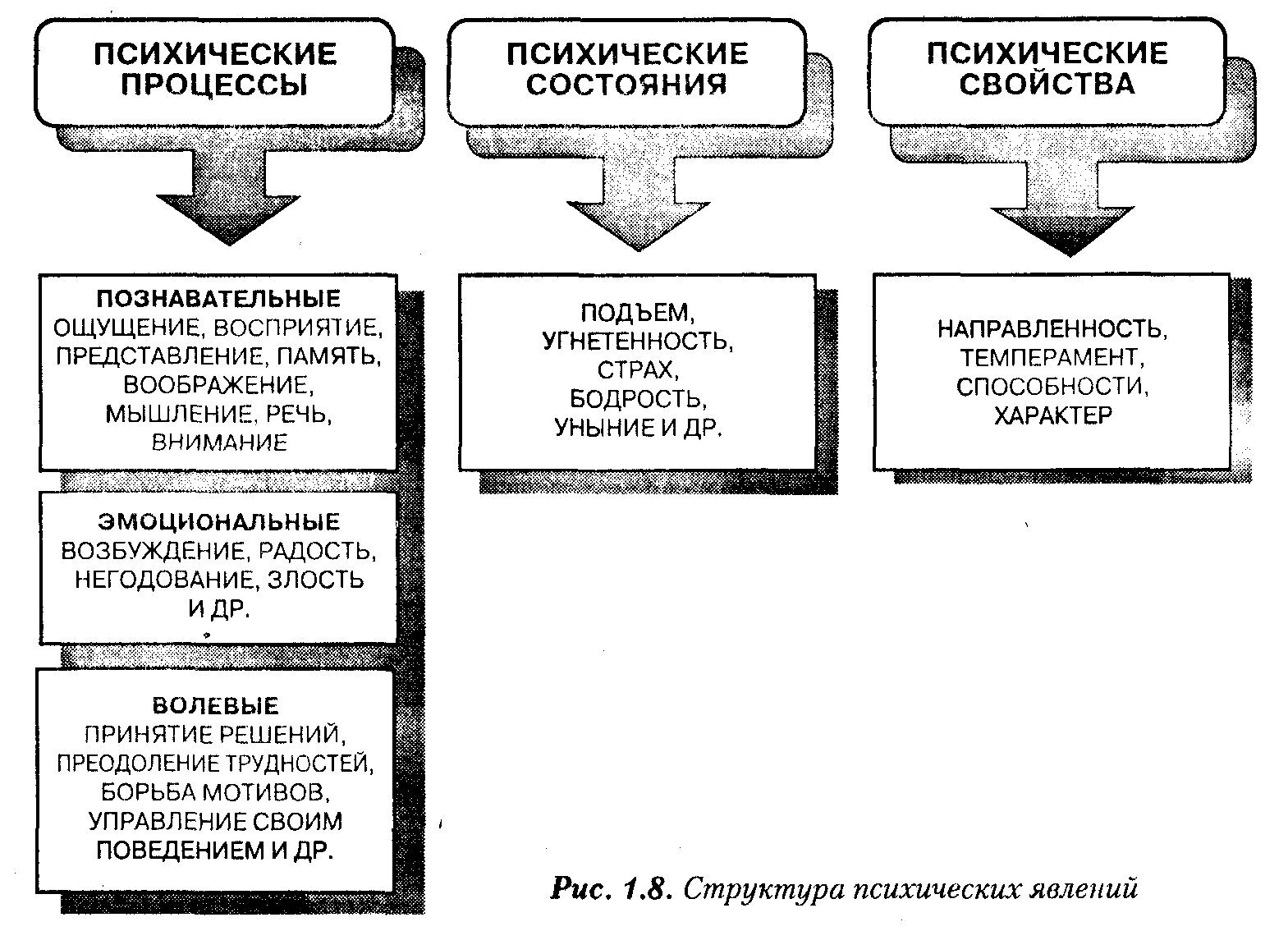
10. Структура внимания. Наблюдательность как свойство личности.
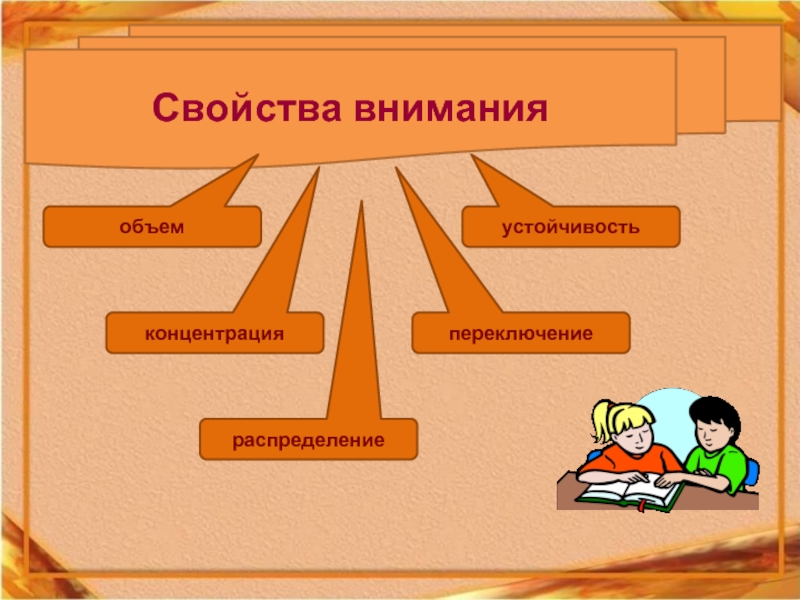
Когда говорят о развитии, воспитании внимания, то имеют в виду совершенствование свойств внимания. Различают следующие свойства внимания:Объем, сосредоточенность (концентрация), распределяемость, устойчивость, колебание, переключаемость.
Объем
внимания измеряется тем количеством
объектов, которые воспринимаются
одновременно.Обычно объем внимания
зависит от специфически практической
деятельности человека, от его жизненного
опыта, от поставленной цели, от
особенностей воспринимаемых объектов.
Объединенные по смыслу объекты
воспринимаются в большем количестве,
чем не объединенные. У взрослого человека
объем внимания равен 4-6 объектам.Концентрация
внимания есть степень сосредоточения
сознания на объекте (объектах).Чем
меньше круг объектов внимания, чем
меньше участок воспринимаемой формы,
тем концентрированнее внимание.Концентрация
внимания обеспечивает углубленное
изучение познаваемых объектов и явлений,
вносит ясность в представления человека
о том или ином предмете, его назначении,
конструкции, форме.
Таким
образом, чем лучше человек овладел
действиями, тем легче ему одновременно
выполнять их.Устойчивость внимания не
означает сосредоточенности сознания
в течение всего времени на конкретном
предмете или его отдельной части,
стороне. Под устойчивостью понимается
общая направленность внимания в процессе
деятельности. На устойчивость внимания
значительное влияние оказывает
интерес.Необходимым условием устойчивости
внимания является разнообразие
впечатлений или выполняемых действий.
Восприятие однообразных по форме,
цвету, размерам предметов, однообразные
действия снижают устойчивость внимания.
Физиологически это объясняется тем,
что под влиянием длительного действия
одного и того же раздражителя возбуждение
по закону отрицательной индукции
вызывает в том же участке коры торможение,
что и ведет к снижению устойчивости
внимания.
Под устойчивостью понимается
общая направленность внимания в процессе
деятельности. На устойчивость внимания
значительное влияние оказывает
интерес.Необходимым условием устойчивости
внимания является разнообразие
впечатлений или выполняемых действий.
Восприятие однообразных по форме,
цвету, размерам предметов, однообразные
действия снижают устойчивость внимания.
Физиологически это объясняется тем,
что под влиянием длительного действия
одного и того же раздражителя возбуждение
по закону отрицательной индукции
вызывает в том же участке коры торможение,
что и ведет к снижению устойчивости
внимания.
Влияет
на устойчивость внимания и активная
деятельность с объектом внимания.
«Внимание к объекту, – пишет
Станиславский, – вызывает естественную
потребность что-то сделать с ним.
Действие же еще более сосредоточивает
внимание на объекте. Таким образом,
внимание, сливаясь с действием и взаимно
переплетаясь, создает крепкую связь с
объектом».Свойством, противоположным
устойчивости, является отвлекаемость.
Переключение
внимания состоит в перестройке внимания,
в переносе его с одного объекта на
другой.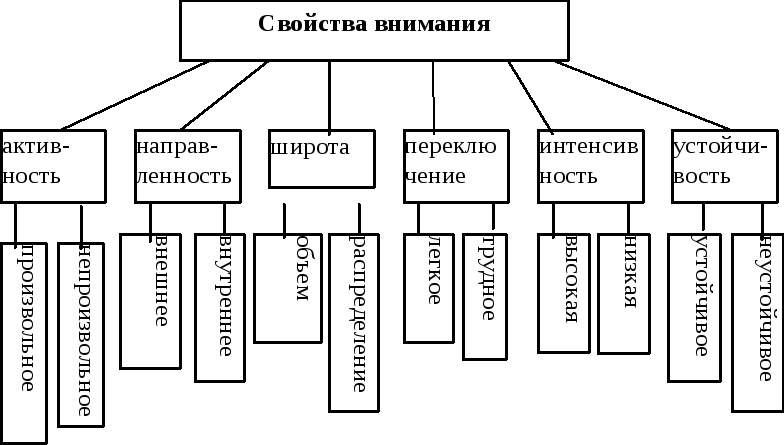
Непреднамеренное переключение внимания обычно протекает легко, без особого напряжения и волевых усилий.
Основы нейропсихологии
1. Предмет, задачи и методы нейропсихологии. Направления современной нейропсихологии. Значение нейропсихологии для медицинской практики. 22. Лурия А.Р. – основоположник отечественной нейропсихологии. История изучения локализации высших психических функций. 2
3. Определение нейропсихологических симптома, синдрома, фактора. 3
4. Теория системной динамической локализации функций. 3
5. Понятие высших психических функций, их специфические признаки. 3
3
6. Горизонтальная и вертикальная организация мозга. 4
7. Концепция А.Р. Лурии о трех основных структурно-функциональных блоках. 8. Специфика вклада структурно-функциональных блоков в осуществление высших психических функций. 4
9. Функциональные особенности первичных, вторичных и третичных корковых полей задних и передних отделов мозга. 5
10. Функциональная асимметрия мозга. 5
11. Межполушарное взаимодействие. Межполушарные связи. Синдром «расщепленного мозга». 7
12. Латеральные особенности нарушений гностических процессов, произвольных движений и действий. 9
13. Принципы строения зрительного анализатора и сенсорные нарушения его работы. 9
14. Нарушения зрительного гнозиса при поражениях вторичных корковых полей. Виды зрительных агнозий. 11
15. Нарушения зрительного восприятия при поражении левого и правого полушарий мозга (у правшей). 12
16. Основные принципы строения кожно-кинестетического анализатора. 12
12
17. Виды общей чувствительности, их рецепторные аппараты, проводящие пути. Сенсорные нарушения работы кожно-кинестетической системы. 12
18. Нарушения тактильного гнозиса при поражении вторичных полей коры. Виды тактильной агнозии. 13
19. Основные принципы строения слухового анализатора и сенсорные нарушения работы слуховой системы. 13
20. Гностические слуховые нарушения при поражении вторичных корковых полей. 14
21. Нарушение речевого фонематического слуха. 14
22. Афферентные и эфферентные механизмы произвольного двигательного акта. 15
23. Концепция Н.А. Бернштейна об уровневой организации мозговых механизмов двигательной системы. 15
24. Пирамидная система. Основные принципы строения. Нарушения двигательных актов при поражении разных уровней пирамидной системы. 16
25. Экстрапирамидная система. Основные принципы строения. Нарушение движений при поражении разных уровней экстрапирамидной системы. 17
17
26. Апраксии. Классификация апраксий по А.Р. Лурия. 19
27. Третий структурно – функциональный блок мозга. Агранулярная и гранулярная кора. 19
28. Проявление нарушений произвольной регуляции различных форм психической деятельности и поведения в целом. 19
29. Психологическая структура речи. Экспрессивная и импрессивная речь. 22
30. Виды речевой деятельности. Речевые функции. Периферические и центральные механизмы речи. 23
31. Афазия. Определение. Афазия как системный дефект. Классификация афазий (по А.Р. Лурия). 23
32. Нарушения афферентных звеньев речевой функциональной системы (эфферентные афазии). 24
33. Нарушения парадигматической и синтагматической организации речи при поражении задних и передних отделов коры левого полушария. 24
34. Роль правого полушария в организации речевой деятельности. 25
35. Психологическая организация процессов памяти. Виды, формы памяти. 36. Нарушения памяти. Теории забывания. Ретроактивное и проактивное торможение. 26
Виды, формы памяти. 36. Нарушения памяти. Теории забывания. Ретроактивное и проактивное торможение. 26
37. Модально–неспецифические нарушения памяти. Модально-специфические нарушения памяти. 27
38. Нарушения памяти как мнестической деятельности. 27
39. Психологическая структура внимания. Формы внимания. 28
40. Модально-неспецифические нарушения внимания. Модально-специфические нарушения внимания. Симптомы «игнорирования» раздражителей. 28
41. Психологическая структура мышления. Виды мышления. 42. Нарушения мышления при поражении лобных долей мозга. 43. Нарушения мышления при поражении задних отделов мозга. 44. Нарушения мышления при поражении височных и премоторных отделов мозга. 29
45. Нарушения эмоционально-личностной сферы при локальных поражениях мозга. 31
Общая задача для всех направлений: изучение мозговых механизмов психической процессов.
1. Клиническая нейропсихология (при локальных поражениях мозга). Задача: изучение нейропсихологических синдромов, возникающих при поражении того или иного участка мозга, и сопоставлении их с общей клинической картиной заболевания.
Задача: изучение нейропсихологических синдромов, возникающих при поражении того или иного участка мозга, и сопоставлении их с общей клинической картиной заболевания.
2. Реабилитационное направление – реабилитация после локального поражения мозга. Задача: восстановление ВПФ, нарушенных вследствие локальных поражений головного мозга.
3. Экспериментальная нейропсихология – изучает нарушения ВПФ с помощью экспериментов. Задача: экспериментальное (клиническое и аппаратурное) изучение различных форм нарушений психических процессов при локальных поражениях мозга и других заболеваниях ЦНС.
4. Нейропсихология детского возраста. Специфика нарушений психических функций у детей при локальных мозговых поражениях.
6. Нейропсихология индивидуальных различий – исследуется профилелотеральная организация. Задача: изучение мозговой организации психических процессов и состояний у здоровых лиц. Ответ на вопрос: возможно ли в принципе распространение общих нейропсихологических представлений о мозговой организации психики, сложившихся при изучении последствий локальных поражений головного мозга, на изучение мозговых механизмов психики здоровых лиц. Психодиагностика с применением нейропсихологических зна-ний в целях профотбора, профориентации и т.п.
Психодиагностика с применением нейропсихологических зна-ний в целях профотбора, профориентации и т.п.
7. Нейропсихология пограничных состояний. Анализ изменений ВПФ под влиянием психофармакологических препаратов.
8. Психофизиологическое направление – изучаются ВПФ психофизиологическими методами.
Предметом нейропсихологии является изучение мозговой организации психических процессов, эмоциональных состояний и Личности на материале патологии и прежде всего – на материале локальных поражений головного мозга.
Каталог: ld
ld -> —
ld -> Мультикультурное образование в сша, канаде и австралии
ld -> На правах рукописи
ld -> Программа оптимизации процесса профессионального самоопределения студентов-психологов
ld -> Формирование русскоязычной профессиональной коммуникативной компетенции студентов юридического профиля в условиях полиязычия 13. 00. 02 теория и методика обучения и воспитания
ld -> Управление образовательными инновациями вуза на основе информационно-аналитической деятельности
ld -> Информационно-аналитическое сопровождение образовательных инноваций вуза: основные принципы и подходы
ld -> Современное состояние и тенденции развития поликультурного образования в США
ld -> Субкультура детства как источник экологического развития детей в дошкольном образовании 13. 00. 07 теория и методика дошкольного образования
00. 07 теория и методика дошкольного образования
Мэрайя Раджа » Понимание структур внимания
Однажды структура внимания…Наше внимание долгое время было направлено в очень узкий туннель; Лучше всего это можно объяснить тем, что есть начальная точка и одна конечная точка, но с разными углами фокусировки. Однако в последние годы из-за интеграции социальных сетей и цифровых медиа в нашу повседневную жизнь наше внимание было смещено в сторону начальной точки, но с множеством ответвлений и многочисленных фокусных точек без определенной конечной точки. Социальные сети позволили или вынудили нас сосредоточить наше внимание способами, о которых мы, возможно, не полностью осознаем. В самостоятельном эксперименте «Подписано» я проследил, как за две недели изменилась структура моего внимания, полностью оторвавшись от всех сайтов социальных сетей. Переход был поучительным для свидетеля, потому что я не полностью осознавал, насколько мое участие или участие в этих сайтах социальных сетей изменило то, как я обращал внимание, на что я обращаю внимание, кому я уделяю внимание.
 к, и как некоторые аспекты сайтов требовали внимания. «Подписано» позволило мне отточить, как изменилось мое внимание и, возможно, как социальные сети изменили все наши структуры внимания.
к, и как некоторые аспекты сайтов требовали внимания. «Подписано» позволило мне отточить, как изменилось мое внимание и, возможно, как социальные сети изменили все наши структуры внимания.Внимание Структуры – Что за ерунда?
В книге
Understanding Digital Literacities , 1 Родни Х. Джонса и Кристофера А. Хафнера они объясняют в своей главе «Структуры внимания»: «Структуры внимания — это технологические средства, используемые людьми для осмысления информации. переизбыток информации, с которым они сталкиваются в век цифровых технологий» (87) 2 . Далее они объяснили, что на эту структуру влияют три элемента:- Историческое тело – Вы и Ваш разум
- Заказ на взаимодействие – Ваше отношение к окружающим вас людям
- Разговоры на месте — Средства коммуникации доступные в ситуации
- Предоставлено: Understanding Digital Literacities (стр.
 87)
87)
Эти элементы уступают место приписыванию того, что то, как мы обращаем внимание, не находится ни полностью в нашем собственном сознании, ни полностью вне его, а является комбинацией того и другого. Джонс и Хафнер утверждают, что если и когда эти элементы или компоненты внимания текут или синхронизируются таким образом, что мы склонны чувствовать, что наше внимание «течет правильно, что мы обращаем внимание на то, на что нам нужно обратить внимание, мы делаем свою работу эффективно».(87)
3 . В таком сообществе, как Instagram, трудно не поверить, что эти элементы не работают вместе. Ваше историческое тело занято вашим размещением СМИ, вы находитесь в постоянных отношениях с другими, и вы постоянно комментируете, лайкаете, обмениваетесь прямыми сообщениями или делитесь. Вы используете все эти элементы, но действительно ли это эффективно? Вместе с моей отстраненностью появилась возможность видеть, сколько внимания я уделяю таким сайтам, как Instagram, и во сколько это мне обошлось. На сайтах социальных сетей, таких как Instagram 4 , нормы внимания устанавливаются молча.
На сайтах социальных сетей, таких как Instagram 4 , нормы внимания устанавливаются молча.Как мы все знаем, существуют определенные критерии для фотографий, которые мы публикуем, вещей, которые нам нравятся, людей и продуктов, с которыми мы работаем; это значит быть в стороне от внимания и генерировать собственное внимание. Когда я отключился, мое социальное действие переместилось с моих сайтов в социальных сетях. Я стал обращать внимание на окружающих и вникал в наши отношения. Я смог увидеть, что средства коммуникации недоступны в реальной жизни. Я не мог удалить или обновить слова, которые я сказал, поэтому мне пришлось уделять пристальное внимание тому, что я сказал. Я стал замечать слова, когда они покидали рот говорящего, я замечал тон и не должен был его угадывать; благодаря тому, что мое внимание переключилось, я снова смог жить в мире до появления социальных сетей, и я мог видеть этот мир в более широкой картине, а не в потоке постоянно обновляемых.
Во многих или во всех социальных сетях внимание пользователей часто требуется незаметно.
 Нас постоянно бомбардируют новыми функциями, которые больше привлекают наше внимание. Недавнее добавление в Твиттер Моментов 5 только создало для нас еще один новый способ локализовать наше внимание в сообществе. То, как мы распределяем наше внимание, — это то, что Джонс и Хафнер называют треками внимания. Следы внимания — это то, как мы распределяем наше внимание между различными вещами (85) 6 . В случае с Moments в Твиттере мы концентрируем наше внимание на определенных хэштегах или твитах, которые позволяют нам глубже погрузиться в обсуждение определенного сообщества или события. Эти треки внимания часто сопровождаются иллюзорным вниманием, которое, как объяснили Джонс и Хафнер, является иллюзией личного внимания, даже если они адресованы более широкой аудитории, например, автоматические ответы, сообщения об отсутствии, напоминания, а также фильтрация. Даже когда мы не уделяем непосредственного внимания социальным сайтам, наше внимание все равно уделяется.
Нас постоянно бомбардируют новыми функциями, которые больше привлекают наше внимание. Недавнее добавление в Твиттер Моментов 5 только создало для нас еще один новый способ локализовать наше внимание в сообществе. То, как мы распределяем наше внимание, — это то, что Джонс и Хафнер называют треками внимания. Следы внимания — это то, как мы распределяем наше внимание между различными вещами (85) 6 . В случае с Moments в Твиттере мы концентрируем наше внимание на определенных хэштегах или твитах, которые позволяют нам глубже погрузиться в обсуждение определенного сообщества или события. Эти треки внимания часто сопровождаются иллюзорным вниманием, которое, как объяснили Джонс и Хафнер, является иллюзией личного внимания, даже если они адресованы более широкой аудитории, например, автоматические ответы, сообщения об отсутствии, напоминания, а также фильтрация. Даже когда мы не уделяем непосредственного внимания социальным сайтам, наше внимание все равно уделяется. Мы постоянно погружаемся в себя, и это погружение привело к новым способам фокусировки внимания и привлечения нашего внимания.
Мы постоянно погружаемся в себя, и это погружение привело к новым способам фокусировки внимания и привлечения нашего внимания.Мне было любопытно, однако, это новое поколение или поколение Z
7 (год рождения 1993-2005), как оно было придумано, с рождения было окружено большим объемом технологий, поэтому с тех пор у нас есть наши структуры внимания изменены? По словам Энтони Тернера, автора книги «Поколение Z: технологии и социальные интересы». 8 , ответ положительный. Тернер утверждает, что «Часы просмотра телевизора у детей в возрасте 1-3 лет связаны с высоким риском (10%) проблем с вниманием в возрасте 7 лет» (110) 9 . Таким образом, наше внимание формируется не телевидением, а социальными сетями. Теперь мы не можем отделить социальные сети от телевидения, и эта интеграция привела к более разделённому вниманию не только между платформами, но и между типами СМИ. Возможно, мы никогда не узнаем, какими могут быть наши структуры внимания из-за этой обусловленности обществом и постоянной потребности в интеграции социальных сетей с технологиями.
Чтобы двигаться дальше, не требуя моего внимания сообщениями знаменитостей в The Shaderoom
10 , или необходимость участвовать в явном меме, которым, как мне казалось, нужно было поделиться, или чувство ответственности, которое я чувствовал, чтобы уделить внимание разговору из-за страха 11 ; Я смог сосредоточиться на окружающем мире, равномерно распределить свое внимание и открыть свой разум для того, чтобы обращать внимание не только на то, что мне было представлено, но и на то, что я видел, что требовало моего внимания. Это отключение, хотя и короткое, позволяет мне переучивать себя, чтобы сосредоточить свое внимание, стать менее «отсутствующим присутствием» — термин, введенный Тернером. Отсутствие в присутствии означало, что человек находился в одном месте физически, но в другом социально. Теперь я стал присутствовать во всех аспектах своей жизни; разговоры больше не пропускали информацию, потому что я мысленно был где-то в другом месте.По словам Жана-Себастьяна Шуинара из Adviso, это общий аспект гиперконнективности.
 В своей статье «Когда гиперподключение ведет к социальному отчуждению» 12 он утверждает, что из-за нашего постоянного внимания в Интернете мы потеряли способность обращать внимание на окружающий мир. Это также привело к тому, что мы потеряли нашу личность, потому что без наших социальных сетей и нашего внимания, уделяемого им, мы становимся такими, какими он ничего не сказал. Он вводит термин ДЖОМО или «Радость упущенного» 9.0016 13 по сути, это радость быть частью моментов вокруг нас. Чтобы обратить внимание на нашу реальную жизнь и найти место в нашей социальной онлайн-жизни. Тернер, Шуинар и я благодаря «Signed Off» смогли понять внимание за пределами социальных сетей и понять, что мы должны приучить себя уделять внимание различным другим аспектам жизни, помимо сайтов социальных сетей.
В своей статье «Когда гиперподключение ведет к социальному отчуждению» 12 он утверждает, что из-за нашего постоянного внимания в Интернете мы потеряли способность обращать внимание на окружающий мир. Это также привело к тому, что мы потеряли нашу личность, потому что без наших социальных сетей и нашего внимания, уделяемого им, мы становимся такими, какими он ничего не сказал. Он вводит термин ДЖОМО или «Радость упущенного» 9.0016 13 по сути, это радость быть частью моментов вокруг нас. Чтобы обратить внимание на нашу реальную жизнь и найти место в нашей социальной онлайн-жизни. Тернер, Шуинар и я благодаря «Signed Off» смогли понять внимание за пределами социальных сетей и понять, что мы должны приучить себя уделять внимание различным другим аспектам жизни, помимо сайтов социальных сетей.- (Фото из цифрового дневника «Подписано»)
После отключения я смог измерить свой трек внимания и то, как теряется мое время. Без социальных сетей я мог уделять или уделять больше внимания одной задаче за раз.
 Я стал более эффективным и гораздо больше инвестировал и осознавал то, что я делаю. Работа, которая привлекла бы мое разделенное внимание, теперь была посвящена. В моем блоге «Внимание, внимание, внимание» 14 , компании Digital-Dairy, ключевого компонента эксперимента, я обратил внимание на тот факт, что теперь мое внимание было сосредоточено на окружающем мире. Я больше не проверял ленту с 5-минутными интервалами, чтобы увидеть обновления, а сознательно замечал и сосредотачивался на том, что я делал и что меня окружало (см. также: Новые начинания 15 ).
Я стал более эффективным и гораздо больше инвестировал и осознавал то, что я делаю. Работа, которая привлекла бы мое разделенное внимание, теперь была посвящена. В моем блоге «Внимание, внимание, внимание» 14 , компании Digital-Dairy, ключевого компонента эксперимента, я обратил внимание на тот факт, что теперь мое внимание было сосредоточено на окружающем мире. Я больше не проверял ленту с 5-минутными интервалами, чтобы увидеть обновления, а сознательно замечал и сосредотачивался на том, что я делал и что меня окружало (см. также: Новые начинания 15 ).Друзья Фила Дунски
Сделав несколько шагов назад, я знал, когда начал этот эксперимент, что, конечно же, мое внимание будет смещено из-за того, что я вырезал большую часть того, на чем я сосредотачиваюсь больше всего. мое внимание, однако, чего я не ожидал, так это того, как мое внимание расширилось как по охвату, так и по стимулам. Часто в социальных сетях я сосредотачивался на нескольких вещах — вещах, которые я нахожу интересными, которые часто уходят от моего постоянного частичного внимания к полному в считанные минуты.
 Будучи поколением, которое выросло с таким количеством легкодоступных технологий, для нас стало в некотором роде врожденным постоянное частичное внимание. Это означает, что мы «постоянно, но частично обращаемся к информации, поступающей от наших коммуникационных устройств…» (Джонс, Хафнер, 82) 9.0016 16 . Эта непрерывная структура частичного внимания позволила нам переключаться с одной активности (переключение приведения) и уделять внимание двум важным активациям при переключении туда и обратно (двойная активность). Тернер объяснил бы, как постоянное частичное внимание привело к тому, что он называет «полной занятостью ничем, пытаясь уследить за всем — неэффективный и очень напряженный процесс». (111) 17 .
Будучи поколением, которое выросло с таким количеством легкодоступных технологий, для нас стало в некотором роде врожденным постоянное частичное внимание. Это означает, что мы «постоянно, но частично обращаемся к информации, поступающей от наших коммуникационных устройств…» (Джонс, Хафнер, 82) 9.0016 16 . Эта непрерывная структура частичного внимания позволила нам переключаться с одной активности (переключение приведения) и уделять внимание двум важным активациям при переключении туда и обратно (двойная активность). Тернер объяснил бы, как постоянное частичное внимание привело к тому, что он называет «полной занятостью ничем, пытаясь уследить за всем — неэффективный и очень напряженный процесс». (111) 17 .
Скриншот из книги Энтони Тернера «Поколение Z: технологии и социальные интересы»
- Кофейня Фила Дански
Благодаря этим новым способам концентрации нашего внимания многие сайты социальных сетей и их пользователи стали проявлять творческий подход к способам привлечения нашего внимания.
 Экономика внимания была развита там, где существует ценность, создаваемая обменом вниманием, переопределением хэштега, который теперь обеспечивает избирательное внимание и призывает к прямому требованию внимания, «@», который уделяет явное внимание человеку, месту, или вещь, не говоря уже о множестве творческих выходов, которые открыты, чтобы привлечь наше внимание в течение нескольких часов. Маркетинговые стратегии 18 возникли, чтобы помочь пользователям и администраторам сайтов не только влиять на внимание, но и привлекать внимание. Например, Vine 19 с их 6-секундным ограничением на видео позволяет нам уделять внимание не только созданию, но и потреблению огромного количества видео, не осознавая, сколько внимания мы уделяем сообществу. Не стоит забывать и об аспекте ленты, который есть на всех социальных сайтах, который включает в себя разнообразную информацию и средства массовой информации, которые могут вести нас в любом направлении. Наконец, идея о том, что внимание часто привлекается глупыми, жестокими и провокационными сообщениями , большинство пользователей часто практикуют такое поведение для достижения трендовых стандартов, а также популярности.
Экономика внимания была развита там, где существует ценность, создаваемая обменом вниманием, переопределением хэштега, который теперь обеспечивает избирательное внимание и призывает к прямому требованию внимания, «@», который уделяет явное внимание человеку, месту, или вещь, не говоря уже о множестве творческих выходов, которые открыты, чтобы привлечь наше внимание в течение нескольких часов. Маркетинговые стратегии 18 возникли, чтобы помочь пользователям и администраторам сайтов не только влиять на внимание, но и привлекать внимание. Например, Vine 19 с их 6-секундным ограничением на видео позволяет нам уделять внимание не только созданию, но и потреблению огромного количества видео, не осознавая, сколько внимания мы уделяем сообществу. Не стоит забывать и об аспекте ленты, который есть на всех социальных сайтах, который включает в себя разнообразную информацию и средства массовой информации, которые могут вести нас в любом направлении. Наконец, идея о том, что внимание часто привлекается глупыми, жестокими и провокационными сообщениями , большинство пользователей часто практикуют такое поведение для достижения трендовых стандартов, а также популярности.
Структуры внимания напрямую зависят от социальных сетей, потому что социальные сети создали способы, с помощью которых информация в различных средах сужается, чтобы предложить суть истории. Наше внимание больше не наделено способностью расти в смысле охвата. Мы вынуждены отдавать предпочтение более коротким и лаконичным работам, в которых воплощается и все событие. Наше внимание окупается, потому что мы застреваем на своем пути из-за хэштегов каналов и других побочных продуктов, создаваемых социальными сетями. Наше воображение, человеческое любопытство и креативность стали ограниченными, потому что мы обращаем внимание на несколько источников информации, потому что их отсутствие включено или принято некоторыми хэштегами. Звуки, которые мы слышим, и лица, которые мы видим, искажаются нашим присутствием в социальных сетях. Мы смотрим вверх и быстро возвращаемся к нашей опосредованной жизни.
Все эти силы создают студентов, участников дискуссионного сообщества и читателей, у которых снижена способность к более активным структурам внимания, потому что, хотя мы занимаемся столь многими видами деятельности, вынос меньше, а конечные продукты уже.
 Для всех, кто наткнется на этот пост, я надеюсь, что вы найдете время, чтобы отключиться и обратить свое внимание на нечто большее, чем просто то, что представлено вам в опосредованном формате, которым оно является. Социальные сети — это отличная возможность для нашего технологически подкованного мира, но время и внимание, уделяемые внешнему миру, позволяют нам создавать структуры нашего внимания, чтобы затем применять их к нашим средствам массовой информации. Этот порядок позволяет нам восстановить больше нашего познания, а также нашу способность суждения.
Для всех, кто наткнется на этот пост, я надеюсь, что вы найдете время, чтобы отключиться и обратить свое внимание на нечто большее, чем просто то, что представлено вам в опосредованном формате, которым оно является. Социальные сети — это отличная возможность для нашего технологически подкованного мира, но время и внимание, уделяемые внешнему миру, позволяют нам создавать структуры нашего внимания, чтобы затем применять их к нашим средствам массовой информации. Этот порядок позволяет нам восстановить больше нашего познания, а также нашу способность суждения.Процитированные источники:
1| Джонс Х. Родни, Хафнер. A Christopher (nd) In Facebook [Страница книги] Получено 17 ноября 2015 г. с https://www.facebook.com/UnderstandingDigitalLiteracies/info/?tab=page_info 2| Джонс Х. Родни, Хафнер. А. Кристофер, «Структуры внимания» в Understanding Digital Literacities ( New York: Routledge, 2012) 87 3| Джонс Х. Родни, Ханфер. А. Кристофер, «Структуры внимания» в Understanding Digital Literacities ( New York: Routledge, 2012) 87 4| Орландо, Дж. Чарльз. «Внимание, модели из Instagram: вы продаете себя» Проблема женщин в мужчинах. 20 февраля 2015 г. Интернет. 5 декабря 2015 г. 5| Twitter (nd) В Twitter [О странице]. Получено 7 декабря 2015 г. с https://about.twitter.com/moments 6 | Джонс Х. Родни, Хафнер. А. Кристофер, «Структуры внимания» в Понимание цифровой грамотности ( Нью-Йорк: Routledge, 2012) 85 7| Уильямс, Алекс. «Подвиньтесь, миллениалы, приходит поколение Z» Нью-Йорк TImes [Нью-Йорк] 18 сентября 2015 г. Мода и стиль. Интернет. 8| Тернер, Энтони. «Поколение Z: технологии и социальные интересы». Журнал индивидуальной психологии (2015): 103-113. Веб. 9| Тернер, Энтони.
Родни, Ханфер. А. Кристофер, «Структуры внимания» в Understanding Digital Literacities ( New York: Routledge, 2012) 87 4| Орландо, Дж. Чарльз. «Внимание, модели из Instagram: вы продаете себя» Проблема женщин в мужчинах. 20 февраля 2015 г. Интернет. 5 декабря 2015 г. 5| Twitter (nd) В Twitter [О странице]. Получено 7 декабря 2015 г. с https://about.twitter.com/moments 6 | Джонс Х. Родни, Хафнер. А. Кристофер, «Структуры внимания» в Понимание цифровой грамотности ( Нью-Йорк: Routledge, 2012) 85 7| Уильямс, Алекс. «Подвиньтесь, миллениалы, приходит поколение Z» Нью-Йорк TImes [Нью-Йорк] 18 сентября 2015 г. Мода и стиль. Интернет. 8| Тернер, Энтони. «Поколение Z: технологии и социальные интересы». Журнал индивидуальной психологии (2015): 103-113. Веб. 9| Тернер, Энтони. «Поколение Z: технологии и социальные интересы». Журнал индивидуальной психологии (2015): 103-113. Веб. 10| Энджи. Комната теней . н/д н/д 2013. Интернет. 20 ноября 2015 г. 11| Дыкман, апрель. «Страх пропустить». Forbes.com 01 марта 2012 г. Личные финансы. сеть. 21 ноября 2015 г. 12| Шуинар, Жан-Себастьян. «Когда гиперсвязность приводит к общественному вниманию» Adviso.com. 20 февраля 2013 г. н/д. сеть. 28 ноября 2015 г. 13| Шуинар, Жан-Себастьян. «Когда гиперсвязность приводит к общественному вниманию» Adviso.com. 20 февраля 2013 г. н/д. сеть. 28 ноября 2015 г. 14| Раджа, Мэрайя. «Подписаноoffblog.com». 27 ноября 2015 г. Внимание Внимание Внимание. Интернет. 15 декабря 2015 г. 15| Раджа, Мэрайя. «Подписаноoffblog.com». 20 ноября 2015 г. Новые начинания .
«Поколение Z: технологии и социальные интересы». Журнал индивидуальной психологии (2015): 103-113. Веб. 10| Энджи. Комната теней . н/д н/д 2013. Интернет. 20 ноября 2015 г. 11| Дыкман, апрель. «Страх пропустить». Forbes.com 01 марта 2012 г. Личные финансы. сеть. 21 ноября 2015 г. 12| Шуинар, Жан-Себастьян. «Когда гиперсвязность приводит к общественному вниманию» Adviso.com. 20 февраля 2013 г. н/д. сеть. 28 ноября 2015 г. 13| Шуинар, Жан-Себастьян. «Когда гиперсвязность приводит к общественному вниманию» Adviso.com. 20 февраля 2013 г. н/д. сеть. 28 ноября 2015 г. 14| Раджа, Мэрайя. «Подписаноoffblog.com». 27 ноября 2015 г. Внимание Внимание Внимание. Интернет. 15 декабря 2015 г. 15| Раджа, Мэрайя. «Подписаноoffblog.com». 20 ноября 2015 г. Новые начинания . Интернет. 15 декабря 2015 г. 16| Джонс Х. Родни, Хафнер. А. Кристофер, «Структуры внимания» в Understanding Digital Literacities ( New York: Routledge, 2012) 82 17| Тернер, Энтони. «Поколение Z: технологии и социальные интересы». Журнал индивидуальной психологии (2015): 103-113. Веб.
Интернет. 15 декабря 2015 г. 16| Джонс Х. Родни, Хафнер. А. Кристофер, «Структуры внимания» в Understanding Digital Literacities ( New York: Routledge, 2012) 82 17| Тернер, Энтони. «Поколение Z: технологии и социальные интересы». Журнал индивидуальной психологии (2015): 103-113. Веб.Трансформеры с визуальным объяснением (часть 3): мультиголовное внимание, глубокое погружение | Кетан Доши
СЕРИЯ ИНТУИТИВНЫХ ТРАНСФОРМАТОРОВ НЛП
Нежное руководство по внутренней работе само-внимания, внимания кодировщика-декодера, оценки внимания и маскировки, на простом английском языке.
Опубликовано в·
Чтение: 11 мин.·
17 января 2021 г.Это третья статья из моей серии о Трансформерах. Мы покрываем его функциональность сверху вниз. В предыдущих статьях мы узнали, что такое Transformer, его архитектура и принцип работы.
В этой статье мы сделаем еще один шаг и погрузимся глубже в Multi-head Attention, который является мозгом Transformer.
Вот краткий обзор предыдущей и следующей статей этой серии. Моя цель будет заключаться в том, чтобы понять не только то, как что-то работает, но и почему это работает именно так.
- Обзор функциональных возможностей (Как используются трансформеры и почему они лучше RNN. Компоненты архитектуры и поведение во время обучения и вывода)
- Как это работает (Внутреннее сквозное функционирование. Как потоки данных и выполняемые вычисления, включая матричные представления)
- Multi-head Attention — эта статья (внутренняя работа модуля Attention в Transformer)
- Почему внимание повышает производительность (Не только то, что делает внимание, но и почему оно работает так хорошо. Как внимание фиксирует отношения между словами в предложении)
И если вас интересуют приложения НЛП в целом, я некоторые другие статьи, которые могут вам понравиться.
- Поиск луча (Алгоритм, обычно используемый приложениями преобразования речи в текст и НЛП для улучшения предсказаний)
- Оценка по Блю ( Оценка по Блю и Частота ошибок в словах — две важные метрики для моделей НЛП )
Как мы обсуждали в Части 2, Внимание используется в Преобразователе в трех местах:
- Само-внимание в Кодировщике — входная последовательность обращает внимание на себя
- Само-внимание в Декодере — цель последовательность обращает внимание на себя
- Кодер-декодер-внимание в Декодере — целевая последовательность обращает внимание на входную последовательность
Внимание Входные параметры — запрос, ключ и значение
Слой «Внимание» принимает входные данные в виде трех параметров, известных как «Запрос», «Ключ» и «Значение».
Все три параметра схожи по структуре, каждое слово в последовательности представлено вектором.
Самостоятельное внимание кодировщика
Входная последовательность подается на входной кодировщик и кодировщик положения, который создает закодированное представление для каждого слова во входной последовательности, которое фиксирует значение и положение каждого слова. Это подается ко всем трем параметрам: Запрос, Ключ и Значение в Самостоятельном внимании в первом кодировщике, который затем также создает закодированное представление для каждого слова во входной последовательности, которое теперь также включает оценки внимания для каждого слова. Когда это проходит через все кодировщики в стеке, каждый модуль самоконтроля также добавляет свои собственные оценки внимания к представлению каждого слова.
(Изображение автора)Самостоятельное внимание декодера
Поступая в стек декодера, целевая последовательность подается на выходное встраивание и кодирование позиции, которое создает закодированное представление для каждого слова в целевой последовательности, которое фиксирует значение и положение каждого слова. Это подается на все три параметра: Запрос, Ключ и Значение в Самостоятельном внимании в первом декодере, который затем также создает закодированное представление для каждого слова в целевой последовательности, которая теперь также включает оценки внимания для каждого слова.
Это подается на все три параметра: Запрос, Ключ и Значение в Самостоятельном внимании в первом декодере, который затем также создает закодированное представление для каждого слова в целевой последовательности, которая теперь также включает оценки внимания для каждого слова.
После прохождения Layer Norm это подается в параметр Query в Encoder-Decoder Attention в первом Decoder
Encoder-Decoder Attention
Наряду с этим вывод последнего Encoder в стеке передается параметрам Value и Key в Encoder-Decoder Внимание.
Внимание Кодера-Декодера, таким образом, получает представление как целевой последовательности (от Само-Внимания Декодера), так и представление входной последовательности (из стека Кодировщика). Таким образом, он создает представление с оценками внимания для каждого слова целевой последовательности, которое также фиксирует влияние оценок внимания из входной последовательности.
Когда это проходит через все декодеры в стеке, каждое внимание к самому себе и каждое внимание кодировщика-декодера также добавляют свои собственные оценки внимания к представлению каждого слова.
В Transformer модуль Attention повторяет свои вычисления несколько раз параллельно. Каждая из них называется головкой внимания. Модуль «Внимание» разбивает свои параметры «Запрос», «Ключ» и «Значение» на N раз и пропускает каждое разделение независимо через отдельный заголовок. Все эти аналогичные расчеты внимания затем объединяются вместе, чтобы получить окончательный показатель внимания. Это называется многоголовым вниманием и дает Преобразователю больше возможностей для кодирования нескольких взаимосвязей и нюансов для каждого слова.
(Изображение автора)Чтобы точно понять, как данные обрабатываются внутри, давайте рассмотрим работу модуля «Внимание», пока мы обучаем Преобразователь решать задачу перевода. Мы будем использовать один образец наших обучающих данных, который состоит из входной последовательности («Добро пожаловать» на английском языке) и целевой последовательности («De nada» на испанском языке).
Есть три гиперпараметра, которые определяют размерность данных:
- Размер встраивания — ширина вектора встраивания (в нашем примере мы используем ширину 6).
 Этот размер перенесен во всю модель Transformer и, следовательно, иногда упоминается другими именами, такими как «размер модели» и т. д.
Этот размер перенесен во всю модель Transformer и, следовательно, иногда упоминается другими именами, такими как «размер модели» и т. д. - Размер запроса (равный размеру ключа и значения) — размер весов, используемых тремя линейными слоями для создания матриц запроса, ключа и значения соответственно (в нашем примере мы используем размер запроса, равный 3)
- Количество Внимание головки (в нашем примере мы используем 2 головки)
Кроме того, у нас также есть размер партии, что дает нам одно измерение для количества образцов.
Слои входного внедрения и кодирования позиции создают матрицу формы (количество выборок, длина последовательности, размер внедрения), которая передается в запрос, ключ и значение первого кодировщика в стеке.
(Изображение автора)Чтобы упростить визуализацию, мы удалим параметр «Пакетная обработка» на наших рисунках и сосредоточимся на остальных измерениях.
(Изображение автора) Существует три отдельных линейных слоя для запроса, ключа и значения. Каждый линейный слой имеет свои веса. Входные данные проходят через эти линейные слои для создания матриц Q, K и V.
Каждый линейный слой имеет свои веса. Входные данные проходят через эти линейные слои для создания матриц Q, K и V.
Теперь данные распределяются между несколькими головками Attention, чтобы каждая из них могла обрабатывать их независимо.
Однако важно понимать, что это только логическое разделение. Query, Key и Value физически не разделены на отдельные матрицы, по одной для каждой головки Attention. Единая матрица данных используется для запроса, ключа и значения, соответственно, с логически отдельными разделами матрицы для каждой главы «Внимание». Точно так же нет отдельных линейных слоев, по одному для каждой головы внимания. Все головки внимания используют один и тот же линейный слой, но просто работают со своим «собственным» логическим разделом матрицы данных.
Веса линейного слоя логически разделены по головкам
Это логическое разделение осуществляется путем равномерного разделения входных данных, а также весов линейного слоя по головкам Attention. Мы можем добиться этого, выбрав Размер запроса, как показано ниже:
Мы можем добиться этого, выбрав Размер запроса, как показано ниже:
Размер запроса = Размер встраивания / Количество головок
(Изображение автора)В нашем примере именно поэтому Размер запроса = 6/2 = 3. Даже хотя вес слоя (и входные данные) представляет собой единую матрицу, мы можем думать о ней как о «суммировании» отдельных весов слоев для каждой головы.
(Изображение автора)Таким образом, вычисления для всех головок могут быть выполнены с помощью одной матричной операции, а не N отдельных операций. Это делает вычисления более эффективными и сохраняет простоту модели, поскольку требуется меньше линейных слоев, но при этом достигается мощность независимых головок внимания.
Изменение формы матриц Q, K и V
Матрицы Q, K и V, выдаваемые линейными слоями, изменены для включения явного измерения головы. Теперь каждый «срез» соответствует матрице на голову.
Эта матрица снова изменена путем замены измерений Head и Sequence.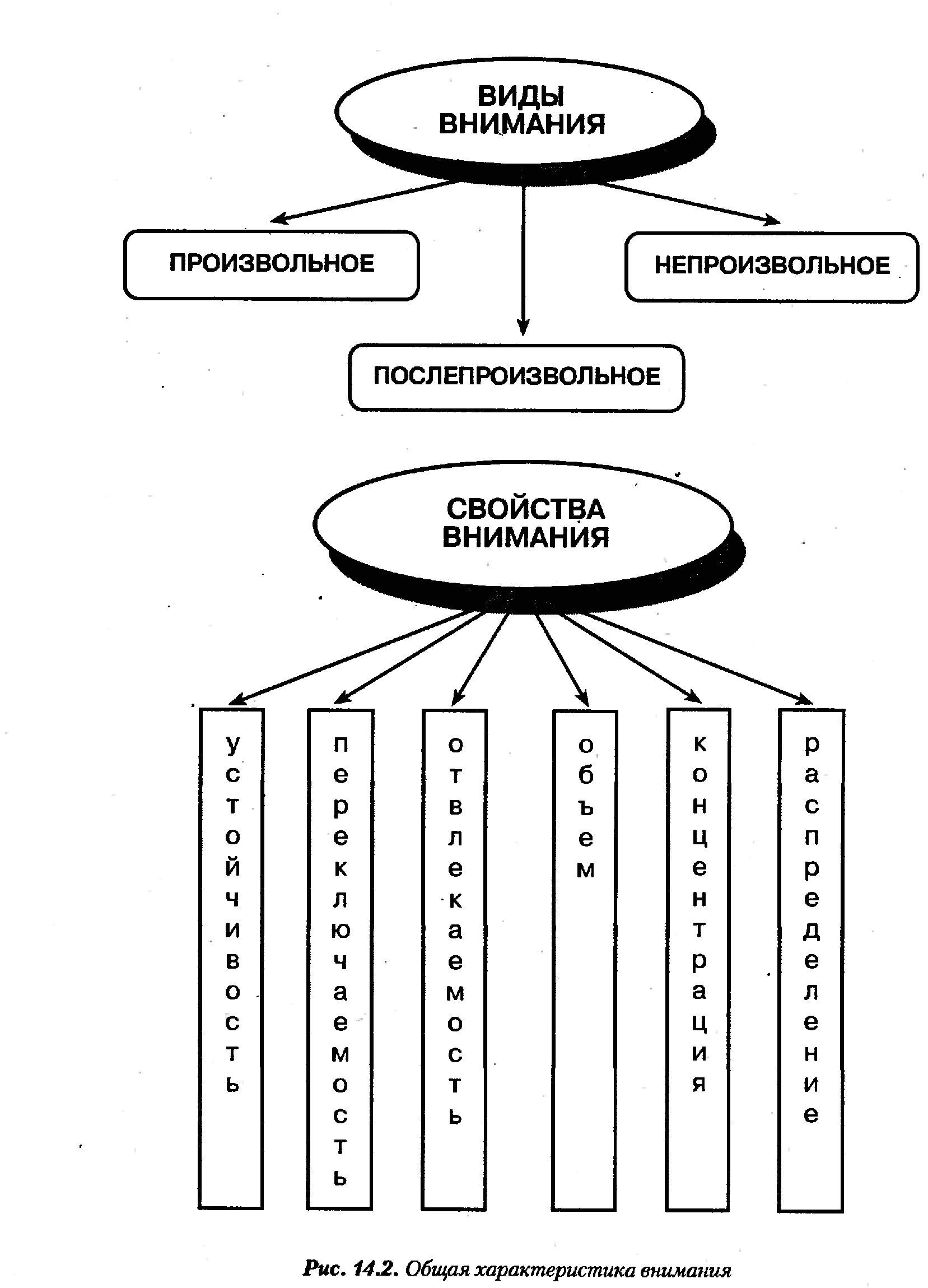 Несмотря на то, что измерение «Пакетная обработка» не отображается, размеры Q теперь равны (Пакетная обработка, Головка, Последовательность, Размер запроса).
Несмотря на то, что измерение «Пакетная обработка» не отображается, размеры Q теперь равны (Пакетная обработка, Головка, Последовательность, Размер запроса).
На картинке ниже мы можем видеть полный процесс разделения нашего примера Q-матрицы после выхода из линейного слоя.
Последний этап предназначен только для визуализации — хотя Q-матрица представляет собой единую матрицу, мы можем думать о ней как о логически отдельной Q-матрице для каждой головы.
Матрица Q, разделенная по головам внимания (изображение автора)Мы готовы вычислить показатель внимания.
Теперь у нас есть 3 матрицы Q, K и V, разделенные по головкам. Они используются для расчета оценки внимания.
Мы покажем расчеты для одной головки, используя только два последних измерения (размер последовательности и запроса) и пропустим первые два измерения (партия и головка).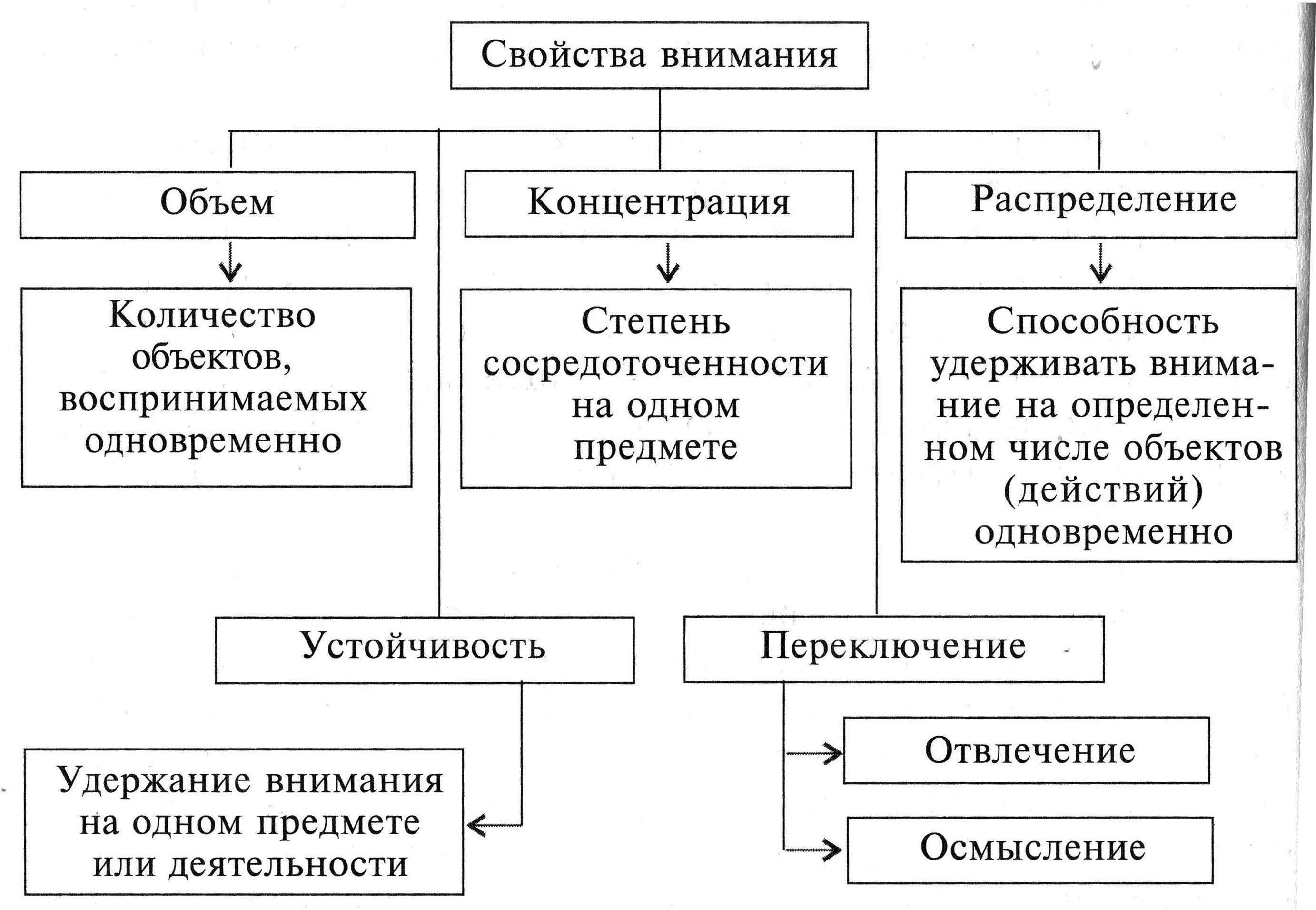 По сути, мы можем представить, что рассматриваемые нами вычисления «повторяются» для каждой головки и для каждого образца в партии (хотя, очевидно, они происходят как одна матричная операция, а не как цикл).
По сути, мы можем представить, что рассматриваемые нами вычисления «повторяются» для каждой головки и для каждого образца в партии (хотя, очевидно, они происходят как одна матричная операция, а не как цикл).
Первым шагом является матричное умножение между Q и K.
(Изображение автора)Значение маски теперь добавляется к результату. В Самостоятельном внимании кодировщика маска используется для маскировки значений заполнения, чтобы они не участвовали в оценке внимания.
Различные маски применяются в само-внимании декодера и во внимании декодера-энкодера, к которым мы вернемся чуть позже.
(Изображение автора)Теперь результат масштабируется путем деления на квадратный корень из размера запроса, а затем к нему применяется Softmax.
(Изображение автора)Другое матричное умножение выполняется между выходом Softmax и матрицей V.
(Изображение автора)Полный расчет оценки внимания в кодировщике Самовнимания выглядит следующим образом:
(Изображение автора) Теперь у нас есть отдельные оценки внимания для каждой головы, которые необходимо объединить в одну оценку. Эта операция слияния, по существу, обратна операции разделения.
Эта операция слияния, по существу, обратна операции разделения.
Это делается путем простого изменения формы матрицы результатов, чтобы исключить размер головы. Шаги:
- Измените форму матрицы оценки внимания, поменяв местами измерения Head и Sequence. Другими словами, форма матрицы меняется от (Пакет, Головка, Последовательность, Размер запроса) к (Пакет, Последовательность, Головка, Размер запроса).
- Сверните измерение Head, изменив форму на (Пакет, Последовательность, Голова * Размер запроса). Это эффективно объединяет векторы оценки внимания для каждой головы в единую объединенную оценку внимания.
Поскольку размер внедрения = размер заголовка * размер запроса, объединенная оценка равна (пакет, последовательность, размер внедрения). На рисунке ниже мы можем увидеть полный процесс слияния для примера матрицы Score.
(Изображение автора)Если сложить все вместе, это сквозной поток Многоголового Внимания.
(Изображение автора) Вектор встраивания фиксирует значение слова. В случае Multi-head Attention, как мы видели, векторы встраивания для входной (и целевой) последовательности логически распределяются между несколькими головками. Каково значение этого?
В случае Multi-head Attention, как мы видели, векторы встраивания для входной (и целевой) последовательности логически распределяются между несколькими головками. Каково значение этого?
Это означает, что отдельные разделы встраивания могут изучать различные аспекты значения каждого слова, поскольку оно связано с другими словами в последовательности. Это позволяет Transformer захватывать более богатые интерпретации последовательности.
Возможно, это не реалистичный пример, но он может помочь развить интуицию. Например, один раздел может отражать «гендерность» (мужской, женский, средний род) существительного, а другой может отражать «количество элементов» (единственное или множественное число) существительного. Это может быть важно при переводе, потому что во многих языках глагол, который необходимо использовать, зависит от этих факторов.
Само-внимание декодера работает так же, как само-внимание кодировщика, за исключением того, что оно работает с каждым словом целевой последовательности.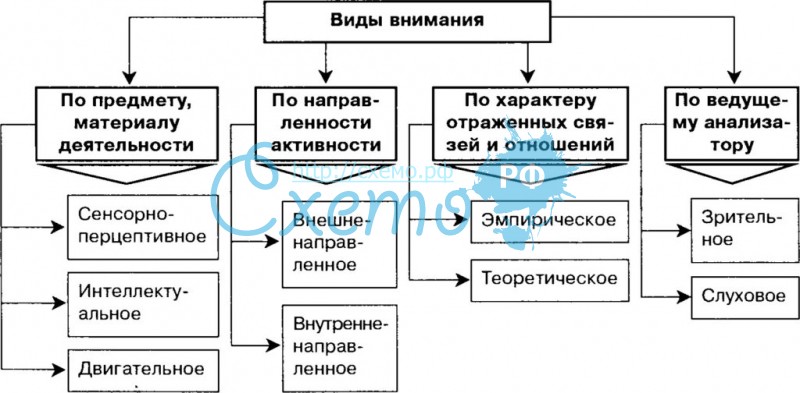
Точно так же маскирование маскирует слова заполнения в целевой последовательности.
Кодер-декодер Внимание получает входные данные из двух источников. Таким образом, в отличие от внутреннего внимания кодировщика, которое вычисляет взаимодействие между каждым входным словом с другими входными словами, и внутреннего внимания декодера, которое вычисляет взаимодействие между каждым целевым словом с другими целевыми словами, внимание кодировщика-декодера вычисляет взаимодействие между каждым входным словом. целевое слово с каждым входным словом.
(Изображение автора)Таким образом, каждая ячейка в результирующей оценке внимания соответствует взаимодействию между одним Q (т. е. словом целевой последовательности) со всеми другими K (т. е. входной последовательностью) словами и всеми V (т. е. входной последовательностью) словами .
Аналогично, Маскирование маскирует более поздние слова в целевом выводе, как было подробно объяснено во второй статье серии.
Надеюсь, это дало вам хорошее представление о том, что делают модули Attention в Transformer. В сочетании со сквозным потоком Transformer в целом, который мы рассмотрели во второй статье, мы теперь подробно рассмотрели работу всей архитектуры Transformer.
Теперь мы точно понимаем, что делает Трансформер. Но мы так и не ответили полностью на вопрос , почему Внимание Трансформера выполняет те расчеты, которые он делает. Почему он использует понятия запроса, ключа и значения и почему он выполняет умножение матриц, которое мы только что видели?
У нас есть смутное интуитивное представление о том, что он «фиксирует отношения между каждым словом друг с другом», но что именно это означает? Как именно это дает Вниманию Преобразователя способность понимать нюансы каждого слова в последовательности?
Это интересный вопрос, которому посвящена последняя статья этой серии. Как только мы узнаем это, мы по-настоящему поймем элегантность архитектуры Transformer.
