python, используются с разными библиотеками, чтобы обеспечить простоту выполнения процесса стемминга.
В то время как в лемматизации форма слова сокращается или одни и те же слова группируются вместе. Например, времена, синонимы и т. Д. Сгруппированы вместе в соответствии с их значением в стандартизирующих словах.
Словарная форма слов используется в лемматизации в форме леммы , в которой алгоритмы обработки естественного языка просматривают словарь и связывают слова вместе. Это немного объясняется на изображении, приведенном ниже.
# 5 Тематическое моделированиеВ этом случае скрытая структура в документах и тексте раскрывается в соответствии с обработкой отдельных слов, содержимого и последующим присвоением им значения. Однако предположение является основной частью этой техники, в которой темы смешиваются вместе в соответствии со словами.
После завершения распространения скрытый текст обнаруживается с использованием алгоритмов обработки естественного языка, чтобы найти реальное значение текста. Около двух десятилетий назад было запущено Latent Dirichlet Allocation (LDA) как метод тематического моделирования, который работает с методом обучения без учителя.
В этом случае процесс обучения зависит от одной выходной переменной, и используются алгоритмы для анализа данных и поиска закономерностей. LDA использует группу связанных слов как:
- Он использует случайные темы и присваивает им номера, которые вы хотите открыть.Эти случайные темы определяются как числа, которые отображаются с использованием алгоритма для поиска слов в документах.
- Каждое слово сканируется алгоритмом обработки естественного языка с учетом вероятности и переназначения слов теме. Выполняется несколько сканирований и рассчитываются вероятности, пока алгоритмы не достигнут результата.
LDA работает со смесью тем в документе, которая противоположна алгоритму K-средних (который работает с разрозненными темами в загроможденной форме).Это делает результаты более реалистичными и лучше объясняет тему. Таким образом, вы можете сказать, что сейчас подходящее время для инвестиций в разработку приложений искусственного интеллекта.
# 6 вложений словЭто один из основных методов обработки естественного языка (НЛП), в котором векторная форма используется для описания действительных чисел в НЛП. Естественный язык нелегко обработать компьютером. Чтобы преодолеть это, для описания чисел используются векторные формы.
Это отражает суть слов и демонстрирует связь действительного числа с НЛП. Длина вектора 100 используется для представления фиксированного размера.
# 7 Устранение неоднозначности именованных объектов и распознавание именованных объектовВ значении неоднозначности сущности идентифицируются в предложении, таком как имя известного человека, бренд и т. Д. Например, в новостях говорится о новом продукте, выпущенном Apple. Разрешение названной сущности используется для вывода о том, что Apple является здесь брендом, а не плодом с помощью методов НЛП в ИИ.
Принимая во внимание, что при распознавании именованного объекта, объект идентифицируется и классифицируется по дате, организации, человеку, времени, местоположению и так далее.
Например, « 5 октября 2019 года Apple выпустила последнюю версию iPhone в Австралии. ”(новость не соответствует действительности)
Здесь функция Named Entity Recognition погрузит предложение в категорию как:
- Apple ORG
- 5-я ДАТА
- ДАТА октября
- 2019 ДАТА
- Австралия GPE
*** ORG - Организация и GPE - Местоположение ***
# 8 Идентификация языка и обобщение текстаПри идентификации языка язык идентифицируется в соответствии с содержанием с использованием синтаксических и статистических свойств.Принимая во внимание, что суммирование текста похоже на идентификацию языка, но оно укорачивает идентифицируемый текст, что делает его жизненно важной частью учебника по обработке естественного языка для начинающих.
Сценарии использования языка естественной обработки NLP работает на удивление хорошо, когда дело касается обработки речи, обработки естественного языка и интеллектуального анализа текста данных. Концепция чрезвычайно увлекательна, демонстрирует реальную ценность и работает в нескольких областях. Если говорить о повседневной жизни, то НЛП используется в ряде отраслей, таких как:
- Прогнозирование заболеваний - С помощью электронной истории болезни пациента НЛП может легко предсказать и распознать симптомы заболеваний.Будь то шизофрения, депрессия или сердечно-сосудистые заболевания, НЛП может понять фактический статус пациента, используя медицинскую карту и лечение.
- Cognitive Assistant - Это персонализированная поисковая система, которая работает как помощник при поиске песни, напоминая вам название, если вы его забыли, и так далее. Это использует NLP и анализирует пользовательские данные, чтобы дать результат.
- Анализ настроений - Это помогает компаниям понять требования пользователей.Наборы пользовательских данных используются для извлечения информации и определения того, чего они ожидают от службы. Он включает в себя факторы принятия решений и варианты выбора клиентов, которые помогают пользователям предлагать первоклассные услуги.
- Fake News - NLP имеет возможность идентифицировать новости и выяснять, является ли их источник надежным или нет. Это помогает понять, можно ли доверять источнику
- Определение спама - Существует фильтр, который используется Google и Yahoo, который помогает фильтровать электронные письма, чтобы проверить, является ли это спам или нет.
Это лишь некоторые из применений НЛП, которые работают на удивление хорошо и предлагают первоклассные решения для организации. Он используется в качестве голосовых интерфейсов, финансовых отчетов, комментариев, новостей, набора талантов и даже для решения судебных задач.
Проблемы, с которыми сталкивается НЛПКак и другие платформы, у НЛП есть свои собственные наборы проблем, которые описаны ниже:
# 1 Понимание естественного языкаNLP широко зависит от NLP или понимания естественного языка, что помогает в создании обработки естественного языка и интеллектуального анализа текста.Однако реальное понимание может быть немного пугающим для разработчиков, включая структуру и врожденные предубеждения.
Затем идет обучение с подкреплением, что означает, что модель будет изучать все самостоятельно, включая прогнозы, функции и алгоритмы. Однако не все поддерживают этот подход и считают, что им следует объяснять процесс модели.
Машины также недостаточно способны понимать человеческие эмоции, и им необходимо знать об этом.Это упрощает прогнозирование и анализ данных для понимания и использования их в качестве рычага.
# 2 NLP для сценариев с низким уровнем ресурсовА как насчет диалектов и малоресурсного языка? Эта универсальная проблема еще не решена, чтобы решить проблему обучающих данных. Естественный фокус можно легко обработать с помощью определенных языков. Универсальная языковая модель, кросс-языковая репрезентация и ее влияние - вот основные факторы, которые еще предстоит обнаружить.
# 3 Рассуждения о больших или множественных документахНейронные сети используются в текущей модели, но они не так стабильны с более длинным контекстом. Множество документов и большие наборы данных сложно легко анализировать, что требует значительного масштабирования.
Решения обработки естественного языкаобработки естественного языка и интеллектуального анализа текста уже используется рядом компаний по всему миру и относится к подразделам искусственного интеллекта.Многие другие постепенно перенимают эти тенденции для автоматизации важнейших процессов.
Позвольте нам познакомить вас с некоторыми из лучших решений, господствующих на рынке.
# 1 Цифровой GeniusЭто решение в основном предназначено для улучшения поддержки клиентов. Он работает с повторяющимися процессами и легко автоматизирует их, чтобы понять клиентов. Глубокое обучение и API помогают понять потребности клиентов и заказчиков, использующих другие инновационные технологии.
# 2 Ответная ракеткаЭтот инструмент позволяет легко получать отчеты по теме, не дожидаясь более длительного периода. Он разработан с использованием рассуждений и логики, чтобы обобщить решение, которое может помочь получить ответ всего за несколько секунд. Инструмент исследует данные и помогает легко анализировать результат.
# 3 NetomiЭто надуманная мечта, которая сбылась для пользователей. Инструмент достаточно способен автоматизировать решения и легко помочь клиентам.С помощью классификационных моделей сотрудники могут легко умножить штат и понять требования клиентов.
# 4 IBM WatsonРешение на базе IBM основано на разработке машинного обучения NLP и методах NLP в искусственном интеллекте, которые помогают сотрудникам понимать ботов, платформы и приложения, упрощая взаимодействие между компьютерами и людьми.
# 5 Семантические машиныЭто решение немного отличается, оно фокусируется на технологии и легко передает данные, чтобы помочь машине понять их.В дополнение к этому, он работает как разговорный ИИ, который будет править рынком в ближайшие годы. Инструмент используется для обработки диалогов и NLP для поддержки таких задач, как глубокое обучение, синтез речи и лингвистические области.
Будущее НЛПЕсли говорить о настоящем времени, НЛП становится неотъемлемой частью технологии, особенно с решениями машинного обучения, глубокого обучения и искусственного интеллекта в качестве основного фактора. Обучаясь у них, компании теперь могут легко взаимодействовать с клиентами и вносить изменения на рынок.
Методы обработки естественного языка (NLP) в основном используются компаниями для улучшения взаимодействия с клиентами, взаимодействия с данными и достижения желаемого результата. Процессы становятся лучше и быстрее с помощью методов обработки естественного языка (NLP).
Это вводит новую фазу коммуникации с машинами, компании теперь легко принимают решения и становятся более гибкими. Это смена парадигмы технологий на рынке с учетом настроений клиентов.
Организации станут умнее с НЛП и внедрением интеллекта таким образом, чтобы это было полезно для них. Интеграция НЛП с другими технологиями изменит способ работы пользователей с машинами, включая компьютеры и смартфоны.
Когда дело доходит до НЛП, нет предела возможностей, и будущее будет сиять ярче благодаря достижениям.
С учетом сказанного, если у вас есть какие-либо вопросы по НЛП, оставьте комментарий ниже, или если вы хотите разработать приложение с использованием этой технологии, не стесняйтесь обращаться к нам.
Нейролингвистическое программирование (НЛП) - Руководство для начинающих
Что такое нейролингвистическое программирование?
Нейролингвистическое программирование (НЛП) исследует винтики внутри машины, то есть человеческого разума; помогает нам понять, что движет человеческим поведением. Он фокусируется на том, как наши мысли, действия, эмоции и многие другие индивидуальные характеристики работают вместе, чтобы влиять на то, как мы ведем себя.
Разработчики НЛП - Ричард Бэндлер и доктор Джон Гриндер - искали сущность изменения поведения; они были полны решимости понять скрытую грамматику мышления и человеческого поведения. Это желание привело к развитию НЛП. Изучая модели НЛП и используя его навыки, любой может использовать свое собственное ментальное программное обеспечение, изменить привычный образ поведения, - буквально перепрограммировать свой разум.
Возможно, лучше всего сформулировано официальным сайтом нейролингвистического программирования, НЛП помогает нам «узнать, как получить больший контроль над тем, что мы считали автоматическими функциями нашей собственной неврологии. Его методы и идеи - это врата, через которые человек может взглянуть на ситуацию со свежих, новых точек зрения. Они помогают нам переоценить то, как мы справляемся с задачами, участвуем в беседах или реагируем - физически и эмоционально - на обстоятельства, в которых мы находимся.
Нужен курс?
Наш курс «Введение в нейро-лингвистическое программирование» объясняет, как работает НЛП, включает ряд упражнений по НЛП, которые вы можете попробовать, и показывает, как вы можете улучшить свои навыки, чтобы улучшить свою повседневную жизнь, отношения и способы ведения бизнеса.
Введение в метапрограммы
НЛП утверждает, что человеческое поведение почти полностью состоит из привычек и моделей поведения. Каждый может сесть на место водителя в своем мозгу, если поймет, как эти привычки и модели влияют на его поведение. Диапазон тем, охватываемых НЛП, обширен и подробен; слишком обширен, чтобы полностью обсуждать его в одной статье. Однако один из наиболее интригующих вопросов связан с привычками, относящимися к , что именно мотивирует нас, и с обоснованием принимаемых нами решений.
Они называются метапрограммами.
Метапрограммы - это наши умственные процессы, которые управляют, направляют и определяют различные другие умственные процессы. Название заимствовано из терминологии информатики; он ссылается на способы работы программ на компьютере.
Говоря упрощенно, «мета» означает что-то, что находится на более высоком уровне, а «программы» - это то, что заставляет что-то работать на ПК. Таким образом, метапрограммы являются основными «программами» - вашими встроенными привычками, - которые управляют другими «программами» компьютера, которым является ваш разум.Существует множество метапрограмм, присущих НЛП - их больше, чем перечисленных ниже пяти - и вы можете увидеть, как они сформулированы по-разному в Интернете.
5 самых распространенных метапрограмм
Это пять наиболее распространенных метапрограмм, которые определяют, как устроен наш разум и как это определяет наше поведение:
- Туда и обратно
- Внутренний и внешний
- Сходство и различие
- Проактивное и реактивное
- Опции и процедуры
При чтении следующих описаний вы можете заметить, что не вписываетесь только в одну сторону.В самом деле, не все подойдут строго к одному или другому; есть люди, у которых есть и то, и другое. Метапрограммы просто описывают причины поведения людей и соответственно классифицируют их; они не предназначены для разделения людей пополам.
Туда и обратно
Люди, у которых есть программа «навстречу», движимы стремлением к достижению целей; они стремятся к получению удовольствия и достижению целей. Вы легко и часто ставите перед собой цели; это то, что вас мотивирует.Ваше поведение обусловлено желанием чего-то достичь и завершить, что доставляет вам чувство удовлетворения.
Тем не менее, те, у кого есть программа «на выезде», сосредоточены на том, чтобы избавиться от боли и избежать рисков; ими движет предотвращение проблем. Прежде чем продолжить, вы убедитесь, что все в безопасности и не имеет неприятных последствий и потенциальных кризисов.
Внутренний и внешний
Те, у кого есть «внутренняя» программа, устанавливают для себя стандарты одобрения и принятия решений.Вы не будете искать доказательств того, что делаете хорошую работу или принимаете правильное решение; вы «просто знаете», когда вы преуспели и соответствуете своим личным стандартам. Слишком много отзывов может демотивировать вас; вам нужно пространство, чтобы взломать и выполнить задачу по-своему.
Те, у кого есть «внешняя» программа, обращаются к другим за стандартами и указаниями; они требуют внешнего одобрения и руководства. Вы предпочитаете, чтобы вами управляли и контролировали, и вы время от времени получаете удовольствие от похлопывания по плечу, чтобы вы знали, что ваша работа хороша.Без обратной связи вы можете почувствовать себя демотивированным или неуверенным в своих силах.
Сходство и различие
Те, у кого есть программа «сходства», мотивированы сходством в вещах; они легко находят сходства и преуспевают в занятиях, которые не выходят за пределы их зоны комфорта. Это чувство близости успокаивает и помогает сравнивать то, на что вы смотрите, или ваши текущие обстоятельства с предыдущим опытом. Для вас повторение - это хорошо.
Те, у кого есть программа «различий», напротив, приспособлены к различиям в вещах и открыты для пробования новых вещей и создания изменений. Вы ищете несоответствия и активно работаете над их исправлением - точной настройкой, даже если в этом нет необходимости. Признание различий позволяет вам понять и изучить другие возможности.
Проактивное и реактивное
Те, у кого есть «проактивная» программа, являются инициаторами; они без промедления приступят к выполнению поставленной задачи.Вы полностью привержены настоящему и склонны не слишком беспокоиться о том, что произойдет позже. Вы сосредотачиваетесь на реальных вещах - конкретных вещах и вещах, которые, как вы знаете, являются правдой. Вы концентрируетесь на задачах, которые вы выполнили или выполняете в настоящее время.
Те, у кого есть «реактивная» программа, тратят время на планирование и анализ вещей; их решения требуют внимательного рассмотрения. Обычно вы работаете в пределах своего собственного времени - посвящая это время размышлениям - и можете обнаружить, что думаете: «следовало бы», «могло бы», «было бы».Вы сосредоточены на планировании и оценке - ждете подходящего момента и готовитесь к выполнению задачи.
Опции и процедуры
Те, у кого есть программа «опций», работают лучше всего, когда у них есть обзор чего-либо; они не беспокоятся о мелких деталях. Слишком много структуры ограничивает вас, и вы предпочитаете иметь больший выбор. Вам нравится иметь возможность исследовать вещи дальше или другие аспекты для себя.
Те, у кого есть программа «процедур», в качестве альтернативы работают лучше всего, когда им предоставляют конкретные ответы и систематизированные детали.Они стремятся делать все «правильно». Вы предпочитаете распорядок и структуру и хотите получать всю возможную информацию, которая позволит вам работать эффективно.
Многие люди будут иметь смесь этих моделей поведения, но, несомненно, будут склоняться в одну сторону больше, чем в другую. Как бы то ни было, эти метапрограммы НЛП представляют собой интересные окна в человеческий разум и помогают нам понять самих себя.
Кроме того, поскольку эти модели помогают нам понимать других людей, мы можем лучше работать с другими и лучше понимать их личное поведение и предпочтения.НЛП помогает нам наводить мосты с другими.
С помощью НЛП вы можете получить полный контроль над своим разумом и определить способы, которыми вы действуете наиболее эффективно. Это позволит вам обрести позитивный настрой и преуспеть в любой вашей роли. Признавая, каковы внутренние ценности нас самих и других, мы можем адаптироваться к ситуациям и делать все, что в наших силах.
