Характер по почерку. Эксперт-графолог о тайнах почерка
Тайна почеркаРодители и учителя ругают за нестандартный почерк? У нас хорошая новость! Графологи утверждают, что менять почерк нельзя, ведь это отражение твоего внутреннего «я». Манера письма у каждого индивидуальна, как отпечатки пальцев, и серьезное вмешательство приведет к закомплексованности и проблемам в будущем. Впрочем, стремиться к аккуратности при письме, конечно, нужно.
Почерк — это письмо мозга. Этот термин ввел в обращение немецкий профессор Вильгельм Прейер более 120 лет назад. Он исследовал почерки людей, получивших различные травмы, из-за которых они не могли больше писать рукой. Заново научившись письму (с помощью ноги или рта), они писали в той же манере, что и до инвалидности. Основные характеристики их почерков были полностью сохранены! Это навело Прейера на мысль, что именно мозговые импульсы определяют начертания букв. Позже его выводы были подтверждены опытным путем другими учеными.
Сейчас мы чуть-чуть приоткроем завесу тайны и попробуем увидеть в почерке немного больше, чем видят остальные. Прокомментировать самые распространенные признаки мы попросили Сергея Артюшкевича, врача-психотерапевта, эксперта-графолога центра исследования личности «Vecanto», кандидата медицинских наук.
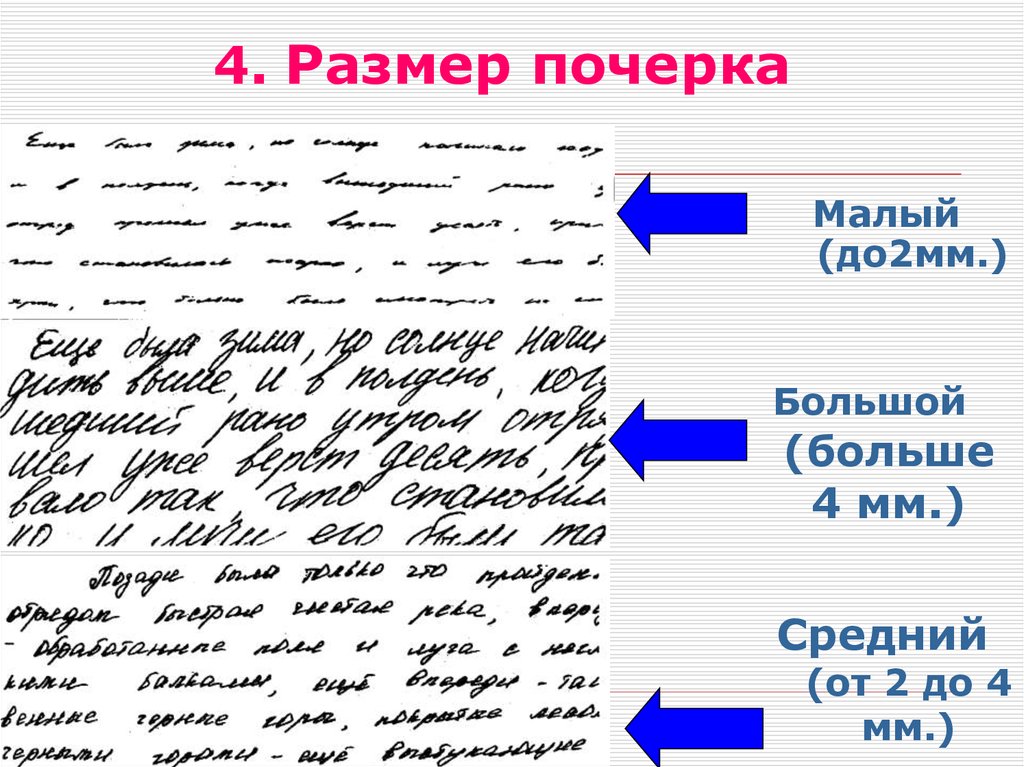
Как определить характер по почеркуМелкий почерк
Если твои буквы слишком мелкие, то это говорит о том, что ты невысоко ценишь себя. Ты можешь достичь значительных успехов в учебе, быть душой компании, лучше всех играть в футбол или победить на конкурсе виолончелистов – и при этом ощущение собственной ничтожности преследует, как тень…
Это может наводить на мысль, что окружающие стремятся ущемить твои права или подавить твою личность. А может, ты ставишь себе слишком высокую планку?
Крупный почеркСлишком крупные буквы свидетельствуют о некоторой инфантильности характера (манера вести себя как ребенок, избегать принятия самостоятельных решений и т. д.). Такой почерк похож на детский, буквы пухлые, полностью округлые, или узкие, но расположенные компактно.
д.). Такой почерк похож на детский, буквы пухлые, полностью округлые, или узкие, но расположенные компактно.
Рукописные символы, похожие на пузырьки, говорят о том, что их хозяин очень старается выглядеть в глазах окружающих как можно лучше, высоко ценит себя (иногда даже слишком высоко).
Выбирая профессию, обладатель крупного почерка нередко продолжает семейную династию, идет по стопам родителей.
Рассматриваем хвостикиЕсли верхняя часть буквы В или нижняя часть букв Д, З слишком высоко/низко взлетает над/под средней частью (кружком), то это тоже свидетельствует о завышенных амбициях.
А вот если хвостики твоих букв маленькие, может быть, даже меньше, чем средняя круглая часть буквы, то это прямое доказательство скромности и невысоких амбиций. Возможно, ты чувствуешь себя скованно в общении с людьми.
Бывает, что хвостики как бы цепляют друг друга. Значит, у пишущего упрямый характер, он признает только свое мнение, ему больше никто не указ. Такая субъективность, несомненно, приводит к конфликтам, ведь человеку очень сложно поставить себя на место другого.
Такая субъективность, несомненно, приводит к конфликтам, ведь человеку очень сложно поставить себя на место другого.
Острый почерк словно зубастый (буквы похожи на зубцы пилы) открыто говорит о конфликте, серьезных внутренних проблемах, о накопленной агрессии. Также при этом буквы мелкие – значит, обладатель почерка старательно подавляет конфликт внутри себя, но не факт, что он справится самостоятельно.
Если речь идет о тебе или твоем друге, то постарайся найти кого-то, кому можно доверить проблему (родители, учитель или психолог Центра дружественного отношения к подросткам – такие есть в поликлиниках, обратиться можно анонимно).
Плотно слепленные буквы, со сросшимися стенками – тоже признак внутреннего конфликта, глубоких переживаний, причем очень серьезных. Не нужно игнорировать это состояние, оно само не пройдет, последствия могут быть плачевными. Поделись своей проблемой с тем из взрослых, кто встанет на твою сторону и обязательно поможет.
Насторожить должен и наклон букв. Например, пишешь правой рукой и буквы обычно наклонены вправо, в крайнем случае, прямые; а в последнее время явно кренятся влево. Подумай, нет ли желания отгородиться от окружающего мира? Может, ты прячешь свои переживания, не желая их показывать? Интроверсия (замыкание в себе) вряд ли принесет что-то хорошее. Может быть, действительно стоит поговорить с близкими по душам, ведь они любят тебя, хоть и не всегда это показывают.
Экспертиза почерка набирает все большую популярность: это возможность заглянуть в свой внутренний мир, понять, чего же ты на самом деле хочешь и в какой сфере сможешь в будущем состояться как профессионал. Куда пойти учиться после школы, почему не клеятся отношения с противоположным полом и когда в жизни наконец начнется белая полоса – с этими и другими вопросами поможет разобраться графолог.
Как определить характер по почерку
|
Эзотерика » Графология (почерк человека) » Как определить характер по почерку Графология (по-гречески » grapho » — писать и » lego — говорю) — искусство познавать и предсказывать характер человека по его почерку. Что говорит почерк о характереВозможность установления по психологии почерка различных свойств личности не получила достаточного научного обоснования, но установлена определенная зависимость почерка от эмоционального состояния и от некоторых типологических свойств человека. Изучение почерка широко используется и в криминалистике. За рубежом графология очень популярна. Объектами исследовании являются размеры букв, их конфигурация, округлость, ширина, наклон почерка и т. д. Эти же параметры используются и российскими криминалистами при решении вопроса о принадлежности текста конкретному лицу. Почерк любого человека отражает его внутренний мир, является информационным кодом личности. Когда человек пишет что-либо, он находится в состоянии напряжения и эмоционального возбуждения, поэтому на бумаге остается энергоинформационный код не просто конкретного субъекта, а человека во времени. Психология почерка, так или иначе, отражает свойства пространства и времени. Как почерк влияет на характер человека Сколько людей, столько и почерков. Влияние характера на почерк очень сильно. Почерк зависит даже от национальности, так как у каждой нации есть определенные особенности письма. Замечено, что у людей, рожденных в разное время года, различаются и почерки. У тех же, кто родился в одно и то же время года, наблюдается некоторое сходство почерка. Например, почти у всех декабрьских людей почерк неровный, прерывистый, прыгающий. Можно определить манеру написания букв и по имени-отчеству человека. У некоторых людей почерк ровный и разборчивый, его обычно называют каллиграфическим. Такие люди очень аккуратны, скрупулезны в делах, дотошны, серьезны, вдумчивы, обязательны, неторопливы. Если же почерк неразборчив настолько, что и сам писавший через некоторое время не может ничего прочитать, значит, перед нами человек энергичный, непоседливый. Ему жалко времени на выписывание каждой буквы, он пишет механически, только для того, чтобы что-то пометить на память. Такие люди всегда сосредоточены на чем-то очень важном для них, они деловые и целеустремленные. Как узнать характер человека по почеркуНижеследующие почерки могут служить более или менее типичными образцами индивидуальности человека.
Наклон почерка и характер Попробуем определить характер по почерку в зависимости от его наклона.
Что говорит почерк о характере человекаЗдесь представлены признаки написания букв, по которым можно изучить взаимосвязь почерка и характер человека. Буква А
Буква Б
Буква В
Буква Г
Буква Е
Буква Ж
Буква З
Буква И
Буква Й
Буква К
Буква Л
Буква М
Буква Н
Буква О
Буква П
Буква Р
Буква С
Буква Т
Буква У
Буква Ф
Буква Х
Буква Ц
Буква Ч
Буква Ш
Буква Щ
Буква Ъ
Буква Ы
Буква Ь
Буква Э
Буква Ю
Буква Я
Психографологический закон может выражаться порою в каком-нибудь единственном штрихе, поэтому в вышеприведенном алфавите в пояснение к некоторым законам даем более одной буквы. Если такие буквы, как, например, а, м, у, г, б, ф, т, ж своими концами опускаются ниже строки, то это указывает на ясный и светлый ум, способность к мышлению и умение упорно преследовать свою цель. Если же эти буквы неравны, заходят слишком далеко как вверх, так и вниз и задевают буквы других строк, то это указывает на запутанность и неясность мысли, потерю памяти, помрачение рассудка. Если промежутки между словами и строками малы и этим нарушается четкость почерка, так что он становится совершенно неразборчивым, то это указывает на полное расстройство умственных способностей и идиотизм. Мы рассказали о том, как проводится определение характера по почерку. Теперь перейдем к подписи. Как определить характер по подписиВо многом подпись человека зависит от его сиюминутного состояния или настроения. Например, человек всегда волнуется при подписании брачного контракта или милицейского протокола. Даже если он и не причастен к преступлению, все равно он очень переживает и его подпись совершенно отлична от той, которую он ставит, расписываясь в ведомости на выдачу зарплаты. Январские люди умеют держать себя в руках в любой ситуации, их подпись всегда четкая и неизменная. Декабрьские настолько неуравновешенны, что каждый раз подписываются по-разному. Признаки характера по подписи В графологии подпись человека может рассказать о многом, порой даже о скрытых чертах характера, которые незаметны при общении с ним.
Теперь вам известно о том, как определить характер по почерку и его подписи. Mon, 27 Jul 2020 16:54:01 +0300 Дивеева Наталья Обязательные для заполнения поля помечены знаком *. Имя:Тема: Комментарий: * Для защиты от спама — введите код: Предсказания на день Гороскоп на 28 апреля 2023 Популярные тесты |
 Графология создана французским аббатом Мишо во второй половине XIX века. Однако еще Аристотель в своих трудах говорил о связи почерка человека с его душевными качествами. Он писал, что каждый человек обладает сугубо индивидуальной манерой выражать свои мысли на бумаге. Из этой статьи вы узнаете о том, как определить характер по почерку.
Графология создана французским аббатом Мишо во второй половине XIX века. Однако еще Аристотель в своих трудах говорил о связи почерка человека с его душевными качествами. Он писал, что каждый человек обладает сугубо индивидуальной манерой выражать свои мысли на бумаге. Из этой статьи вы узнаете о том, как определить характер по почерку. Чтобы узнать характер по почерку, сначала нужно его понять. Графология — один из способов расшифровки характера человека, обычно этим занимаются графологи и психологи.
Чтобы узнать характер по почерку, сначала нужно его понять. Графология — один из способов расшифровки характера человека, обычно этим занимаются графологи и психологи. Так, Андрей Михайлович имеет почерк спокойный, четкий, ровный и разборчивый, а у Игоря Николаевича, особенно рожденного в декабре, почерк размашистый, витиеватый, что говорит о неуравновешенности, повышенной эмоциональности, психической неустойчивости. Внешне он производит весьма положительное впечатление, так как умеет держать себя в руках, однако почерк выдает его с головой.
Так, Андрей Михайлович имеет почерк спокойный, четкий, ровный и разборчивый, а у Игоря Николаевича, особенно рожденного в декабре, почерк размашистый, витиеватый, что говорит о неуравновешенности, повышенной эмоциональности, психической неустойчивости. Внешне он производит весьма положительное впечатление, так как умеет держать себя в руках, однако почерк выдает его с головой. Итак, проведем анализ характера по почерку.
Итак, проведем анализ характера по почерку.


 Неуверенность, трусость, бережливость, скупость
Неуверенность, трусость, бережливость, скупость ..
.. Однако существуют также и общие для ряда букв особенности.
Однако существуют также и общие для ряда букв особенности.
 Такой человек любит рисковать. Часто такие подписи бывают у людей, рожденных в декабре.
Такой человек любит рисковать. Часто такие подписи бывают у людей, рожденных в декабре.Распознавание рукописного ввода: определение, методы и использование
Готовы прямо сейчас упростить развертывание продуктов ИИ? Проверьте:
- Обучение работе с моделями V7
- Рабочие процессы V7
- Автоаннотации V7
- Управление наборами данных V7
Что такое распознавание рукописного ввода?
Распознавание рукописного ввода (HWR) — это способность компьютеров и мобильных устройств получать и интерпретировать рукописный ввод. Входные данные могут быть в автономном режиме (отсканированы с бумажных документов, изображений и т. д.) или онлайн (чувствуется от движения ручек на специальном дигитайзере, например).
Входные данные могут быть в автономном режиме (отсканированы с бумажных документов, изображений и т. д.) или онлайн (чувствуется от движения ручек на специальном дигитайзере, например).
Система распознавания рукописного ввода также включает в себя форматирование, сегментацию на отдельные символы и обучение языковой модели, которая учится составлять осмысленные слова и предложения.
Наиболее популярным методом распознавания рукописного текста является оптическое распознавание символов (OCR). Это позволяет нам сканировать рукописные документы, а затем преобразовывать их в обычный текст с помощью компьютерного зрения.
Преимущества распознавания рукописного ввода
Многие повседневные варианты использования распознавания рукописного ввода делают его полезным в различных отраслях. Давайте рассмотрим несколько преимуществ внедрения этой технологии.
Улучшенное хранение данных
Распознавание рукописного ввода прокладывает путь к оптимальному хранению данных.
Многие файлы, контракты и личные записи содержат рукописную информацию, такую как оригинальные подписи или заметки, которые можно преобразовать в электронный текст с помощью технологий распознавания рукописного текста.
Для электронных данных требуется меньше физического пространства и ресурсов, чем для хранения физических файлов. Это экономично и избавляет от необходимости сортировать, упорядочивать и искать информацию в бумажных документах вручную.
Несколько отраслей уже начали внедрять эту технологию:
- Страховой и банковский секторы оцифровывают формы, налоговые квитанции и историю транзакций в виде электронных PDF-файлов и проверку подписи
- В розничной торговле хранятся счета и история транзакций клиентов
- Медицинские учреждения внедряют стратегии работы с цифровыми данными, такие как электронные медицинские карты (EHR), чтобы уменьшить количество ошибок, вызванных неразборчивыми шрифтами.
- Логистические компании используют технологии HWR для сканирования коносаментов и обнаружения меток на посылках для их сортировки.

Более быстрый поиск информации
Благодаря распознаванию рукописного ввода и электронному хранению данных мы можем извлекать данные намного быстрее, чем из физических копий.
Мы можем быстро найти сохраненную электронную информацию, используя поиск файлов и указав, что мы ищем.
Это похоже на то, что ИТ-индустрия делает для поисковой оптимизации. Индексация интернет-ресурсов упростила поиск информации по ключевым словам в море контента.
Улучшенная доступность
Способность распознавания рукописного ввода идентифицировать текст из изображений и видео и сохранять его в текстовой форме также может способствовать повышению доступности.
Технология оптического распознавания символов используется для преобразования текста в речь, что помогает слепым и слабовидящим людям. Envision представила умные очки на базе искусственного интеллекта с возможностью оптического распознавания символов для чтения любого текста из любого источника.
Envision представила умные очки на базе искусственного интеллекта с возможностью оптического распознавания символов для чтения любого текста из любого источника.
В сфере образовательных технологий OCR может помочь делать заметки или преобразовывать математические уравнения, что значительно облегчает учебу. Например, Microsoft Math позволяет сделать снимок рукописной математической задачи, а система предоставит объяснения, примеры, решения, соответствующие учебные материалы и т. д.
Улучшение обслуживания клиентов
Распознавание рукописного ввода может помочь улучшить бизнес-процессы и сделать их работу более удобной и безопасной для своих клиентов.
Различные организации могут легко оцифровывать рукописные формы, предоставленные их клиентами, для облегчения доступа и более экономичного хранения. Более того, банки, медицинские учреждения и страховые компании, работающие с персональными данными, могут надежно хранить документы в облачных хранилищах. Отсканированные данные требуют надлежащей аутентификации для доступа, что снижает риск нарушения безопасности по сравнению с хранением печатных копий.
Проблемы распознавания рукописного ввода
Как и любая новая технология, распознавание рукописного ввода сопряжено со своими проблемами. Рассмотрим несколько наиболее актуальных.
Различные языковые модели
Из-за большого количества рукописей, вызванного разнообразием языков и алфавитов, которые различаются от региона к региону, возможности распознавания рукописного ввода ограничены и требуют полного просмотра преобразованного текста для сохранения оригинальной рукописи. в электронном формате.
Большое разнообразие
Почерк меняется от человека к человеку. Штрихи, неровности, интервалы между буквами и символами, а также блочный или курсивный почерк затрудняют достижение точности технологиями распознавания рукописного ввода.
Плохое качество изображения
Качество и точность преобразованного текста зависят от качества изображения и присутствующего шума, что затрудняет обработку старых документов, которые со временем ухудшаются.
Методы распознавания рукописного ввода
Онлайновая и офлайновая системы распознавания рукописного ввода [источник]Существует два типа распознавания рукописного ввода в зависимости от того, когда происходит идентификация.
Распознавание рукописного ввода в режиме онлайн
Распознавание рукописного ввода в режиме онлайн включает в себя автоматическое преобразование текста по мере его написания на уникальном дигитайзере или цифровой панели с датчиком, который улавливает движения кончика пера и использует эти динамические данные для оценки символов и слов по мере их появления. пишутся.
Основными функциями, которые позволяют онлайн-системе распознавания рукописного ввода предсказывать текст, являются:
a) качество линии
b) скорость письма/слова
c) исполнение букв автоматическое преобразование изображения текста в буквенные коды, используемые в компьютерах и приложениях для обработки текста. Данные, полученные в таком виде, представляют собой статический снимок почерка.
Данные, полученные в таком виде, представляют собой статический снимок почерка.
Без информации о нажиме пера, направлении штриха и т. д. добиться точности при автономном распознавании сложнее. Однако она по-прежнему востребована, особенно с учетом необходимости оцифровки существующих исторических и архивных документов.
Методы распознавания рукописного текста и вспомогательные архитектуры
Существует несколько методов распознавания человеческого почерка с помощью машинного обучения, и обязательно появятся новые технологии.
Здесь мы суммируем наиболее известные подходы и алгоритмы распознавания рукописного ввода.
CapsNets
Капсульные сети — это одна из новейших и наиболее совершенных архитектур нейронных сетей, которая рассматривается как усовершенствование существующих технологий машинного обучения.
Слой пула в сверточном блоке используется для уменьшения размерности данных и достижения пространственной инвариантности, что означает, что он идентифицирует и классифицирует объект независимо от того, где он находится на изображении.
Одним из основных недостатков является то, что при объединении теряется много пространственной информации о вращении объекта, местоположении, масштабе и других позиционных атрибутах.
Другим недостатком является то, что если положение объекта слегка изменено, активация не меняется вместе с его пропорциями. Это приводит к хорошей точности классификации изображений, но низкой производительности, если вы хотите найти объект именно там, где он находится на изображении.
Динамическая маршрутизация между капсулами [источник]Капсула — это блок нейронов, в котором хранится различный набор информации (о его положении, вращении, масштабе и т. д.) об объекте, который он пытается идентифицировать на заданном изображении в высоком разрешении. -мерное векторное пространство, где каждое измерение представляет что-то особенное в объекте.
Ядра, которые генерируют карты объектов и извлекают визуальные объекты, работают с динамической маршрутизацией, объединяя индивидуальные мнения нескольких групп, называемых капсулами. Это приводит к эквивалентности между ядрами и повышает производительность по сравнению с CNN.
Это приводит к эквивалентности между ядрами и повышает производительность по сравнению с CNN.
На изображении выше показано, как работает сеть CapsNet, когда входные данные изменяются и сжимаются после прохождения через два сверточных блока для формирования 32 первичных капсул по 6 x 6 x 8 капсул в каждой. Эти первичные капсулы подаются в капсулы более высокого уровня, всего десять капсул с 16 размерами каждая, и для этих капсул более высокого уровня рассчитывается предельная потеря для определения вероятности класса.
CNN будут лучше распознавать рукописный текст, если обучающие данные значительны, поскольку модели необходимо изучить большое количество вариаций, чтобы приспособиться к различным стилям почерка. CapsNets помогает уменьшить объем необходимых данных, сохраняя при этом высокую точность.
Многомерные рекуррентные нейронные сети (MDRNN)
RNN/LSTM (долгосрочная память) работают с последовательными данными, но ограничены работой с одномерными данными, такими как текст. Следовательно, они не могут быть прямо распространены на изображения.
Следовательно, они не могут быть прямо распространены на изображения.
Многомерные рекуррентные нейронные сети можно использовать для замены одного рекуррентного соединения в стандартной рекуррентной нейронной сети (RNN) количеством рекуррентных единиц, равным количеству измерений в данных.
Двумерная MDRNN [источник]Во время прямого прохода в каждой точке последовательности данных скрытый слой сети получает как внешний ввод, так и собственные активации от одного шага назад по всем измерениям.
Основной проблемой в системе распознавания является преобразование двумерных изображений в одномерные последовательности меток. Это делается путем передачи входных данных через иерархию уровней MDRNN с блоками функций активации между ними после каждого уровня RNN.
Высота блоков выбирается таким образом, чтобы постепенно сворачивать 2D-изображения в 1D-последовательности, которые затем можно пометить на выходном слое.
💡
Совет от профессионала: Подробнее о том, как это работает, см. в этом документе об автономном распознавании рукописного ввода с помощью MDRNN.
в этом документе об автономном распознавании рукописного ввода с помощью MDRNN.Многомерные рекуррентные нейронные сети нацелены на то, чтобы сделать языковую модель устойчивой к локальным искажениям при каждой комбинации входных измерений (таких как повороты и сдвиги изображения, неоднозначность штрихов и различные стили почерка) и позволить им гибко моделировать многомерный контекст.
Коннекционистская временная классификация (CTC)
Коннекционистская временная классификация (CTC) — это алгоритм, который имеет дело с такими задачами, как распознавание речи, распознавание рукописного ввода и т. д., где все входные данные сопоставляются с выходным классом/текстом.
Распознавание рукописного текста включает сопоставление изображений с соответствующим текстом. Однако мы не знаем, как участок изображения совмещен с символами. Без этой информации традиционные подходы не работают.
Временная классификация коннекционистов (CTC) — это способ обхода без знания того, как определенная часть звуковой речи или изображения почерка соотносятся с определенным символом. Простые эвристики, такие как присвоение каждому символу одной и той же области, не будут работать, поскольку количество места, которое занимает каждый символ, зависит от почерка.
Простые эвристики, такие как присвоение каждому символу одной и той же области, не будут работать, поскольку количество места, которое занимает каждый символ, зависит от почерка.
Входными данными для этого алгоритма является векторное представление изображения рукописного текста. Нет прямого соответствия между представлением пикселей изображения и последовательностью символов. CTC стремится найти это сопоставление, суммируя вероятности всех возможных совпадений между ними.
Модели, обученные с помощью CTC, обычно используют рекуррентную нейронную сеть (RNN) для оценки вероятностей для каждого временного шага, поскольку RNN учитывает контекст во входных данных. Он выводит баллы символов для каждого элемента последовательности, представленного матрицей.
Стратегия декодирования наилучшего пути для поиска наиболее вероятного текста [источник]Для декодирования мы можем использовать:
- Декодирование наилучшего пути , которое включает в себя предсказание предложения путем объединения наиболее вероятного символа с отметкой времени для формирования полного слова, который дает лучший путь.
 На следующей итерации обучения повторяющиеся символы и пробелы удаляются, чтобы лучше декодировать текст.
На следующей итерации обучения повторяющиеся символы и пробелы удаляются, чтобы лучше декодировать текст. - Декодер поиска луча, , где предлагается несколько выходных путей с наивысшей вероятностью. Пути с меньшей вероятностью отбрасываются, чтобы размер луча оставался постоянным. Результаты, полученные с помощью этого подхода, более точны и часто сочетаются с языковыми моделями для получения значимых результатов.
💡
Совет от профессионала: Ознакомьтесь с автокодировщиками в глубоком обучении: руководство и примеры использованияМодели-трансформеры
RNN идеально подходят для моделирования текстовых данных, поскольку они могут фиксировать их временной аспект. Но они также связаны со стоимостью обучения, поскольку последовательные конвейеры предотвращают распараллеливание и ограничение памяти при обработке более длинных последовательностей. Модели-трансформеры применяют другую стратегию, используя само-внимание для запоминания всей последовательности.
Неповторяющийся подход к почерку достигается с помощью моделей-трансформеров.
Обращайте внимание на то, что вы читаете
Модель трансформатора в сочетании с многоуровневым уровнем самоконтроля как на визуальном, так и на текстовом уровне может изучать связанные с языковой моделью зависимости последовательностей символов, подлежащих декодированию.
Знание языка встроено в саму модель, поэтому нет необходимости в каких-либо дополнительных этапах постобработки с использованием языковой модели. Он также хорошо подходит для прогнозирования выходных данных, которые не являются частью словаря.
Обзор архитектуры модели «Внимание тому, что вы читаете» [источник]Архитектура «Внимание тому, что вы читаете» состоит из двух частей:
- Транскрайбер текста , предназначенный для вывода декодированных символов путем взаимного обслуживания визуальные и языковые функции
- Кодировщик визуальных функций предназначен для извлечения соответствующей информации из изображений рукописного текста путем сосредоточения внимания на различных позициях символов и их контекстуальной информации

Сети кодировщика-декодера и внимания
Архитектура модели кодировщика-декодера в сочетании с сетью внимания [источник]Обучающие системы распознавания рукописного ввода всегда страдают от нехватки обучающих данных, поскольку невозможно создать набор со всеми комбинациями языков, узоры штрихов и т. д.
Чтобы решить эту проблему, этот метод использует предварительно обученные векторы признаков текста в качестве отправной точки. Современные модели намекают на использование механизма внимания в сочетании с RNN, чтобы сосредоточиться на полезных функциях в каждой отметке времени.
Полную архитектуру модели можно разделить на четыре этапа:
1. Преобразование
Сеть CNN обучена локализации. Он берет входное изображение и изучает координаты реперных точек, используемых для захвата формы текста. Поскольку рукописные слова могут быть наклонены, перекошены, искривлены или иметь неправильную форму, изображения входных слов нормализуются путем применения некоторых преобразований.
2. Извлечение признаков
Особенности в рукописном тексте включают углы штриха, серии наклонов и т. д., для которых можно использовать архитектуру типа ResNet для кодирования нормализованного входного изображения в 2D-визуализацию. карта характеристик.
3. Моделирование последовательности
Функции, извлеченные на предыдущем шаге, используются в качестве последовательного фрейма (так же, как текст слева направо). Он декодируется с использованием двунаправленного LSTM для последовательного моделирования, чтобы сохранить контекстную информацию в последовательности с обеих сторон и распознать каждый символ независимо, принимая во внимание абстракции более высокого уровня.
4. Предсказание
Выходные векторы, содержащие контекстную информацию из последнего декодера, преобразуются в слова. Во-первых, выходной вектор необходимо передать в полносвязный линейный слой, чтобы получить вектор размера словаря, который используется для обучения модели. Затем к этому вектору применяется функция softmax в качестве функции активации, чтобы получить оценку вероятности для каждого слова в словаре.
Затем к этому вектору применяется функция softmax в качестве функции активации, чтобы получить оценку вероятности для каждого слова в словаре.
Scan, Attend and Read
Scan, Attend and Read — метод, предложенный для сквозного распознавания рукописного ввода с использованием механизма внимания. Он сканирует всю страницу за один раз. Следовательно, это не зависит от предшествующей сегментации всего слова на символы или строки. Алгоритм
Scan-As-You-Read для распознавания рукописного ввода с многомерным чередованием слоев LSTM [источник] Этот метод использует многомерную архитектуру LSTM (MDLSTM) в качестве средства извлечения признаков, аналогичного описанному выше. Единственным отличием является последний слой, где извлеченные карты объектов свернуты по вертикали, а для распознавания соответствующего текста применяется функция активации softmax.
Используемая здесь модель внимания представляет собой гибридную комбинацию внимания, основанного на содержании, и внимания, основанного на местоположении. Модули декодера LSTM принимают предыдущую карту состояния и внимания, а также функции кодировщика для генерации окончательного выходного символа и вектора состояния для следующего прогноза.
Convolve, Attend и Spell
Распознавание рукописного текста во многом связано с распознаванием образов.
Последовательные нейронные сети, поддерживаемые механизмом внимания, могут стать передовым методом распознавания рукописного ввода, как подчеркивается в этой статье о модели Convolve, Attend и Spell.
Convolve, Attend and Spell — это модель последовательного распознавания рукописных слов, основанная на механизме внимания. Архитектура состоит из трех основных частей:
- кодировщик, состоящий из CNN и двунаправленного GRU
- механизм внимания, фокусирующийся на соответствующих функциях
- декодер, образованный однонаправленным GRU, способный произносить соответствующее слово по буквам
(RNN) лучше всего подходят для временного характера текста. В сочетании с такими рекуррентными архитектурами механизмы внимания играют решающую роль в сосредоточении внимания на нужных функциях на каждом временном шаге.
В сочетании с такими рекуррентными архитектурами механизмы внимания играют решающую роль в сосредоточении внимания на нужных функциях на каждом временном шаге.
Модели последовательностей (seq2seq) следуют парадигме кодер-декодер.
Работа Listen, Attend и Spell для распознавания рукописного ввода [источник]Кодер состоит из сверточной нейронной сети (CNN), которая извлекает визуальные особенности из письменного текста, последовательно закодированного RNN. Декодер — это еще одна RNN, которая декодирует по одному символу за раз, создавая таким образом целое слово и записывая его по буквам .
Механизм внимания связывает кодировщик и декодер, чтобы обеспечить высококоррелированный вектор контекста, который фокусируется на характеристиках каждого символа на каждом временном шаге декодирования.
Эффективность распознавания кодировщика-декодера или любого другого алгоритма распознавания последовательностей seq2seq ухудшается, если вводимый текст длинный из-за таких ограничений, как зависимость от большого диапазона и т. д. Единицы внимания помогают искать набор позиций в скрытых состояниях кодировщика, где находится наиболее важная информация. доступный.
Генерация рукописного текста
Генерация синтетического рукописного текста — это задача создания реалистично выглядящего рукописного текста. Его можно использовать для улучшения существующих наборов данных.
Модели глубокого обучения требуют большого количества данных для обучения, а получение обширного корпуса аннотированных изображений рукописного ввода для разных языков является трудоемкой задачей.
Мы можем использовать генеративно-состязательные сети для создания обучающих данных для решения этой проблемы.
ScrabbleGAN
Распознавание рукописного текста имеет ограниченный объем обучающих данных, поскольку у каждого человека свой уникальный стиль письма. Сбор разнообразного набора наборов данных обходится очень дорого, а аннотировать текст еще сложнее.
Чтобы свести к минимуму эту потребность в сборе данных и аннотировании рукописных данных, хорошо подходит полууправляемое обучение. Он использует комбинацию размеченных и неразмеченных выборок данных для повышения производительности моделей. По сравнению с полностью контролируемыми моделями, он учится определять лучшие функции и лучше адаптироваться к невидимым изображениям.
ScrabbleGAN — это полууправляемый подход к синтезу рукописных текстовых изображений. Он основан на генеративной модели, которая может генерировать изображения слов произвольной длины с использованием полностью сверточной сети.
Кроме того, генератор достаточно умен, чтобы манипулировать результирующим стилем текста и штрихами. В дополнение к дискриминатору D результирующее изображение также оценивается сетью распознавания текста R. В то время как D способствует реалистичному стилю рукописного ввода, R способствует тому, чтобы результат был удобочитаемым и соответствовал введенному тексту.
💡 Совет от профессионала: Чтобы узнать, как использовать синтетические данные для обучения моделей машинного обучения, прочтите статью Что такое синтетические данные в машинном обучении и как их генерироватьКлючевой вывод
Технология распознавания рукописного ввода находится на переднем крае исследований ИИ.
Это полезно во многих отраслях, обеспечивая лучшее хранение данных, более быстрый поиск информации, доступность и более эффективные бизнес-процессы.
Появляются новые методы решения таких проблем, как непредсказуемость, изменчивость или качество изображения.
Некоторые из наиболее известных архитектур включают:
- CapsNets
- Многомерные рекуррентные нейронные сети
- Временная классификация коннекционистов
- Модели преобразователей
- Кодировщик-декодер и сети внимания 9 0006
- Генеративно-состязательные сети
определение почерка по Медицинский словарь
Почерк | определение почерка по Медицинскому словарю
https://medical-dictionary.thefreedictionary.com/handwriting
Также найдено в: Словарь, Тезаурус, Юридический, Финансовый, Акронимы, Идиомы, Энциклопедия, Википедия.
Связанные с почерком: анализ почерка, курсивный почерк
(почерк) 1. Написание букв, цифр, слов или символов ручной ручкой или карандашом.
2. Чистописание. Плохой почерк характерен для некоторых детских расстройств обучения и некоторых болезней взрослых, таких как микрография при болезни Паркинсона.
Медицинский словарь, © 2009 Farlex and Partners
Упоминается в ?
- тремор действия
- какография
- CC
- Куриные царапины
- кубический сантиметр
- опасные сокращения, акронимы и символы
- документ
- Дауни, Джун Этта
- электронное выписывание рецептов
- электронная подпись
- электронное выписывание рецептов
- зрительно-моторная координация
- мелкая моторика
- графология
- графопатология
- графофобия
- графотерапия
- собственноручная подпись
- болезнь Гентингтона
Ахмад сказал, что образцы почерка Абдула Разака были получены в комнате для допросов в Букит-Амане.
Разак Багинда предоставил образцы почерка, сообщил суд.
КУРСИВОЕ ПИСЬМО ВОЗВРАЩАЕТСЯ В УЧЕБНУЮ ПРОГРАММУ ШКОЛ США
Однако суд также отметил, что суд не может вызывать врачей в каждом отдельном случае для чтения их почерка в медицинских отчетах, как сообщает New Indian Express.
Суд штрафует врачей за плохой почерк
Он сказал, что, просто взглянув на чей-то почерк, графолог может определить основной темперамент человека, эмоциональную стабильность, выносливость и энергию, стили обучения, движущие силы, сдерживающие факторы, страхи, реакцию на давление, целостность, социальные предпочтения, способности и ловкость рук.
Измените почерк, чтобы решить свои проблемы
СТОИМОСТЬ ПОТЕРИ ПОЧЕКА
Факторы, как внутренние, так и внешние по отношению к учащемуся, влияют на приобретение навыков письма (van der Merwe, Smit, & Vlok, 2011).
Восприятие учителями потребностей и поддержки в обучении письму в детском саду
В ряде недавних исследований отмечается, что почерк «содействует распознаванию букв, чтению и письму» (Kiefer & Velay, 2016, стр. 9).0003
Почему, кто, что, когда и как обучает письму
Образование имеет значение
Однако, несмотря на более широкое использование компьютеров для письма, умение писать от руки остается важным в образовании, на работе и в повседневной жизни», — отметила она9.0003
Больше детей, нуждающихся в помощи почерка
предложил метод обнаружения метода распознавания почерка амазигов.
Распознавание рукописного письма на английском языке
Внесено модератором в список. Реддиторам сообщается, что здесь не место обращаться за помощью в написании рукописного текста — для этого люди могут перейти в сабреддит «Рукописный ввод».
Порнография с чистописанием — самая приятная вещь в Интернете?
Несмотря на достижения в области технологий и использования компьютеров в школах, значительная часть школьного дня в Австралии состоит из рукописных заданий (Graham et al., 2008; Marr, Cermak, Cohn, & Henderson, 2003; Ziviani & Watson-Will). , 1998).
Сравнение почерка учащихся средних школ с нарушениями зрения и зрячих учащихся
Медицинский браузер ?
- ▲
- пистолет
- портативный
- портативный электронный рецепт
- гандикап
- принцип гандикапа
- инвалид
- поставщик медицинских услуг для инвалидов
- синдром Хандигоду
- ручка
- рукоятка молоточка
- валик рукоятки
- манипулирование
- передача
- передача
- упражнение «рука-в-рот»
- упражнение «рука-в-рот» (H.

